Amazon Web Services ブログ
Category: Amazon CloudWatch

AWS X-Ray SDK / Daemon の OpenTelemetry への移行
AWS X-Ray SDKとDaemonは2026年2月にメンテナンスモードへ移行します。今後のトレース計装にはOpenTelemetryが推奨されます。本記事では移行の背景、スケジュール、移行先の選択肢、新機能について解説します。
Amazon CloudWatch で OpenTelemetry と PromQL がサポートされました
Amazon CloudWatch で OpenTelemetry メトリクスのネイティブ取り込みと PromQL クエリがサポートされました。メトリクスあたり最大 150 ラベルの高カーディナリティメトリクスストアにより、Kubernetes やマイクロサービスのラベルの多いメトリクスを変換なしで CloudWatch に直接送信できます。AWS リソースの自動エンリッチメントと組み合わせることで、インフラストラクチャ、コンテナ、アプリケーションのメトリクスを一元管理し、PromQL でクエリできるようになります。
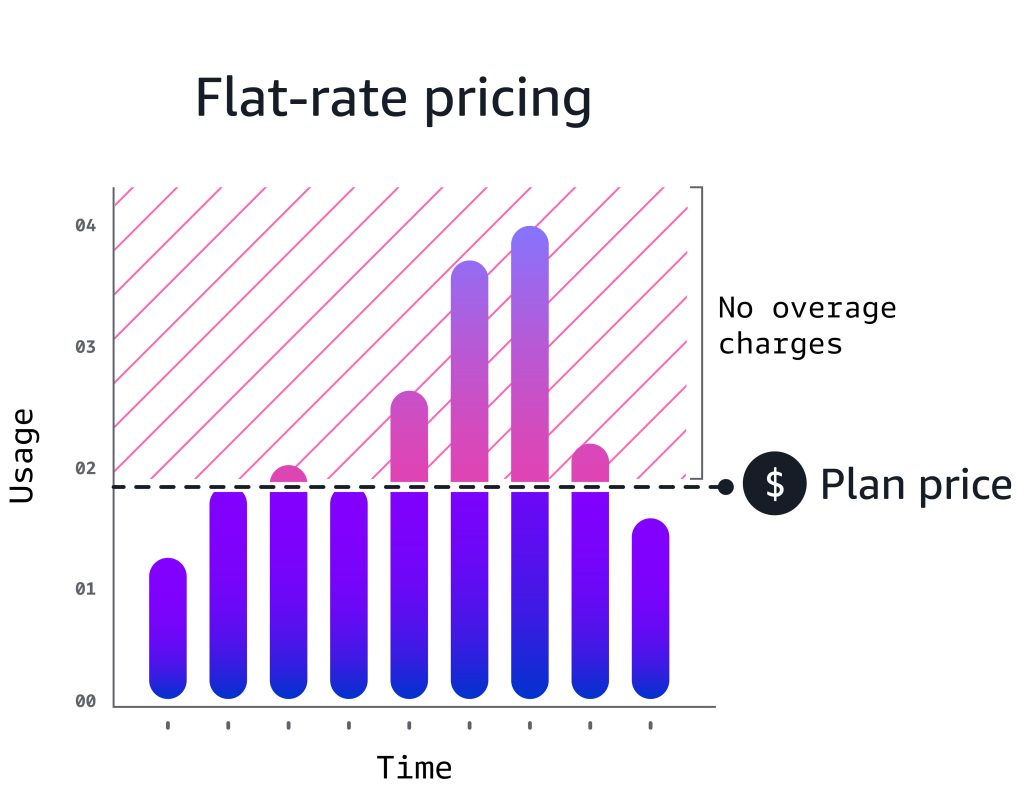
Amazon CloudFront 定額料金プラン:新機能と対応機能の拡大
Amazon CloudFront は定額料金プランのリリース以降、お客様からいただいたフィードバックをもとに新しい機能を追加してきました。この記事では、 Lambda@Edge のサポート、 CAPTCHA 、相互 TLS (mTLS) 、そして AI ボットやエージェントのトラフィックを可視化する AI アクティビティダッシュボードなど、最新の追加機能をご紹介します。また、使用量の上限を超えたトラフィックの扱いについても明確化しています。

AWS Weekly Roundup: Amazon Bedrock での NVIDIA Nemotron 3 Super、Nova Forge SDK、Amazon Corretto 26 など (2026 年 3 月 23 日)
こんにちは! 今回初めて AWS Weekly Roundup を担当する Daniel Abib です。私は […]

CloudWatch アラームを使用した Amazon MSK の本番環境向けモニタリングの設定
本記事では、Amazon CloudWatch を使用した Amazon MSK クラスターの本番環境向けモニタリングの設定方法を解説します。ブローカーの健全性、リソース使用率、コンシューマーラグなどの主要メトリクスのカテゴリ分類と、推奨される CloudWatch アラームのしきい値を紹介し、ストリーミングワークロードの問題を早期に検知するためのプラクティスを説明します。

First Byte Latency の時間計測と Server-Timing ヘッダーを用いて、ウェブサイトのパフォーマンスのボトルネックを特定する方法
ウェブサイトのパフォーマンス問題はよくあることですが、根本原因の特定は困難な作業となります。この投稿では、 Server-Timing ヘッダーの潜在能力を引き出すことで、パフォーマンスに関するトラブルシューティングのプロセスをシンプルにする方法を学びます。 Server-Timing ヘッダーは、バックエンドのコンポーネントがユーザーリクエストへのレスポンスにおいて、タイミングメトリクスやパフォーマンスモニタリングに関するインサイトを伝達できるようにします。

Amazon OpenSearch Ingestion 101: 主要メトリクスに対する CloudWatch アラームの設定
Amazon OpenSearch Ingestion パイプラインの主要メトリクスに対する Amazon CloudWatch アラームの設定方法を解説します。Source、Processor、Sink、Buffer の各コンポーネントのアラームメトリクスと、パイプラインのレイテンシー低減やドキュメントエラー解決のシナリオを紹介します。

Amazon CloudWatch からテレメトリデータを取得する:ログ編
Amazon CloudWatch Logs は AWS 環境におけるログ管理の中心的なサービスとして、様々な […]

Amazon CloudWatch からテレメトリデータを取得する:メトリクス編
CloudWatch メトリクスを活用することで、システムの状態を可視化し効果的な監視を実現できます。 Clo […]

AWS Weekly Roundup: Amazon EC2 G7e インスタンス、Amazon Corretto 更新など (2026 年 1 月 26 日)
こんにちは! 私にとって 2026 年最初の記事になるこの記事は、家の前の雪に埋まった車道が掘り起こされるのを […]