Amazon Web Services ブログ

AWS Summit Japan 2025 製造ブース:産業データファブリック(IDF)の展示紹介
みなさん、こんにちは。製造業のお客様を中心に技術支援をしているソリューションアーキテクトの塚井です。 2025 […]

週刊AWS – 2025/7/21週
Amazon Braket が IQM の新しい 54 量子ビット量子プロセッサを追加、Amazon MQ が RabbitMQ 向けに Graviton3 ベースの M7g インスタンスをサポート開始、Amazon RDS for PostgreSQL と Amazon Redshift のゼロ ETL 統合が一般提供開始、AWS Glue が Microsoft Dynamics 365 をデータソースとしてサポート開始、AWS HealthOmics がワークフロー作成のためのサードパーティ Git リポジトリサポートを導入など

Amazon Connect の Customer Profiles と Outbound Campaigns によるプロアクティブなコミュニケーション
顧客との双方向コミュニケーションは強固な関係構築の礎となります。プロアクティブな顧客へのアプローチによってカスタマーエクスペリエンスを更に向上させることができますが、組織は適切なメッセージを、適切な人に、適切なタイミングで送信する必要があります。Amazon Connectにより、組織は個々の顧客ニーズに合わせたターゲット型コミュニケーションを開始できます。この記事では、Amazon Connect Customer Profilesからのデータを活用し、Amazon Connect Outbound Campaignsによりパーソナライズされたメッセージを作成する方法について解説します。

週刊生成AI with AWS – 2025/7/21週
週刊生成AI with AWS, AWS Summit New York の余韻が続く2025年7月21日号。- 今週はブログ記事の紹介が中心です。ブログ記事では、Amazon Bedrock AgentCore、Amazon SageMaker AI での Amazon Nova のカスタマイズ、TwelveLabs の動画理解モデル、Amazon S3 Vectors と Amazon OpenSearch Service によるベクトル検索の最適化の紹介ブログ含む13件を紹介。

AWS Weekly Roundup: Kiro、AWS Lambda リモートデバッグ、Amazon ECS ブルー/グリーンデプロイ、Amazon Bedrock AgentCore など (2025 年 7 月 21 日)
7 月 21 日、ホーチミン市からシンガポールに戻る途中に記事を書いています。すばらしい一週間だったと思ってい […]

ニューヨークで開催される 2025 年の AWS Summit に関する主要なお知らせ
7 月 16 日、ニューヨーク市で開催された AWS Summit で、エージェンティック AI 担当 AWS […]
AWS、AWS Summit New York 2025 にて AI エージェント構築に向けた新たなイノベーションを発表
本記事は米国時間 7 月 16 日に公開された「AWS announces new innovations f […]

IAM Identity Center を使用した Amazon OpenSearch Service の信頼されたアイデンティティ伝播
この記事では、IAM Identity Center の信頼されたアイデンティティ伝播を使用して Amazon OpenSearch Service のデータに安全にアクセスする方法を説明します。この新しいアクセス方法により、SAML ベースのアプローチと比較して認証フローが簡素化され、OpenSearch UI を通じたシームレスなデータアクセスと堅牢なロールベースのアクセス制御を実現できます。

合併・買収 (M&A) 後のコストを最適化するための AWS Organizations でのベストプラクティス
合併と買収 (M&A) は、事業を拡大し、製品ラインを多様化し、新しい市場を開拓する機会を組織にもたら […]
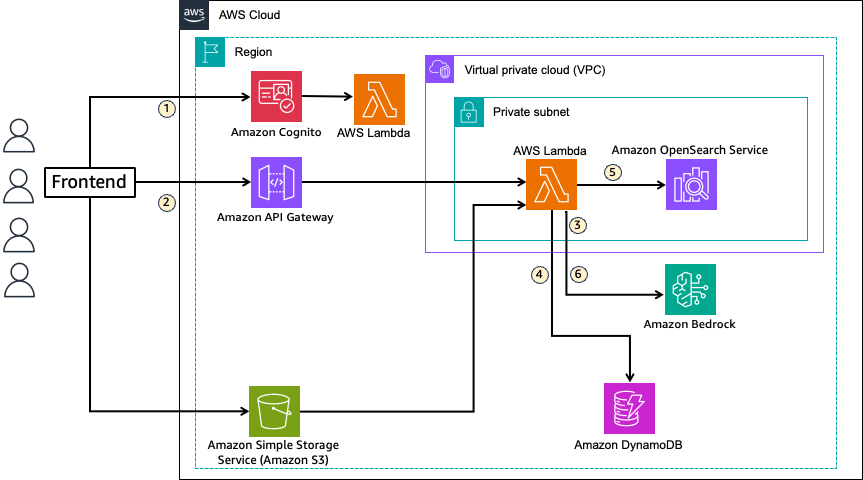
JWT を使用した Amazon Bedrock と Amazon OpenSearch Service による SaaS 向けマルチテナント RAG 実装
本ブログでは、RAG 実装で使用される Vector DB の一つである Amazon OpenSearch Service を例に、JSON Web Token(JWT)と FGAC を組み合わせたテナント分離パターンとテナントリソースへのルーティング方法を紹介します。