AWS News Blog
Welcome to AWS Pi Day 2022

|
 We launched Amazon Simple Storage Service (Amazon S3) sixteen years ago today!
We launched Amazon Simple Storage Service (Amazon S3) sixteen years ago today!
As I often told my audiences in the early days, I wanted them to think big thoughts and dream big dreams! Looking back, I think it is safe to say that the launch of S3 empowered them to do just that, and initiated a wave of innovation that continues to this day.
Bigger, Busier, and more Cost-Effective
Our customers count on Amazon S3 to provide them with reliable and highly durable object storage that scales to meet their needs, while growing more and more cost-effective over time. We’ve met those needs and many others; here are some new metrics that prove my point:
Object Storage – Amazon S3 now holds more than 200 trillion (2 x 1014) objects. That’s almost 29,000 objects for each resident of planet Earth. Counting at one object per second, it would take 6.342 million years to reach this number! According to Ethan Siegel, there are about 2 trillion galaxies in the visible Universe, so that’s 100 objects per galaxy! Shortly after the 2006 launch of S3, I was happy to announce the then-impressive metric of 800 million stored objects, so the object count has grown by a factor of 250,000 in less than 16 years.
Request Rate – Amazon S3 now averages over 100 million requests per second.
Cost Effective – Over time we have added multiple storage classes to S3 in order to optimize cost and performance for many different workloads. For example, AWS customers are making great use of Amazon S3 Intelligent Tiering (the only cloud storage class that delivers automatic storage cost savings when data access patterns change), and have saved more than $250 million in storage costs as compared to Amazon S3 Standard. When I first wrote about this storage class in 2018, I said:
In order to make it easier for you to take advantage of S3 without having to develop a deep understanding of your access patterns, we are launching a new storage class, S3 Intelligent-Tiering.
With the improved cost optimizations for small and short-lived objects and the archiving capabilities that we launched late last year, you can now use S3 Intelligent-Tiering as the default storage class for just about every workload, especially data lakes, analytics use cases, and new applications.
Customer Innovation
As you can see from the metrics above, our customers use S3 to store and protect vast amounts of data in support of an equally vast number of use cases and applications. Here are just a few of the ways that our customers are innovating:
NASCAR – 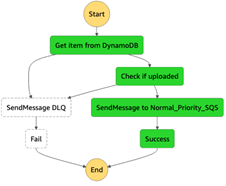 After spending 15 years collecting video, image, and audio assets representing over 70 years of motor sports history, NASCAR built a media library that encompassed over 8,600 LTO 6 tapes and a few thousand LTO 4 tapes, with a growth rate of between 1.5 PB and 2 PB per year. Over the course of 18 months they migrated all of this content (a total of 15 PB) to AWS, making use of the Amazon S3 Standard, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive storage classes. To learn more about how they migrated this massive and invaluable archive, read Modernizing NASCAR’s multi-PB media archive at speed with AWS Storage.
After spending 15 years collecting video, image, and audio assets representing over 70 years of motor sports history, NASCAR built a media library that encompassed over 8,600 LTO 6 tapes and a few thousand LTO 4 tapes, with a growth rate of between 1.5 PB and 2 PB per year. Over the course of 18 months they migrated all of this content (a total of 15 PB) to AWS, making use of the Amazon S3 Standard, Amazon S3 Glacier Flexible Retrieval, and Amazon S3 Glacier Deep Archive storage classes. To learn more about how they migrated this massive and invaluable archive, read Modernizing NASCAR’s multi-PB media archive at speed with AWS Storage.
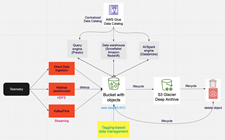 This game maker’s core telemetry systems handle tens of petabytes of data, tens of thousands of tables, and over 2 billion objects. As their games became more popular and the volume of data grew, they were facing challenges around data growth, cost management, retention, and data usage. In a series of updates, they moved archival data to Amazon S3 Glacier Deep Archive, implemented tag-driven retention management, and implemented Amazon S3 Intelligent-Tiering. They have reduced their costs and made their data assets more accessible; read Electronic Arts optimizes storage costs and operations using Amazon S3 Intelligent-Tiering and S3 Glacier to learn more.
NRGene / CRISPR-IL –
This game maker’s core telemetry systems handle tens of petabytes of data, tens of thousands of tables, and over 2 billion objects. As their games became more popular and the volume of data grew, they were facing challenges around data growth, cost management, retention, and data usage. In a series of updates, they moved archival data to Amazon S3 Glacier Deep Archive, implemented tag-driven retention management, and implemented Amazon S3 Intelligent-Tiering. They have reduced their costs and made their data assets more accessible; read Electronic Arts optimizes storage costs and operations using Amazon S3 Intelligent-Tiering and S3 Glacier to learn more.
NRGene / CRISPR-IL – 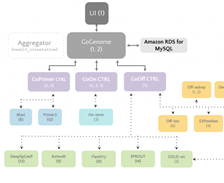 This team came together to build a best-in-class gene-editing prediction platform. CRISPR ( A Crack In Creation is a great introduction) is a very new and very precise way to edit genes and effect changes to an organism’s genetic makeup. The CRISPR-IL consortium is built around an iterative learning process that allows researchers to send results to a predictive engine that helps to shape the next round of experiments. As described in A gene-editing prediction engine with iterative learning cycles built on AWS, the team identified five key challenges and then used AWS to build GoGenome, a web service that performs predictions and delivers the results to users. GoGenome stores over 20 terabytes of raw sequencing data, and hundreds of millions of feature vectors, making use of Amazon S3 and other AWS storage services as the foundation of their data lake.
This team came together to build a best-in-class gene-editing prediction platform. CRISPR ( A Crack In Creation is a great introduction) is a very new and very precise way to edit genes and effect changes to an organism’s genetic makeup. The CRISPR-IL consortium is built around an iterative learning process that allows researchers to send results to a predictive engine that helps to shape the next round of experiments. As described in A gene-editing prediction engine with iterative learning cycles built on AWS, the team identified five key challenges and then used AWS to build GoGenome, a web service that performs predictions and delivers the results to users. GoGenome stores over 20 terabytes of raw sequencing data, and hundreds of millions of feature vectors, making use of Amazon S3 and other AWS storage services as the foundation of their data lake.
Some other cool recent S3 success stories include Liberty Mutual (How Liberty Mutual built a highly scalable and cost-effective document management solution), Discovery (Discovery Accelerates Innovation, Cuts Linear Playout Infrastructure Costs by 61% on AWS), and Pinterest (How Pinterest worked with AWS to create a new way to manage data access).
Join Us Online Today
In celebration of AWS Pi Day 2022 we have put together an entire day of educational sessions, live demos, and even a launch or two. We will also take a look at some of the newest S3 launches including Amazon S3 Glacier Instant Retrieval, Amazon S3 Batch Replication and AWS Backup Support for Amazon S3.
Designed for system administrators, engineers, developers, and architects, our sessions will bring you the latest and greatest information on security, backup, archiving, certification, and more. Join us at 9:30 AM PT on Twitch for Kevin Miller’s kickoff keynote, and stick around for the entire day to learn a lot more about how you can put Amazon S3 to use in your applications. See you there!
— Jeff;