AWS Partner Network (APN) Blog
WANdisco Accelerates GoDaddy’s Hadoop Cloud Migration to AWS Without Business Interruption
By Paul Scott-Murphy, VP Product Management at WANdisco
By Jeremy Zogg, Sr. Director Engineering at GoDaddy
By Roy Hasson, WW Analytics Specialist Leader at AWS
 |
Organizations collect and store vast amounts of data that is processed and analyzed throughout each day in order to deliver fresh actionable insights. As business requirements evolve, however, organizations are faced with a need to collect and store even more data from diverse sources.
To manage the ever-increasing volume of data and demands from the business, organizations build and maintain large Hadoop clusters. These primarily reside on-premises and have become a major burden requiring costly upgrades to hardware and software, ongoing maintenance, and a dedicated team of engineers.
Amazon Web Services (AWS) offers organizations a solution to these challenges by providing managed services that are automatically scalable, highly available and durable, and take care of all the heavy lifting so that users can focus on high value tasks.
Moving big data workloads to AWS allows organizations to become more agile and innovative while enabling their users with a self-service approach to consuming data and insights. This can improve overall efficiency and speed of the business, but the majority of data is still being collected and stored on-premises and that contributes to the data gravity challenge.
For organizations to be successful in modernizing their data ecosystem, they must shift this data to the cloud. In this post, we will look at a real-world example of how WANdisco migrated GoDaddy’s big data environment to AWS.
We’ll analyze what it took to migrate their 2.5PB of data residing on an 800-node Hadoop cluster running thousands of SLA-bound jobs around the clock to Amazon Simple Storage Service (Amazon S3).
We’ll also compare WANdisco’s LiveData strategy to traditional approaches used for data migration, and demonstrate how the legacy approaches are unable to cope with actively changing datasets at scale.
WANdisco, an AWS Advanced Technology Partner with the AWS Migration Competency, is a leading data lake migration and replication platform, ensuring zero downtime or data loss.
How Big is Big Data?
What does a large, real-world, big data environment look like? Every data storage and processing cluster is different, but an example that helps to explain the unique challenges at scale comes from our work with GoDaddy.
GoDaddy runs an Apache Hadoop cluster in their own data center with 800 nodes to service large-scale production data storage, processing, and analytic needs. It holds about 2.5PB of data, growing by more than 4TB every day.
Like any production environment, it requires constant maintenance which incur further operational expense. Hadoop clusters run hot, and this one is no exception.
One measure of this activity is the rate of change in the file system. Figure 1 shows a moving average of file system change operations per second over 12 hours. It performs an average of 21,388 file system change operations every second, and experiences peaks 5x that rate.
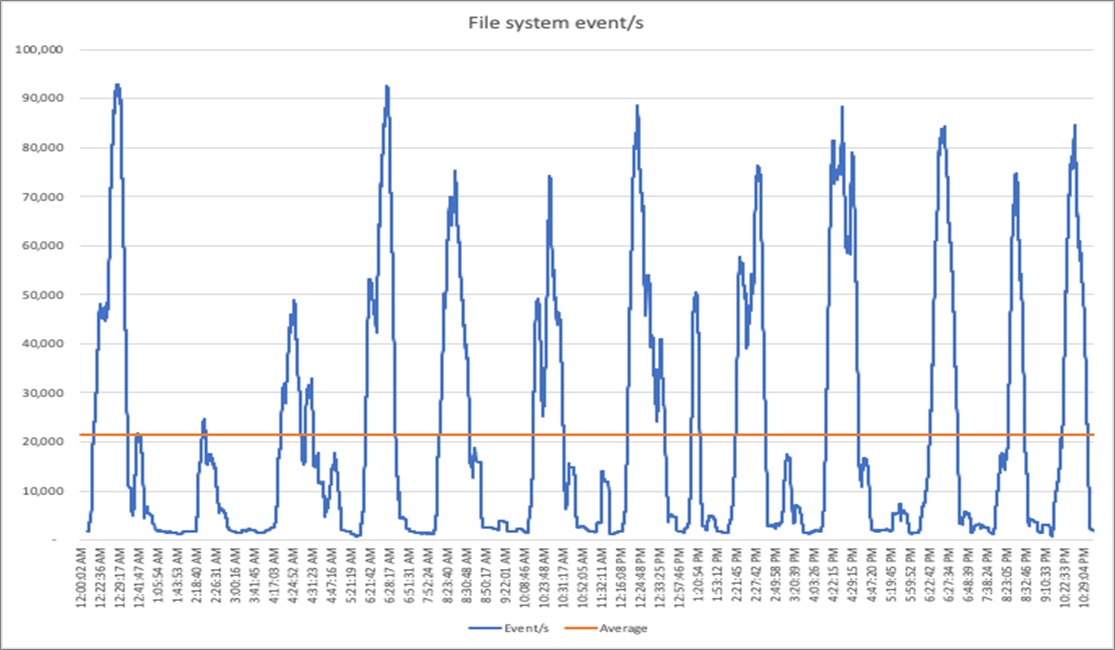
Figure 1 – Average file system rate of change.
Big Data Migration
Although GoDaddy’s cluster has been operating successfully for years, they wanted to take advantage of AWS managed services. Migrating petabytes of continuously changing data is risky and can pose many challenges, such as maintaining application continuity, meeting SLAs, and making sure data quality is not degraded.
Any potential disruption to business operations may prevent a migration from even being attempted. Therefore, the data migration service used must be transparent to the Hadoop cluster and resilient to reduce any potential impacts.
Requirements
GoDaddy’s initial goal was to migrate 500TB of data spread over 8.6 million files to Amazon S3, allowing them to run production workloads using Amazon EMR to validate operation and performance before migrating the remaining data.
The efforts must not impact existing workloads or performance of the Hadoop cluster. Bandwidth dedicated to data migration was constrained to a third of the available 10 Gb/s network connection to AWS.
Cluster Activity
In such a large environment, with thousands of jobs and hundreds of users, data is constantly changing. This results in extremely high rate of file system activity.
For the evaluation, the focus was on 500TB of data supporting several heavily used tables resulting in an average of 50 events per second.
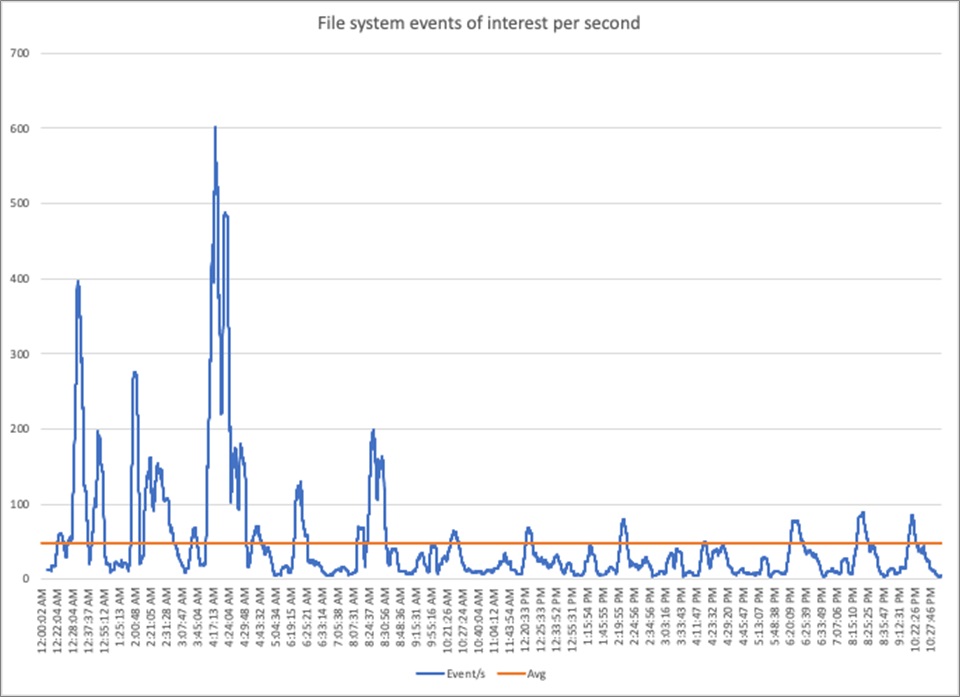
Figure 2 – Number of file data system changes.
Interestingly, there’s a lot of variance in this activity. While the average is about 50 events per second, peaks can be up to 10x, and vary drastically over time.
We also wanted to understand the size distribution across all of the files comprising the 500TB we want to migrate.
The graph in Figure 3 shows the distribution of file sizes for a sample of 10,000 files, bucketed into eight groups. Each group represents the percentage of data volume that it contributes to the total amount of data to be migrated.
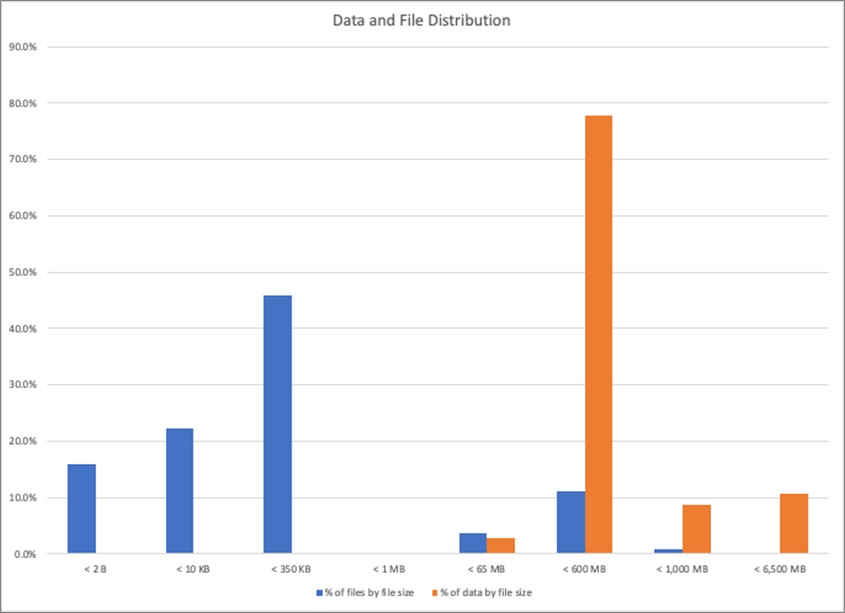
Figure 3 – File size distribution.
We can see that while the majority of files are small (84 percent are less than 350 KB), the majority of data reside in files between 65MB and 600MB in size.
Hadoop clusters operate most efficiently when files are at least the size of a single HDFS block—by default 128MB. In the real world, however, clusters are not always used efficiently. This graph is a clear indication you can expect to see many small files even when most of your data reside in larger files.
What Happens During Data Migration?
Now that we know what the cluster, data, and file system activity look like, we can plan for what needs to happen during data migration.
- Existing datasets need to be copied from HDFS to Amazon S3, with each file in HDFS transferred to an object in S3 with an identifier that distinguishes the full path to the source file. This is the same approach used by AWS S3A filesystem interface to represent S3 storage as a Hadoop-compatible file system.
.
Because we need to migrate a lot of data over a fixed bandwidth (3 Gb/s), this will take time. During that time, the data will continue to be modified, moved, and deleted.
. - Changes made in HDFS to those datasets need to be applied to the replica of the data in Amazon S3 to maintain consistency. The business cannot stop just to migrate.
Sending 500 TB of data at 3 Gb/s should take about 15.4 days. We can assume changes made to the data don’t materially increase or decrease the total size of data being transferred.
Together with the knowledge of file size distribution and the total number of files, over the course of 15.4 days we can estimate:
- 66.5 million file change events
- About 13.3 TB of data (using the median file size of 200 KB) will be modified.
With a fixed bandwidth, we can calculate the total amount of time required to migrate the data and ongoing changes in the same way as calculating compound interest. We estimate the total data that will be transferred is 513.5 TB, and is expected to take 15.8 days.
Migration Limits
With 8.6 million files and 500 TB of data, migration can be limited by available bandwidth, latency, and the rate at which files can be created in Amazon S3.
The calculations above assume there is no cost or overhead in determining the changes that occur to the data being migrated. This requires a “live” data migration technology that combines knowledge of the data to be migrated with the changes that are occurring to it without needing to repeatedly scan the source to determine what was changed.
API Rates
Amazon S3 allows you to send 3,500 PUT/COPY/POST/DELETE API requests per second per prefix for an S3 bucket. A prefix is a logical grouping of the objects in a bucket. The prefix value is similar to a directory name that enables you to store similar data under the same directory in a bucket.
This migration had 15 prefixes, so at best the API rate would be 52,500 PUT requests per second. The system needed to perform one PUT request per file, and one per file changing event, for a total of 75.1 million PUT requests. With this volume, we didn’t expect the S3 API rate to be a limiting factor.
Latency
Rate Limits
The latency between the cluster and Amazon S3, and the extent to which those requests can be executed concurrently, may limit operation. A migration solution needs to ensure sufficient request concurrency can be achieved.
GoDaddy’s cluster was 1,800 Km from their chosen S3 region, which imposes a round-trip latency of 23ms.
With no concurrency, and a 23ms round-trip latency, 75.1 million requests will take 20 days to perform. This is more than the time required to send 500 TB, so it will be a limiting factor without concurrent requests. Any solution needs to execute requests concurrently to achieve 3 Gb/s in this environment.
Throughput Limits
A second impact of latency is the TCP throughput limit it imposes. This is the standard window-size / round-trip-time tradeoff, where for a fixed window size, increased latency limits the achievable throughput for a single TCP connection.
Once again, assuming a 23ms round-trip latency, for a standard packet loss estimate of 0.0001 percent, an MTU of 1500 bytes, and a TCP window size of 16,777,216, the expected maximum TCP throughput for a single connection is 0.5 Gb/s.
Again, concurrent TCP connections will be needed to achieve throughput at the 3Gb/s rate.
Amazon S3 API Overhead
Because the S3 API requires at least a PUT operation per file created, there is overhead in the HTTP request made to create an object that totals about 1,800 bytes per request, although this can differ based on the object identifier used.
When the majority of files are significantly larger than 1,800 bytes, this does not impact throughput. But when many files approximate that size or below, it can have a large impact on the content throughput achievable.
For GoDaddy’s file distribution, the median file size is 200 KB, of which 1800 bytes represents a one percent overhead, which is essentially insignificant compared to bandwidth requirements. However, there are limits to the number of concurrent requests that can be dedicated to servicing small files.
Migration Approaches
Traditional Migration
With sufficient use of concurrent requests and TCP optimizations, there was no impediment to achieving the target 3Gb/s and completing the data transfer in under 16 days. We also needed to consider how the solution accommodates the changes that occur to data while migration is underway.
An approach that does not take changes into account during operation will need to attempt to determine what differs between the source cluster and the target S3 bucket. This can be done by comparing each file/object and transferring any differences after an initial transfer has occurred. It’s complex and error prone, however, and thus highly discouraged.
Migration of a Subset of Data
Migrating 500TB of static data at 3 Gb/s will take 15.4 days, but datasets continue to change during that time. If there is no information available about exactly what has changed, the source and target need to be compared.
That comparison needs to touch every file (8.6 million), and if performed in sequence will take 55 hours. During that time, data will continue to change, and without a mechanism to capture those specific changes, we’ll need to return again to the data and compare it in total again.
The average rate of change for a selected 500 TB of the 2.5 PB of total data was just 50 events per second. During 55 hours, we can expect about 10.1 million changes to files, and about 2 TB of data to have been modified.
Migration of All Data
The change rate climbed exponentially as the data volume to be migrated increased. What was 50 events per second for 500 TB of data became 21,388 events per second for 2.5 PB of data—a 42,776 percent increase!
The comparison of all data will need to touch 5x as many files (now 43 million), and if performed in sequence will take about 10 days, even before transferring any changed data. At the change rates for the GoDaddy example, this would be another 10TB of data, which itself will take more than seven hours.
Accommodating that change rate requires sophisticated techniques for obtaining, consuming, and processing events of interest if they are needed to drive a LiveData migration solution.
A LiveData Strategy
If the migration technology does not depend on comparing source and destination data to confirm changes, it can drastically increase migration speed and improve reliability.
This requires bringing together information about file system changes and the makeup of the underlying data in order to make optimal replication decisions in real-time.
This is not just simple change data capture, but the use of a continuous evaluation of change notifications with the scan of the data that are undergoing change. The only limit that’s imposed is to ensure the rate of change to the source data is less than the bandwidth available.
For GoDaddy, the rate of change of their full cluster is about 4.3 TB of data per day, or 0.4 Gb/s. This is well within their available bandwidth, so a LiveData strategy is a feasible approach, allowing them to move from an RPO of 10 days to essentially zero.
GoDaddy used WANdisco’s LiveData Migrator to migrate data from their production cluster to Amazon S3. It combined a single scan of the source datasets with processing of the ongoing changes to achieve a complete and continuous data migration.
LiveData Migrator does not impose any cluster downtime or disruption, and requires no changes to cluster operation or application behavior.
LiveData Migrator enabled GoDaddy to perform their migration without disrupting business operation. It provided peace of mind that their data was transferred completely and consistently, even under heavy production use.
Summary
In this post, we reviewed how GoDaddy was able to migrate data from their 800-node, 2.5 PB production Apache Hadoop cluster to Amazon S3. They were able to do so without any downtime or disruption to applications or the business using WANdisco’s LiveData Migrator product.
Advances in migration technology mean the capabilities now exist to migrate data from actively-used Hadoop environments at scale to the cloud. You can benefit from AWS managed services, pace of innovation, and improve costs for your largest and most complex analytic workloads.
Visit wandisco.com or AWS Marketplace to find out more about the details of LiveData Migrator, and try it for yourself for up to 5TB of data at no cost.
.

.
WANdisco – AWS Partner Spotlight
WANdisco is an AWS Migration Technology Competency Partner that focuses on big data migration with a proven data migration and analytics practice for Amazon S3 and Amazon EMR.
Contact WANdisco | Partner Overview | AWS Marketplace
*Already worked with WANdisco? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.