AWS News Blog
Building a Modern CI/CD Pipeline in the Serverless Era with GitOps

|
Guest post by AWS Community Hero Shimon Tolts, CTO and co-founder at Datree.io. He specializes in developer tools and infrastructure, running a company that is 100% serverless.
In recent years, there was a major transition in the way you build and ship software. This was mainly around microservices, splitting code into small components, using infrastructure as code, and using Git as the single source of truth that glues it all together.
In this post, I discuss the transition and the different steps of modern software development to showcase the possible solutions for the serverless world. In addition, I list useful tools that were designed for this era.
What is serverless?
Before I dive into the wonderful world of serverless development and tooling, here’s what I mean by serverless. The AWS website talks about four main benefits:
- No server management.
- Flexible scaling.
- Pay for value.
- Automated high availability.
To me, serverless is any infrastructure that you don’t have to manage and scale yourself.
At my company Datree.io, we run 95% of our workload on AWS Fargate and 5% on AWS Lambda. We are a serverless company; we have zero Amazon EC2 instances in our AWS account. For more information, see the following:
- Datree.io case study
- Migrating to AWS ECS Fargate in production
- CON320: Operational Excellence w/ Containerized Workloads Using AWS Fargate (re:Invent 2018)
What is GitOps?
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
According to Luis Faceira, a CI/CD consultant, GitOps is a way of working. You might look at it as an approach in which everything starts and ends with Git. Here are some key concepts:
- Git as the SINGLE source of truth of a system
- Git as the SINGLE place where we operate (create, change and destroy) ALL environments
- ALL changes are observable/verifiable.
How you built software before the cloud
Back in the waterfall pre-cloud era, you used to have separate teams for development, testing, security, operations, monitoring, and so on.
Nowadays, in most organizations, there is a transition to full developer autonomy and developers owning the entire production path. The developer is the King – or Queen :)
Those teams (Ops/Security/IT/etc) used to be gatekeepers to validate and control every developer change. Now they have become more of a satellite unit that drives policy and sets best practices and standards. They are no longer the production bottleneck, so they provide organization-wide platforms and enablement solutions.
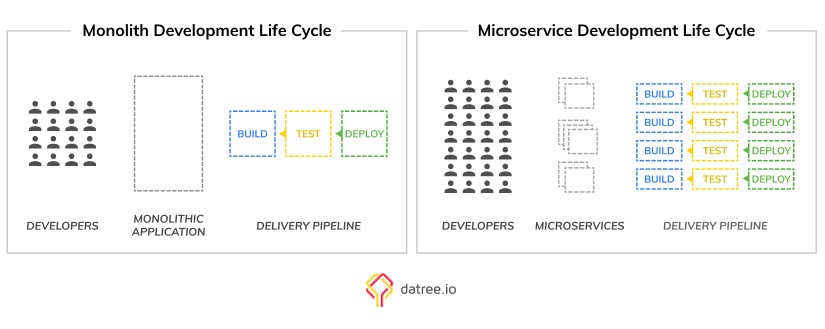
Everything is codified
With the transition into full developer ownership of the entire pipeline, developers automated everything. We have more code than ever, and processes that used to be manual are now described in code.
This is a good transition, in my opinion. Here are some of the benefits:
- Automation: By storing all things as code, everything can be automated, reused, and re-created in moments.
- Immutable: If anything goes wrong, create it again from the stored configuration.
- Versioning: Changes can be applied and reverted, and are tracked to a single user who made the change.
GitOps: Git has become the single source of truth
The second major transition is that now everything is in one place! Git is the place where all of the code is stored and where all operations are initiated. Whether it’s testing, building, packaging, or releasing, nowadays everything is triggered through pull requests.
This is amplified by the codification of everything.

Useful tools in the serverless era
There are many useful tools in the market, here is a list of ones that were designed for serverless.

Code
Always store your code in a source control system. In recent years, more and more functions are codified, such as, BI, ops, security, and AI. For new developers, it is not always obvious that they should use source control for some functionality.
Build and test
The most common mistake I see is manually configuring build jobs in the GUI. This might be good for a small POC but it is not scalable. You should have your job codified and inside your Git repository. Here are some tools to help with building and testing:
Security and governance
When working in a serverless way, you end up having many Git repos. The number of code packages can be overwhelming. The demand for unified code standards remains as it was but now it is much harder to enforce it on top of your R&D org. Here are some tools that might help you with the challenge:
Bundle and release
Building a serverless application is connecting microservices into one unit. For example, you might be using Amazon API Gateway, AWS Lambda, and Amazon DynamoDB. Instead of configuring each one separately, you should use a bundler to hold the configuration in one place. That allows for easy versioning and replication of the app for several environments. Here are a couple of bundlers:
Package
When working with many different serverless components, you should create small packages of tools to be able to import across different Lambda functions. You can use a language-specific store like npm or RubyGems, or use a more holistic solution. Here are several package artifact stores that allow hosting for multiple programming languages:
Monitor
This part is especially tricky when working with serverless applications, as everything is split into small pieces. It’s important to use monitoring tools that support this mode of work. Here are some tools that can handle serverless:
Summary
The serverless era brings many transitions along with it like a codification of the entire pipeline and Git being the single source of truth. This doesn’t mean that the same problems that we use to have like security, logging and more disappeared, you should continue addressing them and leveraging tools that enable you to focus on your business.