AWS Partner Network (APN) Blog
Scalable and Rapid ERP Analytics with Palantir HyperAuto on AWS
By Tom Pearson, Lead Architect – Palantir
By Mehmet Bakkaloglu, Sr. Solutions Architect – AWS
By Francesco Polimeni, Sr. Solutions Architect – AWS
 |
| Palantir |
 |
It’s no secret that data is the most important resource available to modern institutions. Many have it in spades: structured, unstructured, transactional, geospatial, to name a few.
The challenge is not necessarily generating, cataloging, or storing data, but operationalizing it. Palantir Foundry is an operations platform that leverages existing data systems and analytics tooling to power smarter decision-making. It fuses analytics with operations, leveraging write-back and learning loops to create compounding value over time.
The first step to operationalizing data against pressing problems is integration. Data integration is typically time consuming, manually intensive, and often requires expertise in the underlying data structure.
Palantir HyperAuto leverages Palantir’s Software-Defined Data Integration (SDDI) technology to solve this problem—building pipelines from source systems without the need for engineers to write a single new line of code.
One such source system commonly found in large organizations is an enterprise resource planning (ERP) system. Organizations often have multiple ERP systems running on various versions due to mergers and acquisitions.
Palantir HyperAuto utilizes SDDI to automate data ingestion, transformation, and modeling. It gives instant 360-degree views of key business themes: cost of goods sold (COGS), inventory, plants, warehouses, products, and so on. It enables dynamic “what-if” scenario testing to identify opportunities to increase sales, optimize product mix, and reduce costs. Following this, Foundry writes back to source systems for continuous learning.
In March 2021, Palantir unveiled the Foundry ERP Suite (now packaged with HyperAuto) to deliver cost savings for Amazon Web Services (AWS) customers. In this post, we provide an overview of the solution with a focus on SAP and explain how Foundry running on AWS delivers scalability.
Palantir and AWS
Palantir, an AWS Partner with an AWS-qualified software offering, builds software that lets organizations integrate their data, their decisions, and their operations.
Palantir Foundry deployed on AWS leverages core services such as Amazon Simple Storage Service (Amazon S3), Amazon Elastic Compute Cloud (Amazon EC2), Amazon EC2 Auto Scaling, Elastic Load Balancing (ELB), Amazon Relational Database Service (Amazon RDS), and AWS Key Management Service (AWS KMS) to provide a scalable and cost-effective platform.
AWS is also the platform of choice and innovation for 5,000+ SAP customers and hundreds of partners. The Foundry ERP Suite supports most versions of both SAP ERP Central Component and S/4HANA. Customers who have their SAP workloads running on AWS benefit from improved latency when ingesting data into Foundry.
Palantir HyperAuto Overview
Palantir HyperAuto has three core components: source system connector, source data explorer, and automated pipeline generator. To take a concrete example, let’s examine each of these components through the lens of working with SAP data.
The SAP-certified connector, developed in partnership with Diskover Limited, is installed using SAINT (SAP Add-on Installation Tool). Once set up, users can configure “syncs” to securely import data from SAP ECC or S/4HANA, BW (Business Warehouse), and SLT (SAP Landscape Transformation Replication Server).
Write-back functionality to SAP systems is achieved utilizing remote-enabled function modules in SAP—typically BAPI (Business Application Programming Interface) functions.
The Palantir HyperAuto Source Explorer for SAP ERP provides an intuitive interface to examine the contents of an SAP system and bulk create data extracts for specific use cases or workflows with a few clicks. It leverages source system metadata, removing the need for SAP expertise.
Within the interface, users can:
- Seamlessly browse SAP Modules (Material Management or Sales Distribution, for example) and drill down to discover all associated common objects (such as Material, Vendor, or Purchase Order) and ERP tables.
- Inspect the schema of a given table and preview a set of records to better understand the data before extracting.
- Utilize the comprehensive search function to find other SAP tables outside of predefined modules.

Figure 1 – Palantir HyperAuto Source Explorer for SAP ERP.
The Palantir HyperAuto Automatic Pipeline Generator produces a complete, efficient pipeline out-of-the-box to process and transform the SAP data into a usable form. It also dynamically generates a set of object types (mapped to real-world concepts such as materials, customers, and sales orders) complete with predefined properties and relationships.
In the Foundry Data Lineage module shown in Figure 2 below, users can view a representation of the transformations from source to destination. The brown boxes on the left are the SAP data extracts; the green boxes in the middle are the data pipelines that have been automatically constructed; and the black-and-yellow boxes on the right are the object types.
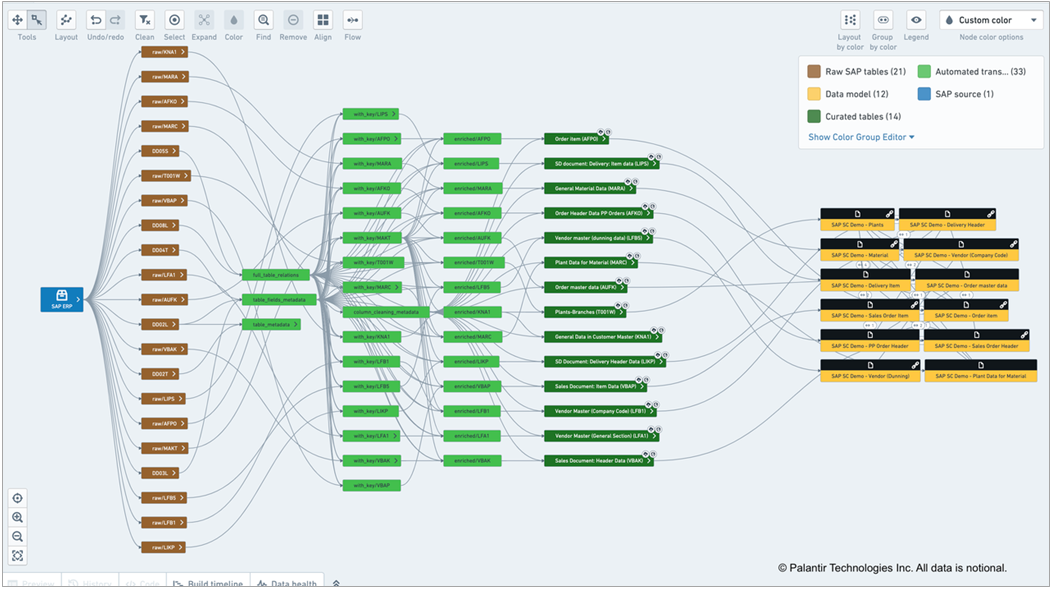
Figure 2 – Lineage of the automatically generated data pipeline.
Architecture and Scalability
Large enterprises typically have multiple ERP systems with many millions or billions of records. Processing such data for analytics involves operations such as denormalization, mapping, and deduplication, which require highly scalable compute power.
Moreover, enterprises are increasingly relying on data from their suppliers and/or customers to improve supply chain visibility, which further drives up the data scale.
All of this requires an architecture that can scale. Palantir HyperAuto—powered by Foundry running on AWS—is designed for this.
In 2017, Palantir started the Rubix project to create a secure, scalable, and intelligent scheduling and execution engine for Spark and other distributed compute frameworks. Rubix has been implemented following the Spark-on-Kubernetes specification to satisfy two critical requirements: (1) multi-tenant security in the presence of user-authored code, and (2) predictable performance.
Deployed on multiple AWS regions, Rubix manages clusters of different sizes and scale—from tens to thousands of nodes—and has been designed to run on ephemeral infrastructure, where each Amazon EC2 instance is recycled every 48-72 hours.
The design of the Rubix engine introduced the following benefits:
- Improved security posture as newly patched Amazon Machine Images (AMIs) are automatically deployed in the 48-72 hours recycle, and long duration malware attacks cannot rely on EC2 instances that are periodically destroyed.
- Capacity optimization of EC2 instances by adopting Auto Scaling groups with multi-instance type.
For a detailed description of the Rubix project, refer to the following resources:
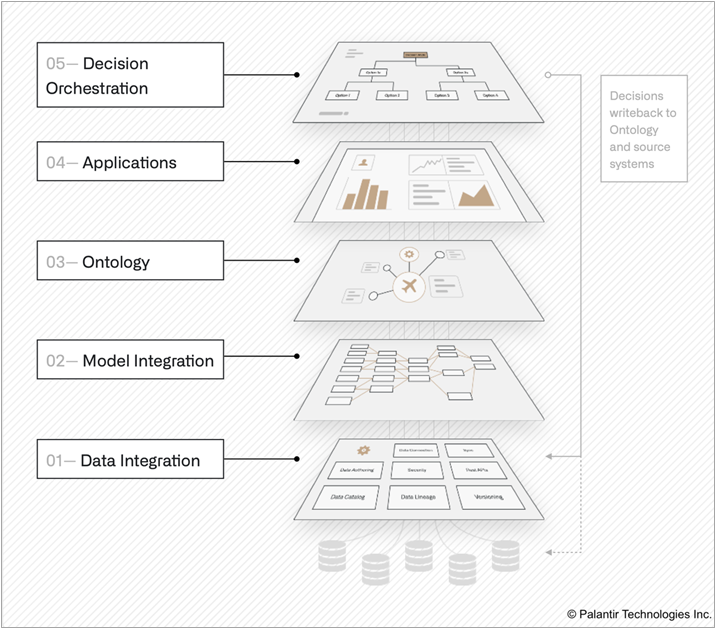
Figure 3 – Palantir Foundry architecture.
Integration with Other Data
Palantir has been developing software that integrates data from source systems since the company’s inception in 2004. First with Gotham and subsequently with Foundry.
Today, Palantir Foundry has connectors to 200+ different source systems, including software-as-a-service (SaaS) applications, on-premises applications, as well as other AWS services. For instance, Foundry can ingest data from AWS IoT services, Amazon Kinesis, Amazon S3, Amazon RDS, and more.
Coupled with the Foundry ERP Suite, these connectors allow Palantir to rapidly construct a holistic view of all data assets of an organization—for example, integrating SAP data with IoT data to support a broad range of use cases.
Business Use Cases
At Doosan Infracore, a global industry leader in heavy machinery manufacturing, Palantir Foundry is used to create a data foundation by integrating data across the value chain—from product development to production, and from sales to quality maintenance.
This data foundation powers workflows in areas such as new product development, supply chain management, and aftermarket and product support.
Applications
With a unified data model in Foundry, customers can take advantage of AWS services, such as Amazon SageMaker, to build machine learning models and integrate those models back into Foundry.
In Foundry, customers can also rapidly deploy Archetypes, pre-built templates—powered by the data model—for specific business use cases, such as supply chain resiliency, carbon footprint monitoring, quality in manufacturing, anti-money laundering, and asset 360 for utilities.
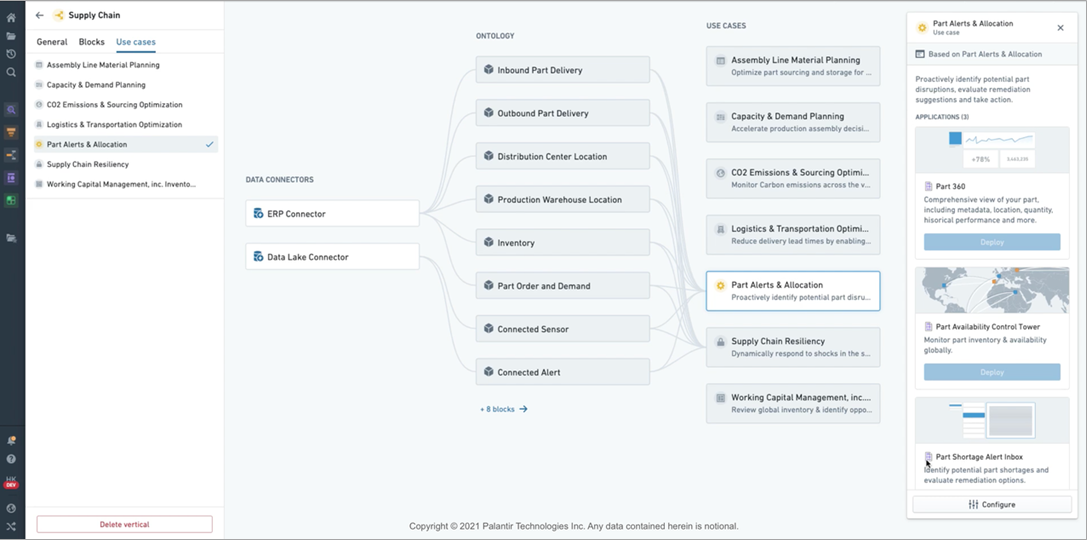
Figure 4 – Palantir Foundry Archetypes.
Conclusion
In this post, we explored how Palantir HyperAuto—powered by Foundry on AWS which provides a highly scalable architecture—can rapidly integrate data from ERP systems and operationalize that existing data against pressing business problems
Because HyperAuto integrates data in a software-defined way, it removes the technical barrier to entry of traditional data analytics, empowering business users, IT, and operators to work from a collaborative source-of-truth.
Most importantly, it enables enterprises to improve their operations in hours or days, not months and years.
.

.
Palantir – AWS Partner Spotlight
Palantir is an AWS Partner that builds software that lets organizations integrate their data, their decisions, and their operations.
Contact Palantir | Partner Overview
*Already worked with Palantir? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.