AWS Partner Network (APN) Blog
How to Peel Mainframe Monoliths for Microservices with AWS Blu Age
By Alexis Henry, Chief Technology Officer at AWS Blu Age
 |
Mainframe monoliths have grown over the years with overwhelming complexity. They often mix different languages and data stores with various interfaces, evolving coding standards, online and batch, and millions of lines of code.
With Amazon Web Services (AWS), customers use microservices for agility, elasticity, and pay-as-you-go cloud technology.
In this post, we describe AWS Blu Age solutions to peel off microservices from a mainframe monolith, and how to solve data challenges associated with such a migration.
AWS Blu Age solutions are suitable for peeling a mainframe monolith, for a hybrid solution, and for migrating incrementally only parts of the mainframe to AWS.
Mainframe Peeling Patterns
Peeling microservices from a mainframe monolith can be challenging because the source platform and associated programming languages are not service- or object-oriented. Nor do they promote external data sharing and remote procedure call easily.
Mainframe monoliths have accumulated millions of lines of code with many programming styles and standards. That means automated code analysis and associated transformation capabilities are critical for success. It allows accommodating quickly the key differences between mainframe architecture and distributed platforms.
To deliver mainframe peeling projects, AWS Blu Age solutions enable three different patterns through the usage of Blu Age Analyzer technology. Depending on the workload or monolith size and complexity, one or multiple patterns can be combined to cover most situations.
Blu Age Analyzer has been specifically designed to identify each pattern and create an overall strategy for peeling any monolithic application.
Peel with Data-Independent Services
This is a favorable pattern where the extracted service and monolith have independent data dependencies. Programs are grouped into a domain, forming the boundaries of the microservice. Domain boundaries are defined around low coupling interfaces, such as file transfer, message queuing, reports, and business intelligence queries.
The data model is strictly consistent within each domain, within the remaining monolith data store, and within the microservice data store. One data-independent microservice is extracted and moved to AWS.
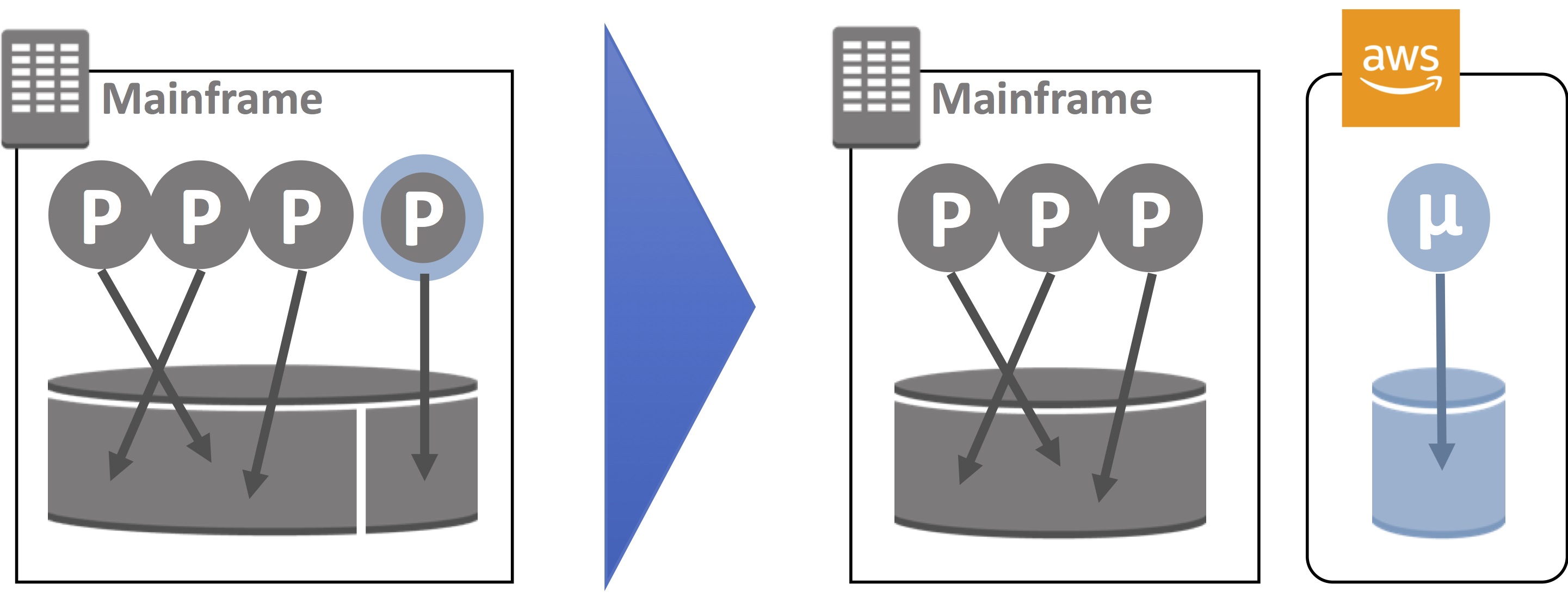
Figure 1 – Peel with data-independent services.
Peel with Data Eventual Consistency
This is a pattern where there are data dependencies between the extracted service and monolith. Data is replicated across the mainframe and AWS. It avoids network latency or jitter, which would be unmanageable for typical I/O-intensive mainframe batch programs, or detrimental to high throughput online backend transactions.
One data-dependent service is extracted and moved to AWS, and dependent data is asynchronously replicated both ways in real-time. Because of the bi-directional asynchronous replication, there is data eventual consistency. For conflict resolution, based on workload analysis and access types, strategies such as mainframe-as-a-reference or Last Write Win can be adopted.

Figure 2 – Peel with data eventual consistency.
Group Then Peel with Data Strict Consistency
When there are too many write dependencies or strong transactionality requirements, eventual consistency can become a challenge. In this pattern, groups of programs and their data dependencies are moved altogether in order to preserve strict consistency.
Data-dependent programs are grouped in data-independent groups. One data-independent group is extracted and moved to AWS microservices with a shared data store. Eventually, individual microservices may benefit from a separate deployment stack or data store.

Figure 3 – Group then peel with data strict consistency.
Peeling Microservices with Blu Age Analyzer
A microservice architecture decomposes applications into loosely-coupled business domains. The idea is that any team responsible for a domain may change how things are done inside the domain without impacting other application domains it interacts with. When peeling a monolith, one must identify the various domains and associated boundaries.
Blu Age Analyzer relies on the preceding patterns to define the microservices decomposition. Afterwards, Blu Age Velocity automates the modernization refactoring.
We’ll now describe the steps taken with Blu Age Analyzer to identify microservice domains.
Step 1: Vertical Analysis
Blu Age Analyzer automatically identifies all entry points into the system and organizes the dependencies into concentric rings. Microservices appear as local trees starting from the outside. At this stage, there are still some coupling elements that appear in the inner layers identified by the green zone in Figure 4. This analysis stage is fully automated.
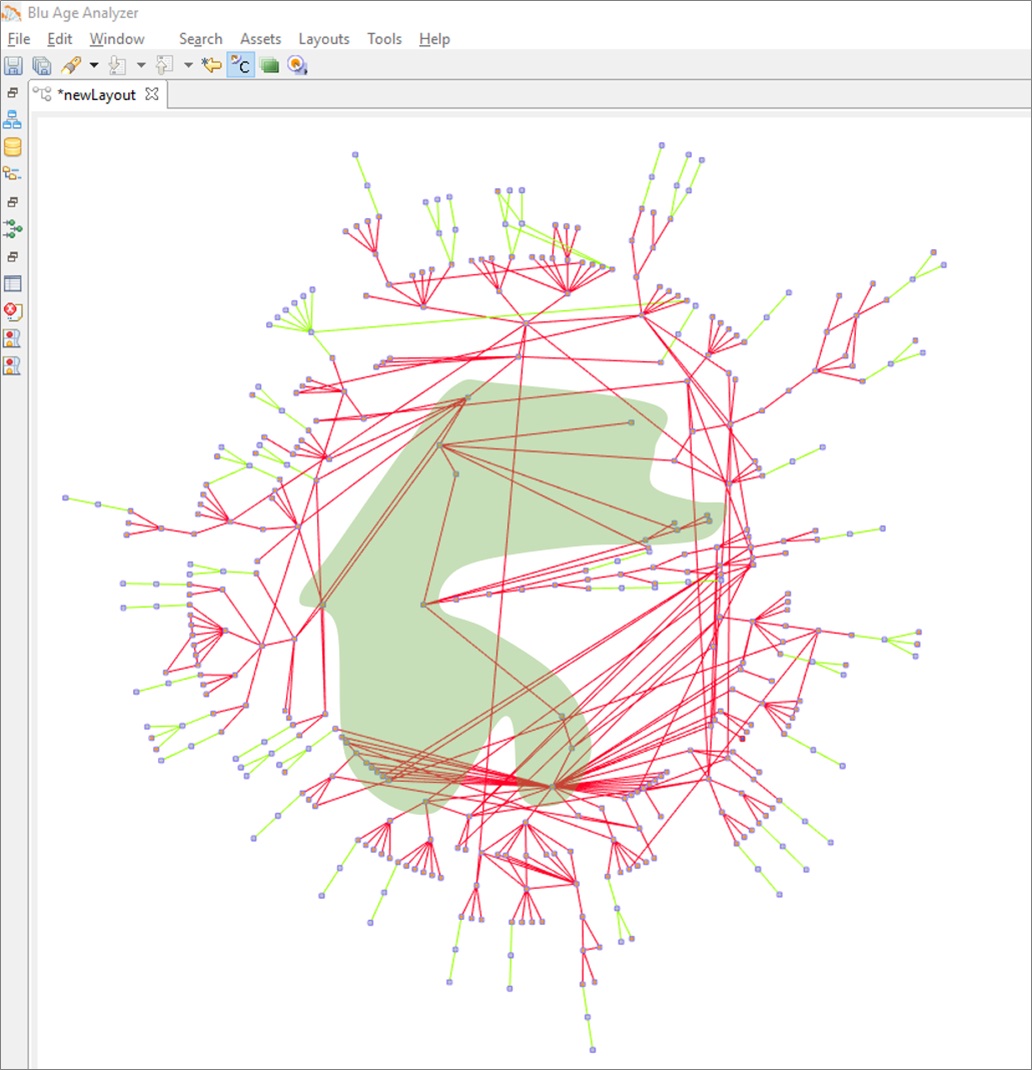
Figure 4 – Blu Age Analyzer vertical analysis.
Step 2: Business Domains Definition
During this step, dependencies to core programs are solved and individual domain boundaries are finalized. It leads to a starfish collaboration where few central domains (programs with very little code) contain utility programs and satellite domains contain the business logic. Satellite domains use central domains and collaborate directly with other satellite domains as well.
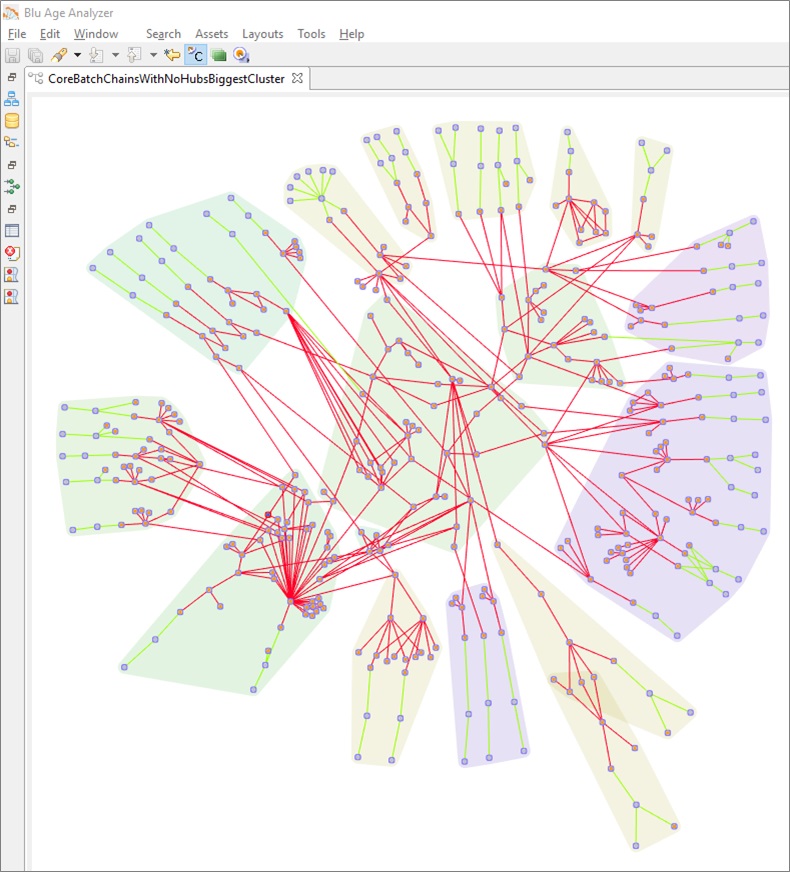
Figure 5 – Blu Age Analyzer detailed domain definition.
Domain decomposition and boundary detection is made by analyzing both caller/callee relationships, data access type, and data formats. The example in Figure 6 shows for a given program tree the data dependencies according to their data formats. It highlights the Virtual Storage Access Method (VSAM) and DB2 access types.

Figure 6 – Blu Age Analyzer data access types.
At this stage, a Blu Age Analyzer user may choose to alter boundaries definition. Typically, a user can adjust a domain based on business enhancements or to optimize API composition and data synchronization. This is common for microservices definition where boundaries are optimized through iterations.
Blu Age Analyzer facilitates this task using tags annotation. Domain boundaries adjustment effort is typically 1/2 man-day per million lines of code.
Step 3: Utility Domains Definition
Users must then decide to include the central utility domains as libraries within microservices or as real microservices of their own. These central domains usually become libraries since they usually do no I/O and contain only utility programs, which would likely be replaced by off-the-shelf frameworks when modernized.
Figure 7 shows the final decomposition with connections between domains with a single orange arrow per domain collaboration.
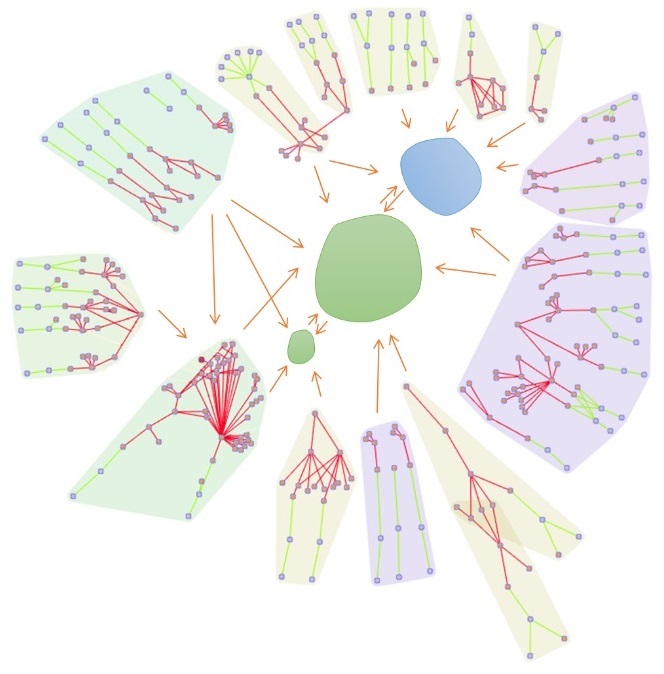
Figure 7 – Blu Age Analyzer final microservices decomposition.
Blu Age Velocity Microservice Design
Blu Age Analyzer not only facilitates the domains and microservices definition, but also calculates and drives the refactoring options. Blu Age Velocity then takes all these transformation options as inputs. It performs the automated refactoring of the complete software stack (code, data, data access, dependencies access, frameworks) to a pre-selected target stack based on Java, AngularJS, SpringBoot, Spring Statemachine, and REST APIs.
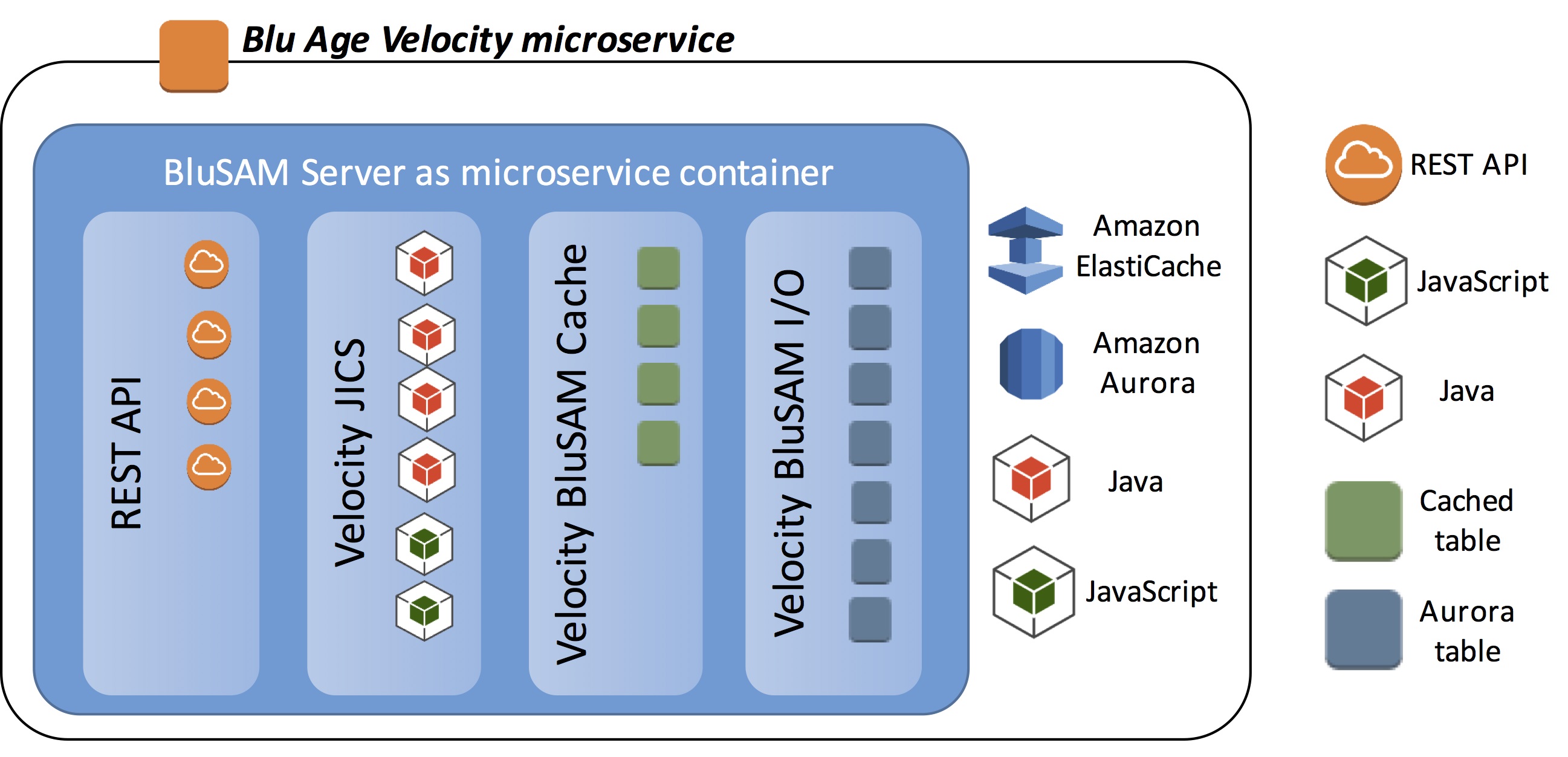
Figure 8 – Blu Age Velocity microservice design.
The BluSAM Server acts as a microservice container and has the flexibility to be deployed on various AWS compute services. It can also access data from various data services such as Amazon Aurora or Amazon ElastiCache. Velocity and BluSAM allow implementing the mainframe peeling patterns, as well as the database patterns described in this post.
Learn more about Velocity and BluSAM architecture on AWS in this APN Blog post.
Database Patterns Pros and Cons
One key decision to make when designing microservices is to choose the database pattern based on data consistency requirements. Financial systems or lifesaving systems typically require the strongest consistency. Other systems may accept eventual consistency favoring performance, lower coupling, and business efficiencies.
The following table details what consistency support is associated with database and peeling patterns.
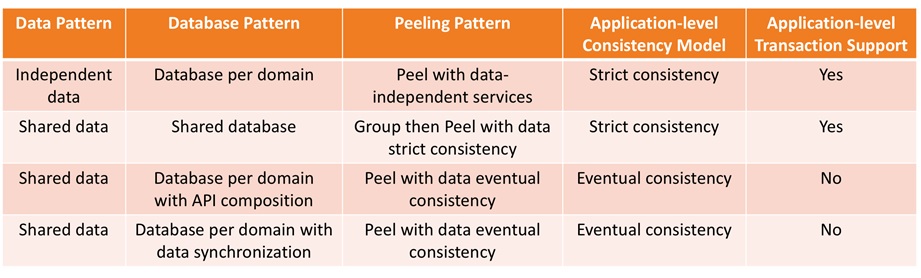
Figure 9 – Consistency and transaction support per peeling pattern.
Strict consistency and ACID (Atomicity, Consistency, Isolation, Durability) transaction support provide automatic transaction roll-back in case of failure. It’s performed transparently by the database and transaction servers for the application.
On the contrary, eventual consistency cannot use such transaction feature and requires additional application code or mechanisms to manage failure. For example, with API composition the Try-Cancel/Confirm (TCC) pattern or Saga pattern may be implemented to remediate failures. With data synchronization, replication retry and conflict resolution strategies may be implemented.
The Shared Database pattern preserves strict consistency and transaction support. It is therefore appealing when transitioning from mainframe to AWS in hybrid mode. This minimizes the need for manual code changes and leverages refactoring automation well, which is the reason it often reduces risks to first use the shared database pattern and then move on to using the database per domain pattern, if needed.
The Database-Per-Domain patterns require explicit domain boundaries. These are typically defined iteratively with complex manual refactoring until boundaries are eventually stable. Usually, the Data Synchronization Pattern is preferred over API composition, as it provides better performance, agility, and accommodate mainframe workload batches.
Data Replication Architecture
In many cases, the Independent Data or Shared Database patterns are preferred in order to keep strict consistency and let the database manage failure management or transaction recovery. This means the “Peel with Data-Independent Services” and “Group Then Peel with Data Strict Consistency” patterns are chosen and no data replication is necessary.
For the cases where the “Peel with Data Eventual Consistency” pattern is chosen, the Database-Per-Domain pattern does not allow a domain accessing data of another domain directly. Therefore, users must keep some data in each domain database synchronized.
Figure 10 shows the overall approach to consume microservices while synchronizing duplicated shared data. Microservices are deployed independently with their own database, and services are exposed as REST API to do API composition. Typically, users may use AWS API Gateway to consume REST services and do the composition.
No data update API is exposed to perform the data synchronization, and data replication is achieved under the hood using Change Data Capture (CDC) and Event Propagation.
- Change Data Capture: A data state change is identified on source database and triggers an action allowing distributed architecture to synchronize data in the right sequence.
- Data Event Propagation: The replication engine or distributed event broker transports data from the CDC to all target databases. It must guarantee message delivery, automatic scaling, message journaling (persistence), and message sequencing.
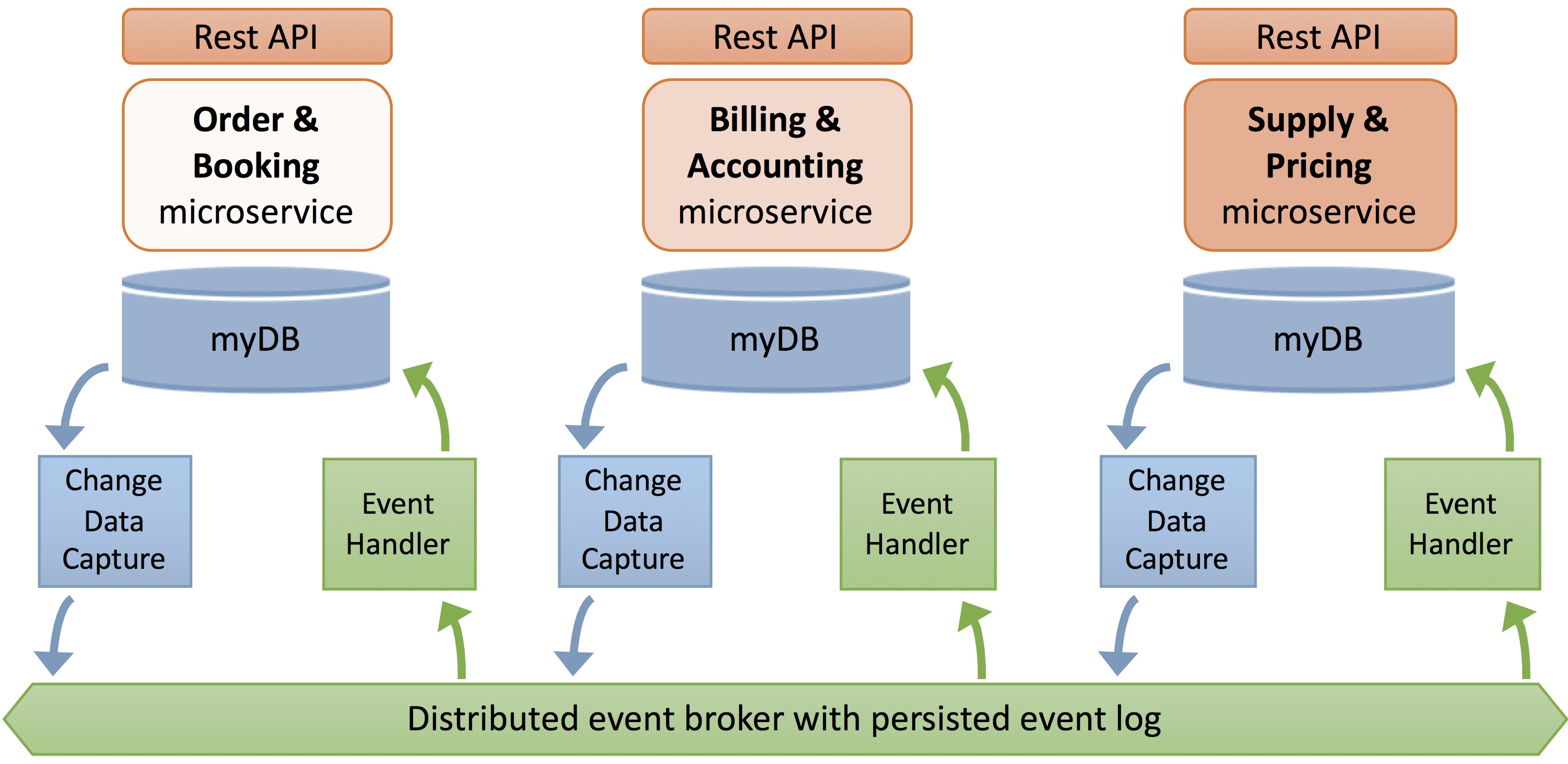
Figure 10 – Data replication using change data capture and event handling.
For mainframe-to-AWS data replication, there are several packaged vendor solutions available to do CDC-based, real-time asynchronous data replication. They typically support relational, hierarchical, and file-based mainframe data stores, and they replicate data to AWS data stores such as Amazon Relational Database Service (Amazon RDS), Amazon Aurora, or Amazon Kinesis.
Depending on specific requirements, several solutions or components can be combined to reach to desired target, such as Amazon DynamoDB, or to meet quality of service requirements.
For AWS-to-mainframe data replication, packaged vendor solutions can be used from many AWS data stores to many mainframe legacy data stores. Also, native AWS services can be used leveraging triggers for CDC, messaging services such as Amazon Simple Queue Service (Amazon SQS), Amazon MQ, and Amazon Kinesis for asynchronous invocations, and native mainframe drivers for updating legacy data stores.
For AWS-to-AWS data replication, when at least two microservices are deployed on AWS, the native AWS managed services can be used leveraging triggers and messaging services.
Next Steps
This post focused on how to peel microservices from a mainframe monolith and how to deal with the data dependencies, especially with the database per domain pattern. To learn more about microservices, domains, and bounded context, check out the following articles:
If you’d like to learn about a mainframe workload refactored to a microservice architecture on AWS, you should read How to Migrate Mainframe Batch to Cloud Microservices with Blu Age and AWS.
To request a demo of peeling a mainframe monolith with Blu Age Analyzer and Velocity, please contact us.