AWS Partner Network (APN) Blog
How to Mitigate Security and Privacy Resistance in Secure Data Migrations
By JT Sison, Sr. Vice President of Partner Relationships – PKWARE
By Tamara Astakhova, Partner Solution Architect – AWS
 |
One of the first steps for organizations adopting Amazon Web Services (AWS) is migrating data from an on-premises environment or existing cloud to AWS.
While there are many important logistics to consider as part of this migration—like application downtime and the mechanics of migration—one of the most critical aspects is knowing and detailing exactly what data is being migrated.
Many legal and regulatory requirements make it imperative to know the cause and reason for collection, storage, and usage of data, as well as the exact physical location of the data. Furthermore, any movement of data is often accompanied with higher usage for better utilization.
This means that more data will be accessed and by more people. Thus, stronger and more granular controls need to be installed for better data protection and compliance.
PKWARE is a data-centric governance solution that detects, audits, protects, and monitors sensitive data assets wherever they live, and moves across the enterprise and the cloud.
In this post, we will demonstrate how the Dataguise solution can help organizations minimize risk and cost during the data migration process by protecting personal and sensitive data with flexible masking or encryption options.
Dataguise, a PKWARE company, is an AWS Partner with the AWS Data & Analytics Competency that helps organizations minimize risks and costs as they store and use data to drive business value.
Problem Statement
Prior to the migration of data into AWS, a comprehensive scan is required to provide appropriate insights into the data’s sensitivity. Based on these optics and data privacy regulations, a decision needs to be made regarding whether or not the data can be migrated.
Prior to the migration, some form of remediation may be needed, which will ensure compliance and data protection in this process.
Solution Overview
The comprehensive secure data migration solution consists of two data discovery scans: a pre-migration audit, and a post-migration guarantee.
A pre-migration scan is typically done at the source the data is being migrated from, in order to produce a report that precisely describes the type and location of sensitive and personal data. Based on this report, action can be taken in the form of remediation, migration, or both.
A post-migration scan may not be necessary. However, Dataguise recommends doing this scan for two reasons:
- A post-migration scan guarantees that after the data is remediated and migrated, no unnecessary data mistakenly ends up in AWS.
- An inventory of personal and sensitive data is helpful in ensuring proper and comprehensive reports for auditors in the event of an audit for compliance certification.
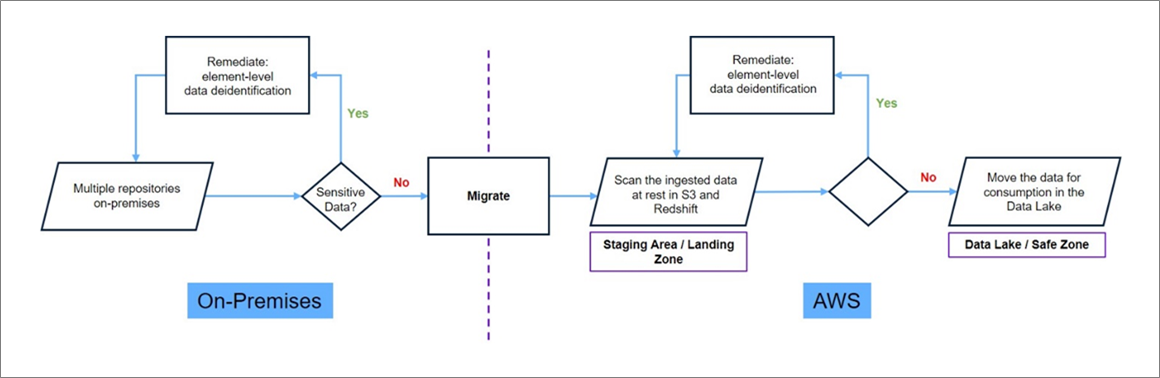
Figure 1 – Two-step scan for data migration process.
Dataguise Features and Benefits
The Dataguise solution has many features to manage sensitive and personal data, including data discovery, metadata discovery, data masking, data encryption and decryption, data subject access requests, right to be forgotten, and comprehensive reporting.
For data migration, there are two key features needed:
Data Discovery
The detection of sensitive and personal data uses a policy as an input along with the scan location. The Dataguise solution comes with different detection policies, more than 90 out-of-the-box discoverable data elements, and allows users to define custom data elements for detection.
The output includes the exact type, location, and quantity of the found data. Detection uses unsupervised and supervised machine learning (ML) along with pattern matching, contextual analysis, reference data matching, and several validation functions.
Reporting
Because of its ability to scan data both at scale and at the element level, Dataguise can provide insights into the sensitivity of data and its use across the enterprise. This is relevant for meeting many of the common requirements for regulations, such as the GDPR and CCPA, as well as specific contractual requirements that may arise.
Furthermore, the product includes natively built reports as well as a Tableau license for reporting and data visualization.
Reference Architecture
The Dataguise solution has three main components:
Controller
This centralized server is responsible for all user and product management, along with all administrative functions. The controller does not do any computing, but is responsible for orchestrating and managing all the functions of the product.
The controller can be installed either on-premises or on AWS. In a migration use case, the first scan traditionally happens on-premises. It’s recommended to install the controller on any Linux or Windows machine.
Metadata Repository
The controller is typically installed with a backend database, which may be any standard relational database like SQL Server, Oracle, MySQL, or Postgre SQL. This is where Dataguise stores all of the metadata needed to run the product, including user information, policy information, task definitions, or user preferences.
Special care is taken to ensure the security of the information in the metadata repository by encrypting all the data, even though no actual sensitive information is ever stored in it.
Intelligent Data Processors (IDPs)
These remote components are utilized to find, mask, encrypt, or decrypt the data. IDPs can scale horizontally or vertically. The exact number of IDPs will depend on the deployment.
There is one IDP for all the relational databases, NoSQL databases, file shares, Hadoop, Amazon Simple Storage Service (Amazon S3), and third-party cloud based packaged applications.
The idea is to have one centralized controller and one or more IDPs installed geographically close, but remote to the target systems.
The IDPs do the processing locally and send the results back to the controller, which is stored in the metadata repository. This means that there will be IDPs both on-premises to do the pre-migration scans and in AWS for the post-migration scans.
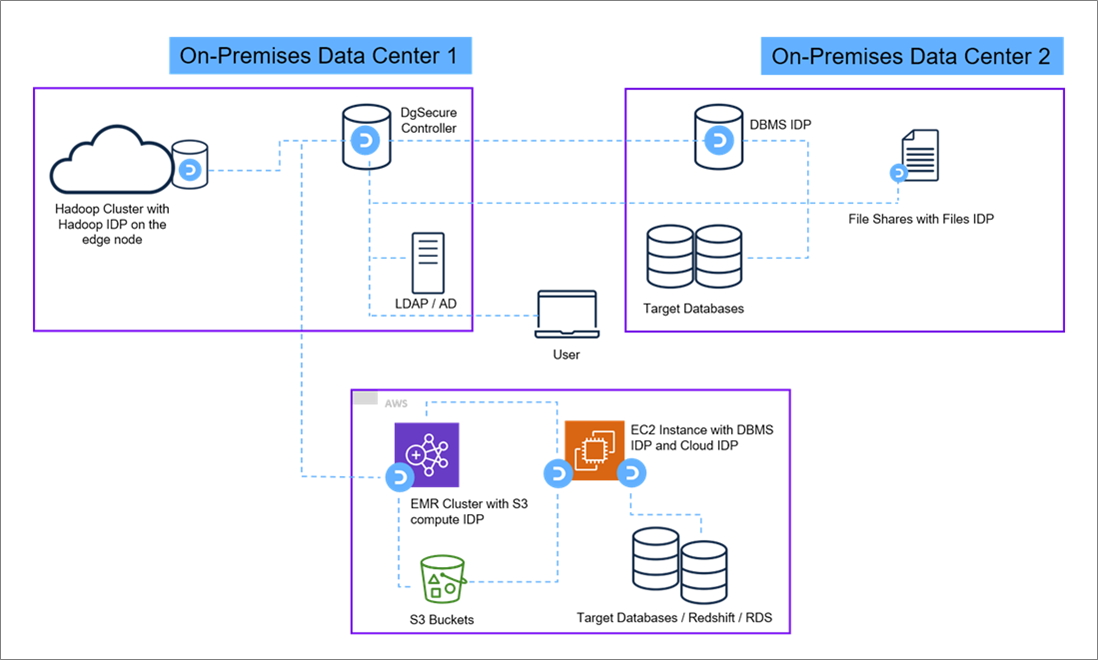
Figure 2 – IDP deployment architecture.
Solution Deployment and Support
The solution should ideally be deployed in a hybrid environment covering target systems both on-premises and on AWS. The centralized controller can be installed on-premises or AWS, and can be accessed via a web-based user interface or APIs from wherever access is allowed.
The execution of the pre-migration and post-migration scans can be fully automated, since every function in Dataguise has an API that can trigger it, such as creating a data discovery task, executing tasks, and so on. The entire workflow can be set up on any standard workflow solution or custom orchestrators created by Dataguise.
Automation on AWS for post-migration scans is done via AWS Lambda functions. As data moves into AWS—say in Amazon S3 or Amazon Redshift—the Lambda functions detect this newly created data, and then automatically kick off the Dataguise scans and power the necessary reports and dashboards.
Customer Success
A large U.S.-based financial institution had been using AWS since 2016. When the board decided to move most of its data into Amazon S3 and Amazon Redshift, the company’s legal department put certain constraints on what data needed to stay on-premises and what data could be migrated into AWS.
Their key legal requirement was to keep all Social Security Numbers and credit card numbers on-premises.
To achieve this, a pre-migration data discovery scan was done on Oracle, SQL Server, and file shares on-premises. Based on the results of the scan, the data asset was either migrated to AWS or subjected to an automated remediation process, after which it was ultimately migrated to AWS.
Approximately every three seconds, a new file or table on-premises was scanned and migrated into S3 or Amazon Redshift. Once the data migrated, Lambda functions detected this and invoked the post-migration scan. Both scans looked for Social Security Numbers and credit card numbers.
Although most of the data was either structured or unstructured, there were a few database columns that had free form text call center transcripts. Dataguise deep data discovery scans were able to accurately scan all structured, unstructured, and semi-structured data.
Summary
Data migration is an important step that every organization considers when migrating from an on-premises environment or existing cloud to AWS. One of the more critical parts of the data migration process is protecting sensitive data.
The solution from PKWARE provides comprehensive data scans and remediation of sensitive data even before the data is migrated to AWS. This helps organizations reduce the overall risk of legal and regulatory violations.
If you’d like to start a free trail of the solution, please contact PKWARE.
Dataguise products are also available on AWS Marketplace.