AWS Partner Network (APN) Blog
Accelerate FinTech Innovation and Streamline CloudOps with AWS and ChaosSearch
By Chintan Sanghavi, Sr. Partner Solutions Architect – AWS
By Sandro Lima, Alliance Solutions Architect – ChaosSearch
By Shakthi Dakuri, Sr. Partner Solutions Architect – AWS
 |
| ChaosSearch |
 |
Modern FinTech companies are cloud-native, data-driven organizations with a mission to reshape the customer experience for financial services. By leveraging technology, these companies differentiate themselves from the traditional financial services.
To stay ahead in a highly competitive market, FinTechs face multiple challenges, especially around maintaining development agility, operational excellence, and a strong security posture as they grow.
In this post, we explain how the ChaosSearch cloud data platform combines the industry-leading scalability, data availability, security, and performance provided by Amazon Simple Storage Service (Amazon S3) with revolutionary technology to help FinTechs address critical pain points and overcome core operational challenges.
Together, Amazon Web Services (AWS) and ChaosSearch allow FinTech companies to accelerate application development and streamline their operations in the cloud.
ChaosSearch is an AWS Data and Analytics Competency Partner and cloud-native data platform designed for high performance search at massive scale.
Challenges of Traditional Log Analytics Solutions
Analyzing log data generated by applications and systems is an integral part of cloud operations. Logs come in multiple favors (as shown in Figure 1 below) and provide critical insights into the availability, operational status, performance, and security of cloud-based applications and services.
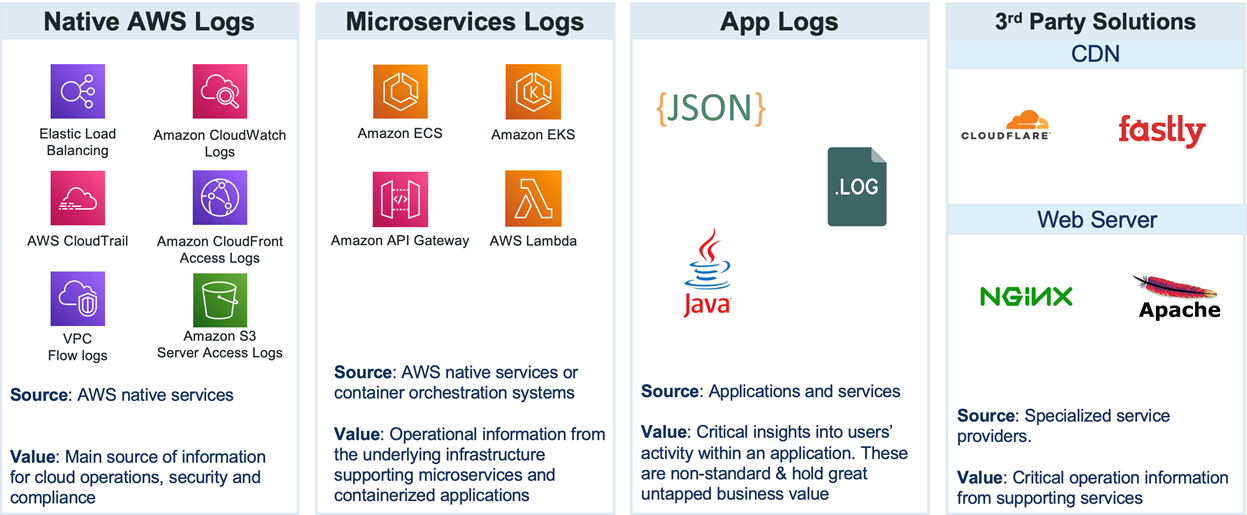
Figure 1 – Log source examples.
Extracting value from raw logs traditionally requires performing resource-intensive and time-consuming data preparation steps before submitting the records to the log analytics solution.
This process involves tasks such as collection, sanitization, filtering, enrichment, and formatting, and is performed by the integration of multiple specialized tools in a complex data pipeline.
Building these data pipelines is only the first step, as they require diligent operation and frequent maintenance to keep up with the ever-increasing log volume and constant changes to the application logs.
After going through this whole process, you can finally have your logs available for analysis in the log analytics solution. However, these tools also bring some additional challenges.
While using a self-hosted (or even partially managed) solution can bring cost savings in terms of infrastructure, the operation burden and need for highly-skilled staff to operate these solutions at scale, has to be considered.
On the other hand, a fully managed solution that can take some of the operational load away also brings its challenges; including limited data retention, the need to duplicate logs to keep a copy before shipping them to a third-party, and a price tag that can be cost-prohibitive at scale.
The scenario described above is particularly critical for FinTechs that frequently experience explosive growth and intense competition in the marketplace, among other challenges.
The need to quickly scale the application and services to meet customer demand has a direct impact on the volume of the logs generated, creating a cascading effect on the downstream data pipeline and log analytics solution, which are required to scale seamlessly to meet the elevated demand.
As a result, growing FinTechs that depend on these solutions will eventually face complexity and performance trade-offs that lead to loss of insights. This may prevent them from making full use of their log data.
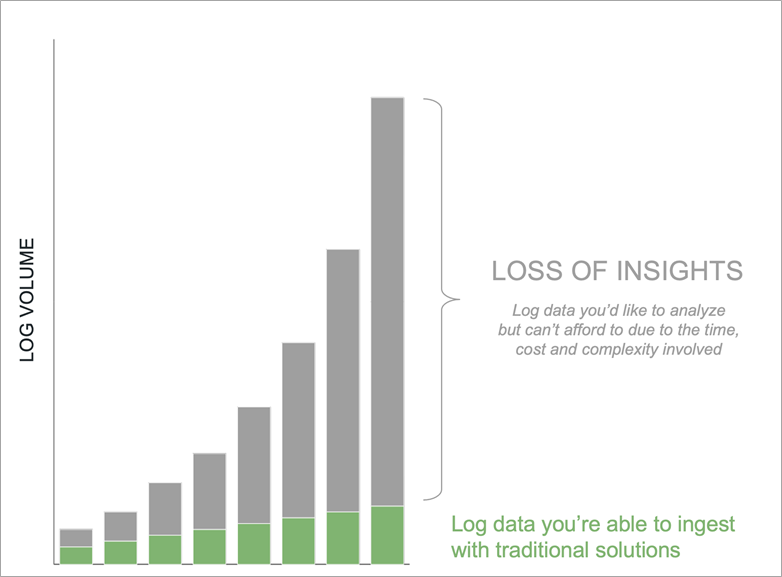
Figure 2 – Loss of insights due to increasing log volumes.
To differentiate themselves in a highly competitive market, FinTechs are required to innovate quickly through fast-paced development. Constant changes to the application code affect logging outputs and the downstream data pipelines, which can break down and must be manually reconfigured by data engineers to capture the new logs.
This can create a counter-productive dynamic where developers feel pressured to slow their development activities, thereby avoiding disruption to logging activities that ensure the availability, reliability, performance, and security of the application.
ChaosSearch Solution Overview
The ChaosSearch data lake platform delivers search and relational analytics at scale directly in Amazon S3, with no data movement, no extract, transform, load (ETL) process, and zero administrative overhead.
With ChaosSearch, FinTech companies can capture, analyze, and retain more of their data with massive reductions in time, cost, and complexity.
Scalable, Secure, and Cost-Effective Storage
ChaosSearch incorporates a proprietary indexing technology called Chaos Index—a compressed representation of cloud object data—that provides 10-20x compression with no data loss and significantly reducing the cost to store, index, and query log data.
After indexing the log data, customers can delete or move the original log data to Amazon S3 Glacier.
Because data always stays in a customer’s Amazon S3 buckets, FinTechs can take advantage of cost-effective cloud object storage, removing the need to backup or replicate data between S3 buckets and an external log analytics platform.
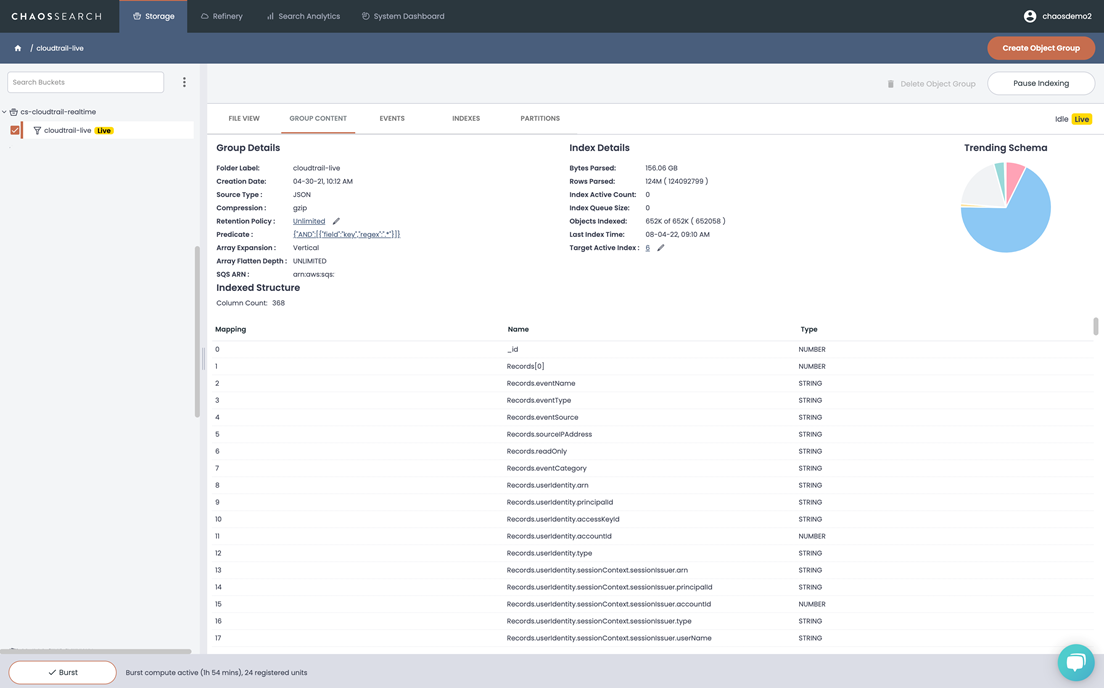
Figure 3 – ChaosSearch live indexing.
Simple and Scalable Data Pipelines
Analyzing logs directly in Amazon S3 (with no data movement and no ETL process) means simpler data pipelines and the ability to fully leverage managed services like Amazon Kinesis Data Firehose.
This can provide easy launch and configuration, near real-time data delivery, elastic scaling to handle varying data throughput, among other benefits.
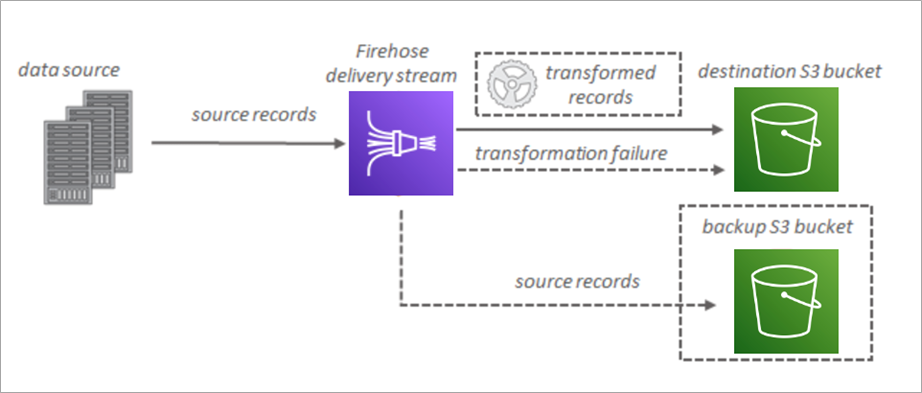
Figure 4 – Amazon Kinesis Data Firehose data flow.
Unlike legacy tools, the ChaosSearch log analytics solution follows a schema-on-read approach that allows FinTechs to store and index log data in its raw form. Companies can then apply transformations and schema changes through virtual views at any time, without duplication, over the stored data.
The Chaos Refinery cleans, prepares, and virtually transforms data, allowing users to programmatically and visually interact with information as needed, without the pain of data pipelining, cleansing, engineering, or ETL work.

Figure 5 – Chaos Refinery.
Through virtual views, users can transform a field into multiple new fields to query and aggregate data and adjust the schema—changing fields from strings to integers—to allow search on ranges and different analyses.
Users can create an entirely new view of their data, within seconds, all without having to duplicate or reindex the data.
Conclusion
FinTech companies drive revenue and user growth by developing and releasing new products and features—not by managing cloud infrastructure.
This simple truth means there is a genuine business need for FinTechs to offload the administrative overhead of legacy log analytics tools without breaking the bank.
ChaosSearch is delivered as a true software-as-a-service (SaaS) product with zero administrative overhead. With ChaosSearch, engineers and data professionals can spend less time managing logs and more time developing new features and applications that drive revenue.
Start your free trial today or view the on-demand demo to discover how the ChaosSearch platform delivers analytics at scale with data lake storage economics, no data movement, and unlimited data retention and queries.
.
 .
.
ChaosSearch – AWS Partner Spotlight
ChaosSearch is an AWS Data and Analytics Competency Partner and cloud-native data platform designed for high performance search at massive scale. ChaosSearch indexes all log data located in a customer’s Amazon S3 cloud object store as-is, without the need for any data transformation or data movement.