Artificial Intelligence
Combining Deep Learning Networks (GAN and Siamese) to Generate High-Quality, Life-Like Images
Because deep learning relies on the amount and quality of the data that is used to train it, companies spend a lot to get good image data. Typically, they use either expensive human annotation or other labor-intensive tasks, such as taking more photos of products or people. This approach is costly, and it doesn’t scale. Training computers to generate high-quality images can significantly reduce cost and stimulate business growth.
In this post, I explain, in simple terms, the concepts described in an academic paper titled “Semantically Decomposing the Latent Spaces of Generative Adversarial Networks,” which was written by some of my Amazon colleagues. The paper describes the practical application of generative adversarial networks (GANs), Siamese networks (SNs), to allow semantically decomposed GANs (SD-GANs).
GANs and SNs are relatively advanced deep learning symbols, which you can use either individually or in combination with other deep learning symbols to solve real-world problems. Combining these symbols enables AI applications to solve more, harder, and more complex business problems. For example, one of the main challenges for AI is the lack of annotated or tagged data. High-quality annotated data is very costly, so only big or rich companies can get it. Using deep learning methods, such as those described in the paper, allows more companies to generate quality data from fewer samples.
I explain how the authors use GANs, SNs, and SD-GANs to analyze real-life images and use them to generate “fake” images with controlled variations of the same person or object. Depending on the parameters or “observation properties” that you set, the fake images can look like they were taken from different perspectives, or using different lighting, or with improved resolution, or other similar variations. Using the image analysis methods described in the paper, you can create images that are so realistic that they look like they were professionally Photoshopped or that you used 3D models to create them.

Figure 1: Samples generated using the methods described in the paper. Each row shows variations of the same face. Each column uses the same observation properties.
What are generative adversarial networks?
Generative adversarial networks (GANs), are a relatively new deep learning architecture for neural networks. They were pioneered by Ian Goodfellow and his colleagues at the University of Montreal in 2014. A GAN trains two different networks, one against the other, hence they are adversarial. One network generates an image (or any other sample, such as text or speech) by taking a real image and modifying it as much as it can. The other network tries to predict whether the image is “fake” or “real.” The first network, called the G network, learns to generate better images. The second network, the D network, learns to discriminate between the fake and real images. Its ability to discriminate improves over time.
For example, the G network might add sunglasses to a person’s face. The D network gets a set of images, some of real people with sunglasses and some of people that the G network added sunglasses to. If the D network can tell which are fake and which are real, the G network updates its parameters to generate even better fake sunglasses. If the D network is fooled by the fake images, it updates its parameters to better discriminate between fake and real sunglasses. Competition improves both networks.
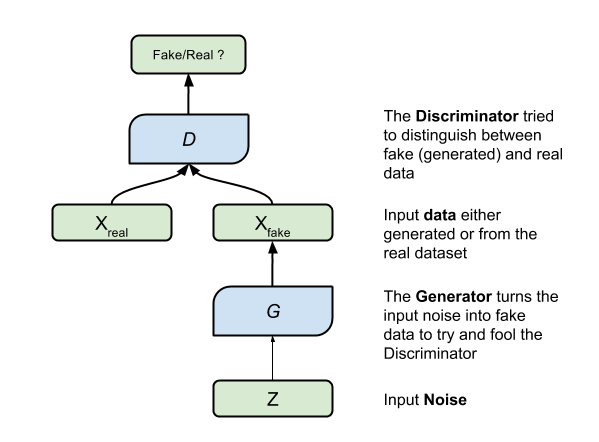
For our purposes, we mainly care about the G network. The ability to generate “fake” images that can fool humans or other AI applications is a big business win.
What are Siamese networks?
Siamese networks (SNs) are also two networks that work together. But unlike GANs, where the networks compete, the two networks are identical and working one beside the other. They compare the networks’ output on two different inputs and measure their similarity.
For example, an SN can verify that two signatures were written by the same person. Or, an SN can check if two sentences that pose a question ask the same question. “What is the time?” is the same as “Do you have the time?” But “Will you marry me?” isn’t the same as “Will you carry me?” The SN takes the first input X1(in our example, a sentence) and translates it into a vector of numbers that it then uses to measure the distance from the output of the second input X2.
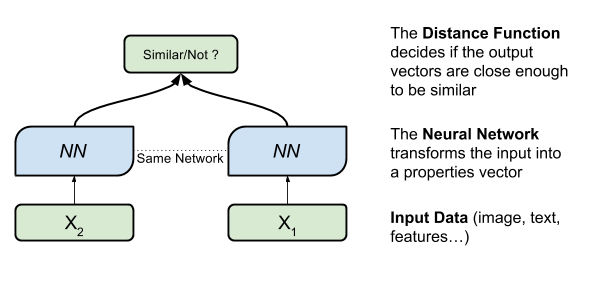
You can input text or other types of data, such as images. In the paper, the researchers use the SN architecture to determine if two images depict the same person (or object) with variations.
What are semantically decomposed GANs?
What if you want to use a specific image of an object or a person, and you simply want to change aspects (such as angle or lighting) of the image? In other words, you don’t want to generate a fake image, but you want to change something about the original image. A standard GAN can generate a picture of a fake shoe that appears to have been taken from a different angle than the original. A semantically decomposed GAN (SD-GAN) can generate a picture of the original shoe from a controlled different angle. SD-GANs can learn to produce images across an unlimited number of classes (for example, identities, objects, or people), and across many variations (for example, perspectives, light conditions, color versus black and white, or accessories). As long as you include many of these classes and variations in your dataset, the SD-GAN can learn to generate photorealistic variations of an original image. For example, in the paper, the authors use a data set of one million celebrity images that include multiple images with different variations for each celebrity.

Figure 2: SD-GAN architecture with the same individual (Zi) and different environment observations (Zo) are given to Siamese generators (G), and then to Siamese discriminators (De). Their output is converted into a binary result, which indicates whether the images are the same person.
How can I get started using these architectures?
Unless you have prior experience with basic deep learning networks, it might be difficult to start using these advanced network architectures immediately. But don’t be intimidated. To start, become familiar with the more basic deep learning symbols that are used in the newer GAN architectures. To begin, run notebook tutorials, such as those in the Apache MXNet GitHub repository. The GAN tutorial is especially helpful. If you prefer videos, watch online courses, such as fast.ai or live coding on twitch.
Additional Reading
Learn how to bring machine learning to iOS apps using Apache MXNet and Apple Core ML.

About the Author
 Guy Ernest is a principal solutions architect in Amazon AI. He has the exciting opportunity to help shape and deliver on a strategy to build mind share and broad use of Amazon’s cloud computing platform for AI, machine learning and deep learning use cases. In his spare time, he enjoys spending time with his wife and family, gathering embarrassing stories, to share in talks about Amazon and the future of AI.
Guy Ernest is a principal solutions architect in Amazon AI. He has the exciting opportunity to help shape and deliver on a strategy to build mind share and broad use of Amazon’s cloud computing platform for AI, machine learning and deep learning use cases. In his spare time, he enjoys spending time with his wife and family, gathering embarrassing stories, to share in talks about Amazon and the future of AI.