AWS Partner Network (APN) Blog
Double Your Speed-to-Data Quality with Elula’s Data Quality Checker and AWS Glue
By Toby Ruby, Head of Engineering – Elula
By Tony Trinh, Sr. Partner Solutions Architect – AWS
 |
| Elula |
 |
Elula is an AWS Partner and leading provider of artificial intelligence (AI) software to the financial services sector. Its flagship product, Sticky, predicts which customers will churn to another organization, refinance, or sell their property. Sticky predicts which customer is going to leave and delivers reasons why, as well as recommended conversations to have with them.
Elula’s latest product in market, Nudge, is focused on growth and lifts customer engagement with targeted “nudges.” Nudge’s prediction modules help enterprises make the best decisions and offer their customers the right products, offers, and actions at the right times to lift overall customer engagement and support customer needs.
Elula is one of the largest big data environments on Amazon Web Services (AWS) in the Asia Pacific (Sydney) region, processing over 100 billion data points every month—and growing. This post covers how Elula faces and overcomes one of its biggest challenges: data quality.
Ensuring the ongoing performance of the machine learning (ML) products Elula provides to customers relies on the quality of the data put into the models.
Elula needed something fast and scalable to cope with any dataset presented. It needed to be detailed and rigorous to penetrate datasets right down to the lowest level of granularity, and it needed to be superficial enough to identify broader trends of quality issues. Lastly, it needed to be easy to extend by Elula’s data scientists and data engineers with specialized metrics and checks.
Data quality is traditionally inconsistent and slow across teams and functions. Custom solutions are purpose-built, of varying quality, and rarely maintained. Elula developed a proprietary Data Quality Checker (DQC) powered by AWS Glue, and an Automated Data Assessment (ADA) user interface to accelerate the identification and prioritization of issues.
In this post, we’ll cover how DQC and ADA work on AWS and the benefits for Elula’s customers.
DQC and ADA Overview
The Data Quality Checker (DQC) both profiles data and automates data checks, comparing to previously received data as well as to data points within the dataset itself.
The power required for such intensive compute tasks is sporadic, changes depending on the profiles and checks required, and is very short of nature. AWS Glue is a perfect match for this workload; managed, serverless, configurable, yet scalable to the large datasets.
The Automated Data Assessment (ADA) user interface provides a rich context and examples for any findings, so decisions are recorded and just a single click away. It’s also where required assessments can be annotated.
The friendly and intuitive UI makes data quality reviews accessible and simple. The significant speed-up in time-to-review and time-to-resolve allows the team at Elula to onboard customers quicker and focus on improving Elula’s predictive and explanatory AI.
Automate Data Checks
Elula’s Sticky and Nudge products persist data strategically throughout the transformation process. As such, DQC must be able to connect to a variety of data sources, such as:
- Any database, table, or view defined in AWS Glue or compatible Hive meta store.
- Any database, table, or view accessible via Java Database Connectivity (JDBC).
- Any dataset persisted on an Amazon Simple Storage Service (Amazon S3) bucket.
- Custom Sticky or Nudge component outputs.
The DQC is split into two significant workflows, the computational expensive profiling using both standard and highly customized metrics such as Max, Distinctness, TimeMissing, or Population Stability Index (PSI), and the checking of profiled metrics against a target or threshold.
The generated profile records all metrics in a single table (see below) which is used by both DQC and ADA for automation and decision recommendation purpose, as well as for both Elula’s data engineers and data scientists. This single source of truth enables the team to run any ad-hoc analysis over time, over datasets, and over products, and quickly pinpoint the source of the data quality issue.
Elula often found standard metrics were insufficient: they didn’t surface the data quality issues that were found manually. The team needed a simple, straightforward platform through which data engineers and data scientists could create new metrics.
Once this platform was created, ideas flowed in and Elula developed more than 30 metrics—and that is still growing.
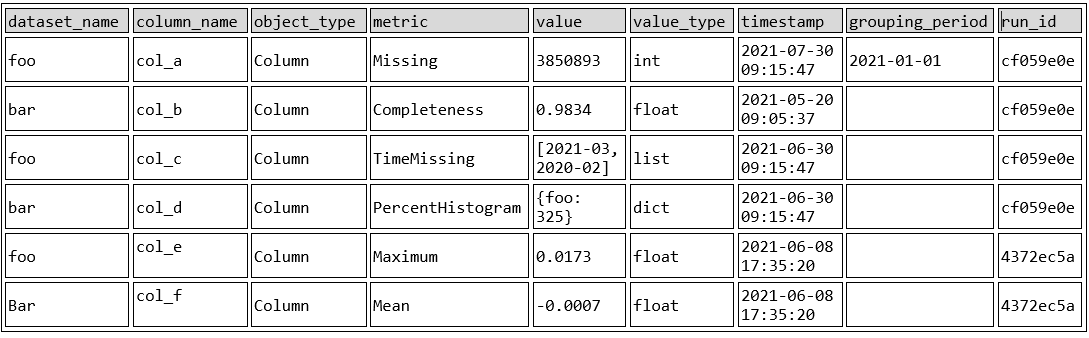
Figure 1 – Example profiling report.
Profiling data the right way is just the first step to consistent data quality. Learning from Elula’s resident data scientists helped the team identify several patterns (upwards trending, volatile, spikey, etc.) and matched their checks and thresholds accordingly.
Balancing the thresholds right was crucial for the success of DQC at Elula; too lenient and quality issues will be missed, too restrictive and it created a massive operational overhead of reviewing false positives.
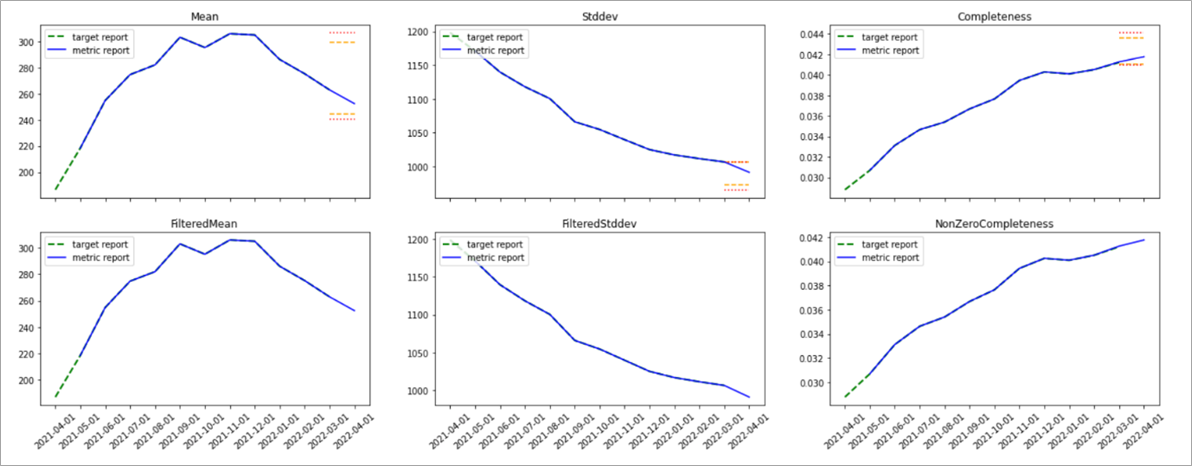
Figure 2 – Quality boundaries.
Metrics, thresholds, and criticality of checks are determined together for optimal operations flow. For example, in Figure 2 we observe a feature using three different metrics with two thresholds (warning, and critical) each. Thresholds are determined based on past performance, and can be specified absolute (143<=x<=167) or relative (+10%/-13%).
The check criticality is used to determine the severity as well as the follow up actions:
informational(default); used to record, monitor, and improve checks over time.warning; does not require a human intervention; is reviewed on discretion by the operations team’ must be viewed in aggregate and wider context of other checks.critical; requires human intervention.
Easy Data Quality Review
Running seamlessly on AWS Glue, the DQC allowed Elula to scale efforts to any number of datasets and any data size for any customer. As the company’s customer base grew, it needed to scale the approach and simplify the review time as the number of findings increased and prioritization and issue resolution became more important.
Elula developed ADA to standardize, streamline, and automatically assess findings. For data engineers to be thorough yet quick when manually assessing findings, the provided context and detail must match the problem at hand.
Elula has various charts, plots, and summary tables available matching the most common assessments. When the context is not enough and further analysis is required, data engineers often must reproduce the results on their own.
With ADA, they are just a click away from copying an automatically formulated reproducing the finding into their favorite integrated development environment (IDE).
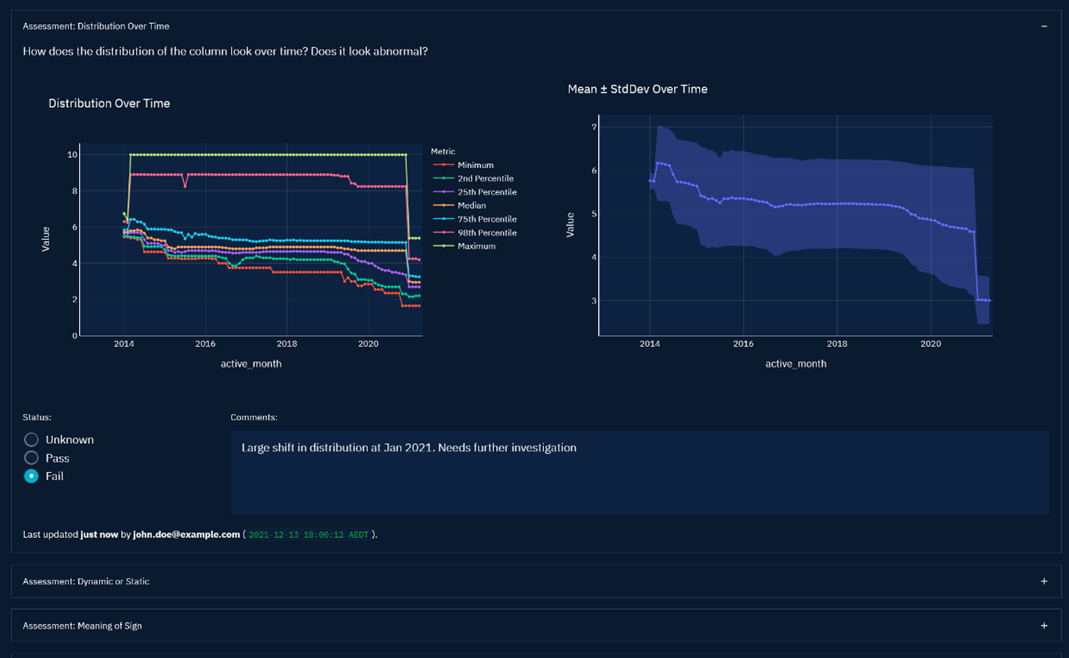
Figure 3 – Example assessment showing distribution of data over time.
ADA captures outcome and feedback consistently for all assessments, enabling Elula’s data engineers and project managers to get an aggregated overview to help track progress and confirmed or rejected assessments.
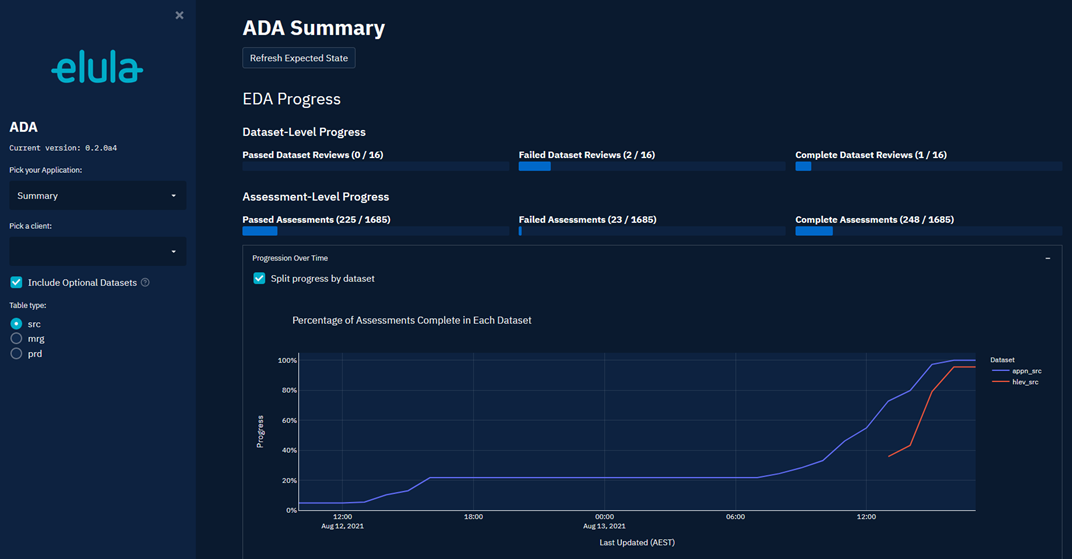
Figure 4 – Assessment progress summary.
Managed, Serverless, Scalable Infrastructure
Elula is focused on building value for customers and only reinvents the wheel where necessary; otherwise the company relies on partners like AWS. Managed, serverless, and scalable services like AWS Glue and Amazon Athena are a cornerstone of Elula’s technology stack.
DQC is developed and executed as a Python package, can be run locally on small datasets, and runs as an Apache Spark job on AWS Glue. Right-sizing the AWS Glue job is as simple as dialing the number of workers up or down and the internal Apache Spark scheduler optimizes the execution plan accordingly.
Sticky and Nudge record meta information—like lineage and primary keys—about datasets in Amazon DynamoDB tables, making it available for tools like DQC and ADA.
DQC automatically enables and refines metrics and checks if certain metadata exists. ADA uses the available metadata to enrich the displayed context and assessment information.
Jumping from the high-level ADA assessment deep into the data is seamless thanks to the ad-hoc query execution on Amazon Athena. This service connects and scales to any dataset and size; if necessary, data engineers can pull in data from other Elula products like Wonderlake.
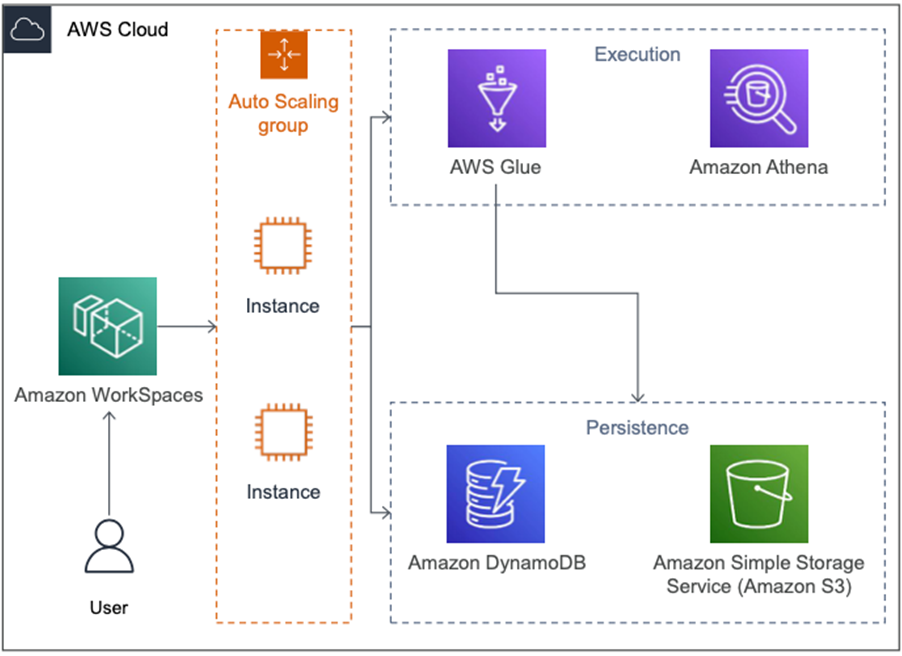
Figure 5 – Secure and scalable assessment architecture.
Customer Use Case
A common concern of customers is the varying internal state of data quality. Banks migrate internal IT systems, data warehouses get extended, and new data lakes are formed. All of this adds to uncertainty, whether the data quality is sufficient and viable enough for any AI or ML projects.
With DQC and ADA, Elula applies a consistent and thorough review to any dataset, efficiently maximizing the value and confidence for each dataset. Where required and agreed, Elula removes unreliable information.
Customers benefit from a consistent and prioritized review process. This minimizes time spent during onboarding and overall time-to-value for both Sticky and Nudge.
Summary
Leveraging managed, serverless, and scalable services like AWS Glue and Amazon Athena allowed Elula to significantly speed up data quality checks and maintain a relatively small software engineering footprint.
With Data Quality Checker (DQC) and an Automated Data Assessment (ADA) user interface, Elula’s data engineers and data scientists can quickly identify the high-value data quality issue and focus on their resolution.
Customers appreciate the quick turnaround time and benefit from fast time-to-value after subscribing to Sticky and Nudge.
To learn more, see how Sticky offers up tangible actions to engage and retain customers, while Nudge uncovers the best tailor-made interactions to have with customers.
.

.
Elula – AWS Partner Spotlight
Elula is an AWS Partner and leading provider of artificial intelligence (AI) software to the financial services sector.