AWS Partner Network (APN) Blog
Data Tokenization with Amazon Redshift and Protegrity
Editor’s note: This post was updated in December 2022.
By Brandon Schur, Sr. Database Engineer – AWS
By Muneeb Hasan, Sr. Partner Solution Engineer – Protegrity
By Tamara Astakhova, Sr. Partner Solutions Architect – AWS
By Venkatesh Aravamudan, Partner Solutions Architect – AWS
 |
| Protegrity |
 |
Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze data using standard SQL and your existing business intelligence tools.
Many companies are using Amazon Redshift to analyze and transform their data. As data continues to grow and become even more important, they are looking for more ways to extract valuable insights.
Amazon Redshift’s Lambda UDF support makes it easier than ever to integrate with external big data analytics and data enrichment platforms. Lambda UDFs can be written in any of its supported programming languages, such as Java, Go PowerShell, Node.js, C#, Python, Ruby, or custom runtimes.
One use case we’re especially excited to support is that of data tokenization and masking.
Amazon Redshift has collaborated with Protegrity, an AWS Data and Analytics Competency Partner with the Amazon Redshift Ready specialization, to enable organizations with strict security requirements to protect their data while being able to obtain the powerful insights.
Protegrity for Amazon Redshift
Protegrity, a global leader in data security, provides data tokenization for Amazon Redshift by employing a cloud-native, serverless architecture.
The solution scales elastically to meet Amazon Redshift’s on-demand, intensive workload processing seamlessly. Serverless tokenization with Protegrity delivers data security with the performance that organizations need for sensitive data protection and on-demand scale.
Protegrity for Amazon Redshift Serverless
Amazon Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. Just load data and start querying right away in Amazon Redshift Query Editor v2, or in your favorite business intelligence (BI) tool, and continue to enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment.
Protegrity provides solutions for Amazon Redshift Serverless similar to Amazon Redshift by employing a cloud-native, serverless architecture. From a usability standpoint, both Amazon Redshift and Amazon Redshift Serverless would work in a similar way with Protegrity.
About Tokenization
Tokenization is a non-mathematical approach to protecting data while preserving its type, format, and length. Tokens appear similar to the original value and can keep sensitive data fully or partially visible for data processing and analytics.
Historically, vault-based tokenization uses a database table to create lookup pairs that associate a token with encrypted sensitive information.
Protegrity Vaultless Tokenization (PVT) uses innovative techniques to eliminate data management and scalability problems typically associated with vault-based tokenization. Using Amazon Redshift with Protegrity, data can be tokenized or de-tokenized (re-identified) with SQL depending on the user’s role and the governing Protegrity security policy.
Here’s an example of tokenized or de-identified personally identifiable information (PII) data preserving potential analytic usability.
The email is tokenized while the domain name is kept in the clear. The date of birth (DOB) is tokenized except for the year. Other fields in green are fully tokenized. This example tokenization strategy provides the ability to do age-based analytics for balance, credit, and medical.

Figure 1 – Example tokenized data.
Solution Overview and Architecture
Amazon Redshift Lambda UDFs are architected to perform efficiently and securely. When you execute a Lambda UDF, each slice in the Amazon Redshift cluster batches the applicable rows after filtering and sends those batches to your Lambda function.
The federated user identity is included in the payload, which Lambda compares with the Protegrity security policy to determine whether partial or full access to the data access is permitted.
The number of parallel requests to Lambda scales linearly with the number of slices on your Amazon Redshift cluster, and performs up to 10 invocations per slice in parallel. To learn more, see the Amazon Redshift architecture.

Figure 2 – Amazon Redshift and Protegrity architecture.
The external UDF integration with Lambda efficiently scales with cluster size and workload. The following table shows real benchmarks with Protegrity and Amazon Redshift with throughput exceeding 180M token operations per second (6B token operations / 33.1 seconds).
Median Query Time(s) – Cluster vs. # Token Operations
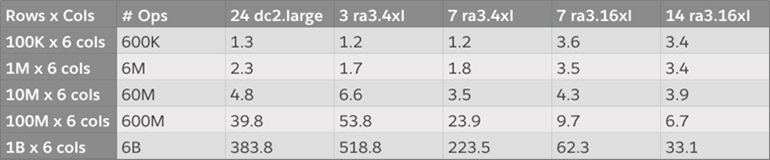
Figure 3 – Token operation benchmark.
Setting Up Tokenization with Protegrity and Amazon Redshift
For this post, we assume there is a running Amazon Redshift cluster in your account. If you do not have one set up, the Amazon Redshift Getting Started page is a great place to learn how to create and configure an Amazon Redshift cluster.
We also assume you have a Protegrity account and have set up Protegrity Serverless in your account. The Lambda function used in this post can be acquired from Protegrity. Visit Protegrity Amazon Redshift for additional information and guidance.
Step 1: Create IAM Role to Allow Amazon Redshift to Invoke the Lambda Function
You will need to associate an AWS Identity and Access Management (IAM) role with your Amazon Redshift cluster that has an attached policy, which allows it to invoke the Lambda function.
You can optionally harden the role’s resource element to limit which Lambda functions the Amazon Redshift cluster can invoke. See Authorizing Amazon Redshift to access other AWS services on your behalf for more information.
The following IAM policy, when associated with the Amazon Redshift cluster’s IAM role, would allow it to invoke any Lambda function. As a security best practice, the use of wildcard elements should be restricted as much as possible.
Step 2: Create the UDFs
Next, we will be mapping multiple UDFs to a single Lambda function. Amazon Redshift passes the name of the UDF in the user input field of the JSON payload.
Protegrity uses these function names to map to the operation type (protect/unprotect) and data element name (Name, Email, and SSN, for example). As such, the name of the function is required to have the form [protect | unprotect]_[dataElementName].
The following example SQL shows how to create multiple Lambda UDFs to protect and unprotect data. The UDF argument and return data types should match the data types in which it is stored in Amazon Redshift tables. Note that these are sample UDFs which may not work as mentioned due to updates. Always test with the latest version of UDFs.
You can download the latest trial experience scripts on the Protegrity website.
Step 3: Test and Verify the Lambda Functionality
We can now verify the basic functionality by running a few sample queries on the cluster. Note that the Amazon Redshift user executing the query is sent to the Lambda function under the “user” JSON attribute.
The Protegrity Lambda function will use that information to verify the calling user permissions and whether they can access the untokenized data. Otherwise, a null value will be returned by default (users can further verify their user name via the current_user function).
The following example shows how these null values would appear to an unauthorized user:
Now, let’s see how these calls are logged in Amazon Redshift and Lambda. The query execution can be analyzed via the Amazon Redshift console, as well as via the Amazon Redshift cluster’s system views where queries are typically logged
The following example shows query runtime information from the stl_query system view:
The Lambda function invocations will be logged and can be seen via the Lambda function’s Amazon CloudWatch metrics.
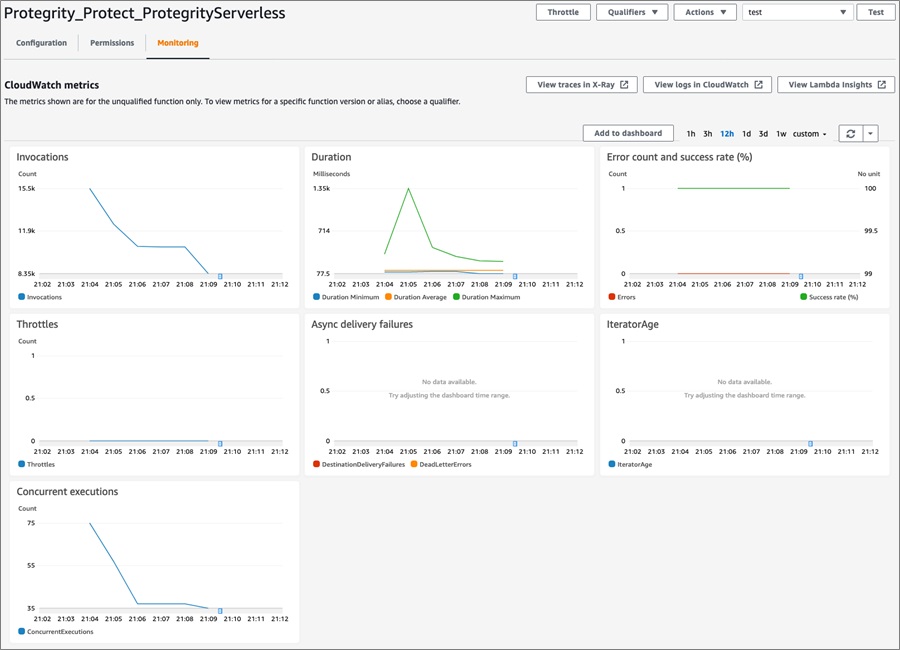
Figure 4 – Amazon CloudWatch metrics.
Each individual Lambda invocation will be logged in the CloudWatch logs. These logs can be searched and analyzed via CloudWatch Logs Insights.
For examples on how to use this information, see this blog post on Understanding AWS Lambda Behavior Using Amazon CloudWatch Logs Insights.
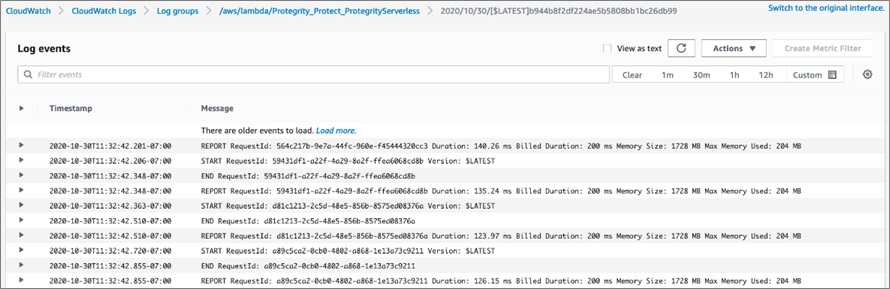
Figure 5 – Amazon CloudWatch Logs.
Any errors, such as an unauthorized access attempt, will be visible in the CloudWatch logs.
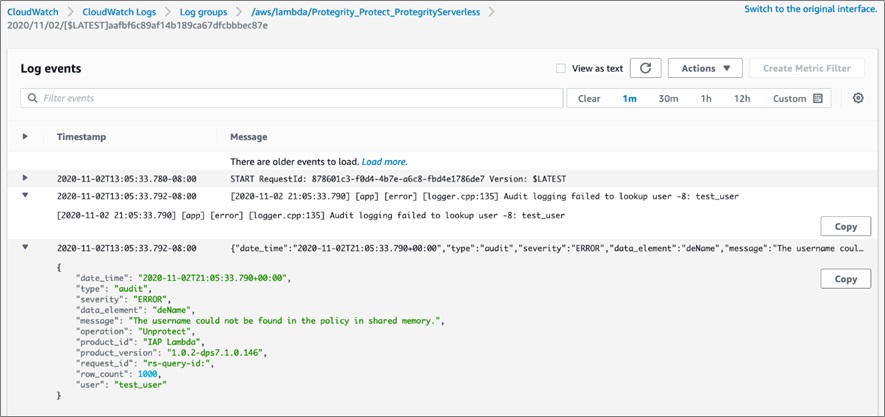
Figure 6 – Amazon CloudWatch Logs unauthorized user.
Testing Real-Life Workloads
Once we’ve successfully verified the tokenization functionality, we can perform another test to reflect real-life workload with larger scans.
The following SQL shows how you could measure the execution time for 100M rows of tokenization across three columns (300M token operations). This SQL was executed on a three-node ra3.4xl cluster.
Here, you can see we were able to execute the scan of 100M rows in well under a minute. CloudWatch stores metrics from Lambda at the standard one-minute resolution.
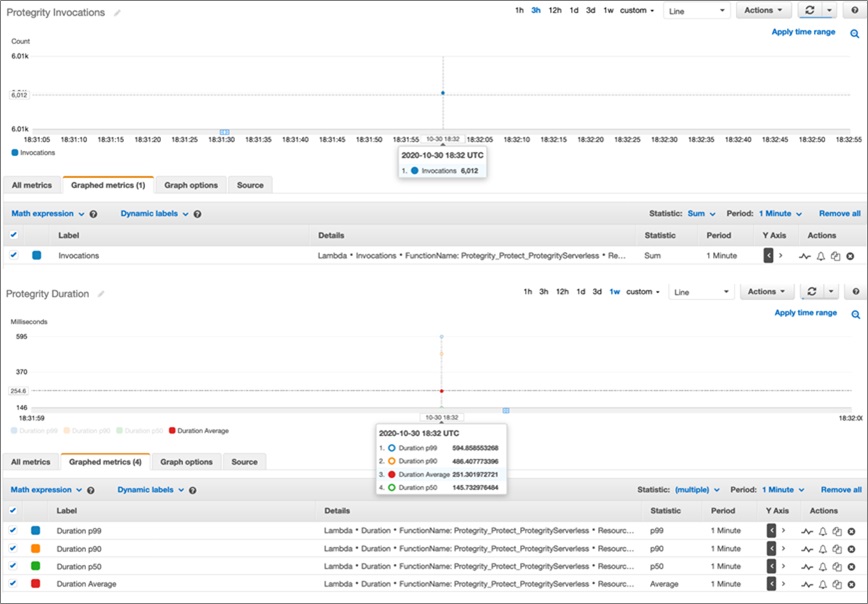
Figure 7 – AWS Lambda duration metrics for a short query.
Now, let’s look at how the Lambda behavior changes when running multiple larger queries in parallel. In this example, five queries were executed—each working on a billion records with varying numbers of UDFs.
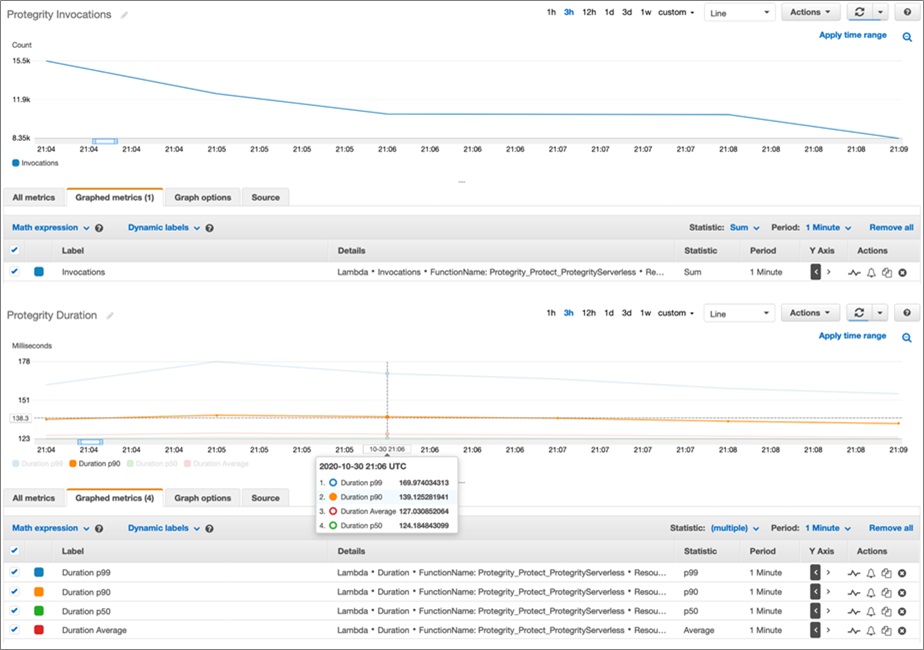
Figure 8 – AWS Lambda duration metrics across multiple long running queries.
Configuring Cross-Account Access
Most companies group AWS accounts into separate logical structures to organize and secure their AWS resources. Organizational Units can be used to group and administer these accounts as a single unit.
With IAM role chaining, you can configure the Protegrity Lambda in one AWS account and keep your Amazon Redshift cluster in a separate AWS account in the same AWS region. Note that these are sample UDFs which may not work as mentioned due to updates. Always test with the latest version of UDFs.
You can download the latest trial experience scripts on the Protegrity website.
Conclusion
In this post, I showed how users can integrate Amazon Redshift Lambda UDFs with the Protegrity Serverless product and support scalable and performant tokenization and detokenization.
For more details on how to create an Amazon Redshift Lambda UDF, refer to the documentation. To learn more about the Protegrity Serverless solution, visit the Protegrity website.
Cloud Protect for Amazon Redshift is available for purchase through AWS Marketplace.
.

.
Protegrity – AWS Partner Spotlight
Protegrity is an AWS Competency Partner with the Amazon Redshift Ready specialization that provides fine-grained data protection capabilities (tokenization, encryption, masking) for sensitive data and compliance.