AWS News Blog
Amazon Aurora Update – PostgreSQL Compatibility
Just two years ago (it seems like yesterday), I introduced you to Amazon Aurora in my post Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS. In that post I told you how the RDS team took a fresh, unconstrained look at the relational database model and explained how they built a relational database for the cloud.
The feedback that we have received from our customers since then has been heart-warming. Customers love the MySQL compatibility, the focus on high availability, and the built-in encryption. They count on the fact that Aurora is built around fault-tolerant, self-healing storage that allows them to scale from 10 GB all the way up to 64 TB without pre-provisioning. They know that Aurora makes six copies of their data across three Availability Zones and backs it up to Amazon Simple Storage Service (Amazon S3) without impacting performance or availability. As they scale, they know that they can create up to 15 low-latency read replicas that draw from common storage. To learn more about how our customers are using Aurora in world-scale production environments, take some time to read our Amazon Aurora Testimonials.
Of course, customers are always asking for more, and we do our best to understand their needs and to oblige. Here is a look back at some recent updates that were made in response to specific feedback from customers:
- October – Call Lambda Functions from Stored Procedures.
- October – Load Data from S3.
- September – Reader Endpoint for Load Balancing and Higher Availability.
- September – Parallel Read Ahead, Faster Indexing, NUMA Awareness.
- July – Create Cluster from MySQL Backup.
- June – Cross-Region Read Replicas.
- May – Cross-Account Snapshot Sharing.
- April – Cluster View in RDS Console.
- March – Additional Failover Control.
- March – Local Time Zone Support.
- March – Availability in Asia Pacific (Seoul).
- February – Availability in Asia Pacific (Sydney).
And Now, PostgreSQL Compatibility
 In addition to the feature-level feedback, we received many requests for additional database compatibility. At the top of the list was compatibility with PostgreSQL. This open source database has been under continuous development for 20 years and has found a home in many enterprises and startups. Customers like the enterprise features (similar to those offered by SQL Server and Oracle), performance benefits, and the geospatial objects associated with PostgreSQL. They would love to have access to these capabilities while also taking advantage of all that Aurora has to offer.
In addition to the feature-level feedback, we received many requests for additional database compatibility. At the top of the list was compatibility with PostgreSQL. This open source database has been under continuous development for 20 years and has found a home in many enterprises and startups. Customers like the enterprise features (similar to those offered by SQL Server and Oracle), performance benefits, and the geospatial objects associated with PostgreSQL. They would love to have access to these capabilities while also taking advantage of all that Aurora has to offer.
Today we are launching a preview of Amazon Aurora PostgreSQL-Compatible Edition. It offers all of the benefits that I listed above, including high durability, high availability, and the ability to quickly create and deploy read replicas. Here are some of the things you will love about it:
Performance – Aurora delivers up to 2x the performance of PostgreSQL running in traditional environments.
Compatibility – Aurora is fully compatible with the open source version of PostgreSQL (version 9.6.1). On the stored procedure side, we are planning to support Perl, pgSQL, Tcl, and JavaScript (via the V8 JavaScript engine). We are also planning to support all of the PostgreSQL features and extensions that are supported in Amazon RDS for PostgreSQL.
Cloud Native – Aurora takes full advantage of the fact that it is running within AWS. Here are some of the touch points:
- AWS Key Management Service (AWS KMS) – Encryption at rest.
- AWS Identity and Access Management (IAM) – Fine-grained access control to Aurora APIs and resources.
- Amazon Simple Storage Service (Amazon S3) – Aurora backs up your database to Amazon S3 continuously, and uses it for almost instant recovery.
- Amazon Relational Database Service (Amazon RDS) – Provisioning, backup management, monitoring, scaling of compute resources, managing database configurations.
- AWS Database Migration Service (AWS DMS) – Easy migration from on-premises or EC2-hosted PostgreSQL, Oracle, or SQL Server.
- AWS Schema Conversion Tool – Easy conversion from one database schema to another as part of a migration.
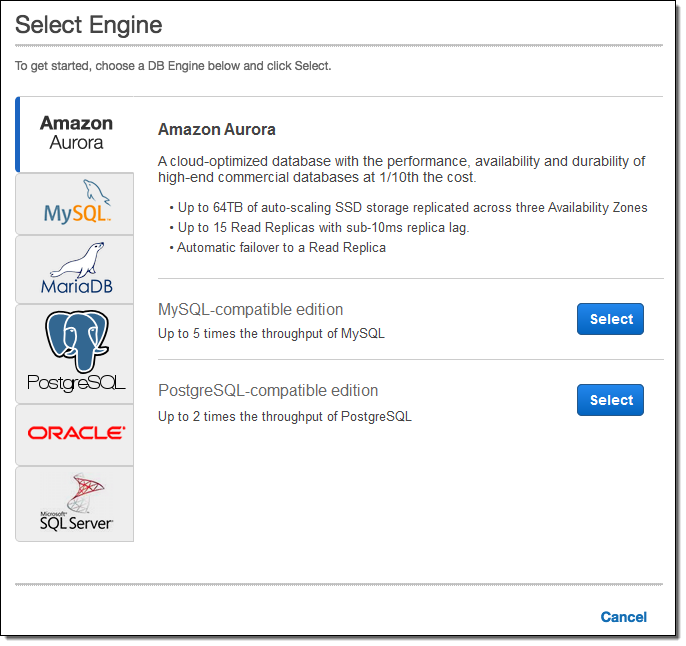
Here’s how you access all of this from the RDS Console. You start by selecting the PostgresSQL Compatible option:
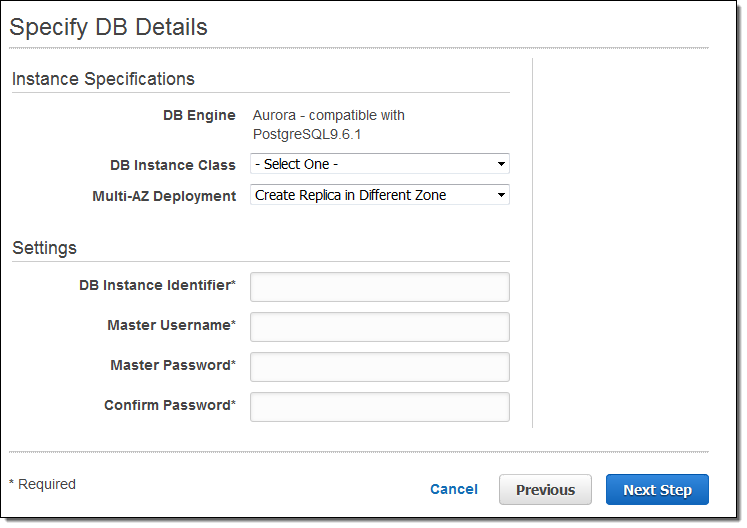
Then you choose your database instance type, decide on Multi-AZ deployment, name your database instance, and set up a user name & password:
We are making a preview of PostgreSQL compatibility for Amazon Aurora available in the US East (N. Virginia) Region today and you can sign up now for access!
A Quick Comparison
My colleagues David Wein and Grant McAlister ran some tests that compared the performance of PostgreSQL compatibility for Amazon Aurora against PostgreSQL 9.6.1. The database servers were run on m4.16xlarge instances and the test clients were run on c4.8xlarge instances.
PostgreSQL was run using 45K of Provisioned IOPS storage consisting of three 15K IOPS EBS volumes striped into one logical volume, topped off with an ext4 file system. They enabled WAL compression and aggressive autovacuum, both of which improve the performance of PostgreSQL on the workloads that they tested.
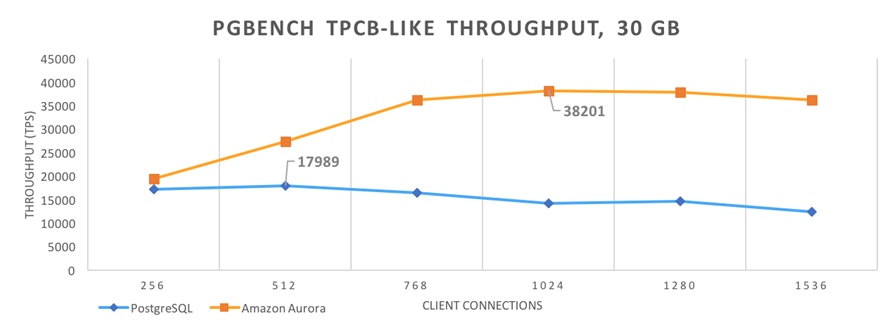
David & Grant ran the standard PostgreSQL pgbench benchmarking tool. They used a scaling factor of 2000 which creates a 30 GiB database and uses several different client counts. Each data point ran for one hour, with the database recreated before each run. The graph below shows the results:
David also shared the final seconds of one of his runs:
progress: 3597.0 s, 39048.4 tps, lat 26.075 ms stddev 9.883
progress: 3598.0 s, 38047.7 tps, lat 26.959 ms stddev 10.197
progress: 3599.0 s, 38111.1 tps, lat 27.009 ms stddev 10.257
progress: 3600.0 s, 34371.7 tps, lat 29.363 ms stddev 14.468
transaction type:
scaling factor: 2000
query mode: prepared
number of clients: 1024
number of threads: 1024
duration: 3600 s
number of transactions actually processed: 137508938
latency average = 26.800 ms
latency stddev = 19.222 ms
tps = 38192.805529 (including connections establishing)
tps = 38201.099738 (excluding connections establishing)
They also shared a per-second throughput graph that covered the last 40 minutes of a similar run:
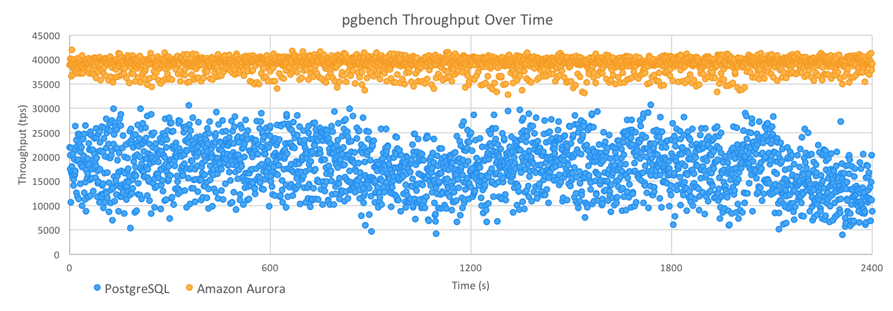
As you can see, Amazon Aurora delivered higher throughput than PostgreSQL, with about 1/3 of the jitter (standard deviations of 1395 TPS and 5081 TPS, respectively).
David and Grant are now collecting data for a more detailed post that they plan to publish in early 2017.
Coming Soon – Performance Insights
We are also working on a new tool that is designed to help you to understand database performance at a very detailed level. You will be able to look inside of each query and learn more about how your database handles it. Here’s a sneak preview screen shot:
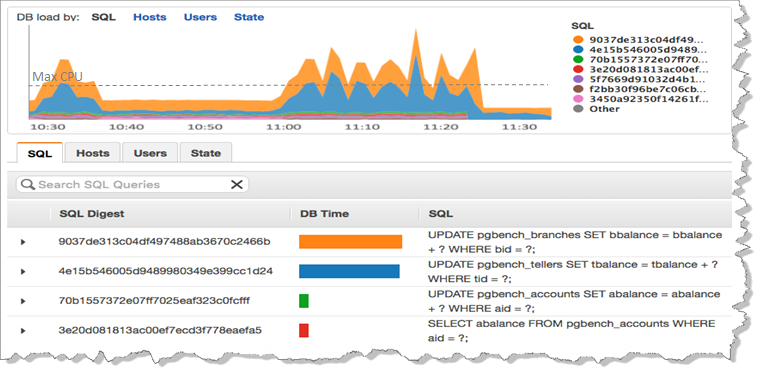
You will be able to access the new Performance Insights as part of the preview. I’ll have more details and a full tour later.
— Jeff;
Update! We have a webinar coming up on January 16th. Register for it here.