Amazon Web Services ブログ

Oracle Database@AWS の高性能ネットワーキング入門
Oracle Database@AWS の高性能ネットワーキング機能を使い、EC2 上のアプリケーションと ODB@AWS データベース間で安定したサブミリ秒のネットワークレイテンシーを実現する設定手順を解説します。

Oracle Database@AWS のバックアップとリカバリオプションを理解する
Oracle Database@AWS (ExaDB-D / ADB-D) で利用できる自動・手動・ユーザー管理・長期バックアップの各オプションと、Amazon S3、OCI Object Storage、Autonomous Recovery Service へのバックアップ先の選択、リストアオプション、ベストプラクティスを解説します。
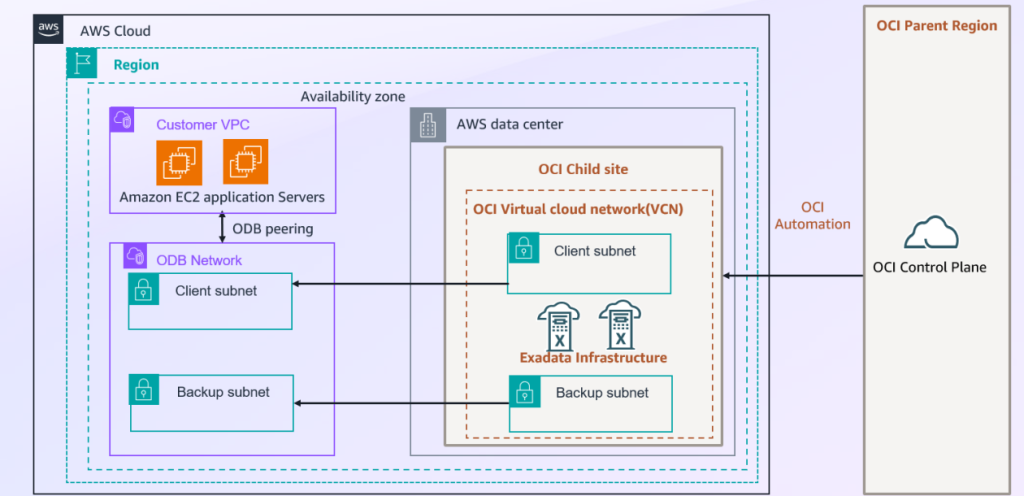
AWS CloudFormation を使った Oracle Database@AWS スタックのプロビジョニング
AWS CloudFormation テンプレートを使って Oracle Database@AWS の主要コンポーネント (ODB ネットワーク、Exadata インフラストラクチャ、VM クラスター) をプロビジョニングする手順を解説します。

AIで変える鉄道保全と、「クローズド」を読み解くクラウド設計 — AWS Summit Japan 2026 展示ブース開催報告
2026年6月25日〜26日、幕張メッセで開催された AWS Summit Japan 2026 にて、AWS […]

Amazon Bedrock と Oracle Database@AWS で生成 AI ユースケースを加速する
Oracle Database@AWS 上の Oracle AI Database 26ai をベクトルストアとして使い、Amazon Bedrock の Amazon Titan 埋め込みモデルと Anthropic Claude LLM を統合した RAG アシスタントアプリケーションの構築手順を解説します。

Amazon RDS for Oracle の追加ストレージボリュームを使ったデータ作成と再編成のベストプラクティス
Amazon RDS for Oracle の追加ストレージボリューム機能を使い、64 TiB を超えるストレージ拡張、アクティブデータと履歴データの分離配置、一時ストレージの確保を行う方法とベストプラクティスを解説します。
株式会社Diverse が Amazon SageMaker で実現した「温度感」ベースのマッチング体験
はじめに 本ブログは 株式会社Diverse 様と Amazon Web Services Japan 合同会 […]

Amazon Bedrock における LLM コストの最適化:請求の帰属から運用テレメトリまで
Amazon Bedrock 上で、基盤モデル (FM) の一種である大規模言語モデル (LLM) の利用が拡 […]

Amazon OpenSearch Service の書き込み可能なウォームストレージでコストと運用負荷を削減
Amazon OpenSearch Service に、書き込み可能なウォームストレージ (writable warm) が加わりました。UltraWarm では履歴データの更新にホットとの往復が必要でしたが、writable warm ならウォームに直接書き込めます。インフラコストは最大 48% 削減でき、更新も数時間ではなく数秒で完了します。
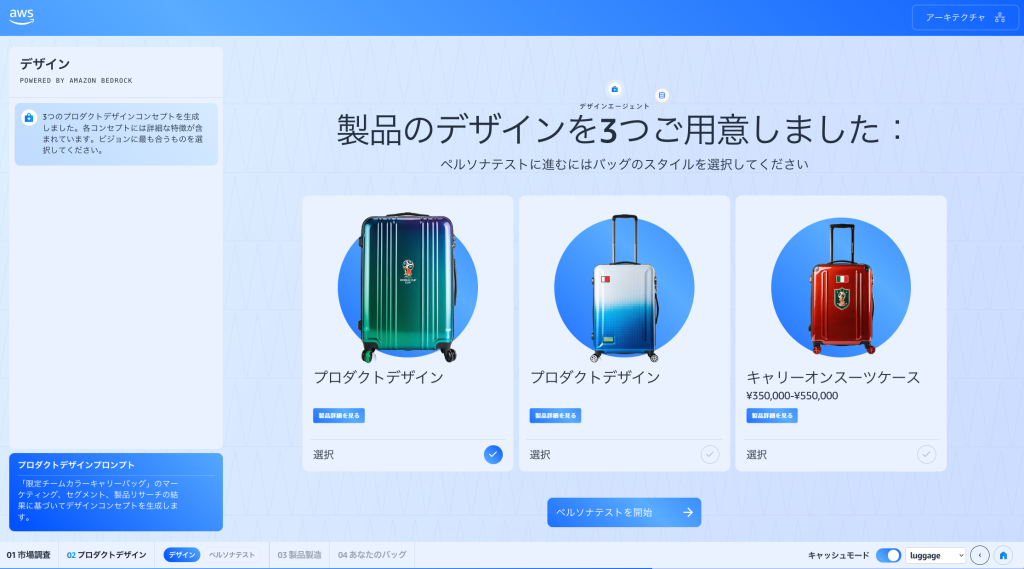
【開催報告】AWS Summit Japan 2026 ― AI で加速する製品イノベーション 〜マルチエージェントで実現する製品開発
はじめに AWS Summit Japan 2026 の流通小売・消費財・飲食ブースにて、私たちは「AI で加 […]