AWS Big Data Blog
Category: Amazon Athena

Analyze and visualize your VPC network traffic using Amazon Kinesis and Amazon Athena
In this blog post, we describe the complete solution for collecting, analyzing, and visualizing VPC flow log data. In addition, we created a single AWS CloudFormation template that lets you efficiently deploy this solution into your own account.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.
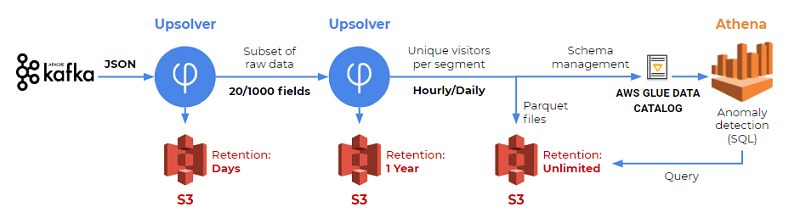
How SimilarWeb analyze hundreds of terabytes of data every month with Amazon Athena and Upsolver
This is a guest post by Yossi Wasserman, a data collection & innovation team leader at Similar Web. SimilarWeb, in their own words: SimilarWeb is the pioneer of market intelligence and the standard for understanding the digital world. SimilarWeb provides granular insights about any website or mobile app across all industries in every region. SimilarWeb […]
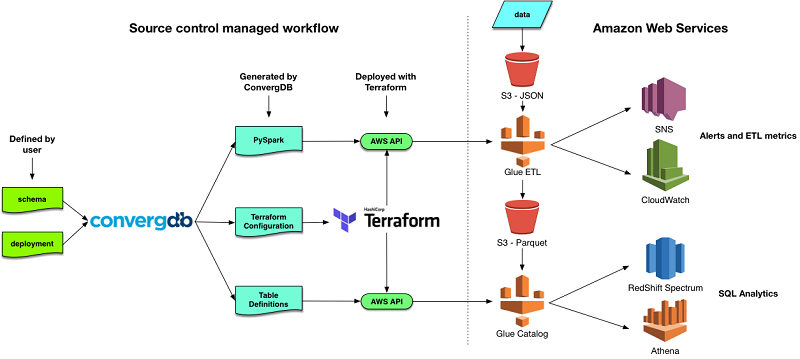
How Pagely implemented a serverless data lake in AWS to facilitate customer support analytics
In this post, we discuss how Pagely worked with Beyondsoft, an AWS Advanced Consulting Partner, to use ConvergDB, an open-source tool developed by Beyondsoft, to build a DevOps-centric data pipeline. This pipeline uses AWS Glue to transform application logs into optimized tables that can be queried quickly and cost effectively using Amazon Athena.

How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena
In this post, we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB.

Orchestrate multiple ETL jobs using AWS Step Functions and AWS Lambda
In this post, I show you how to use AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs involving a diverse set of technologies in an arbitrarily-complex ETL workflow.
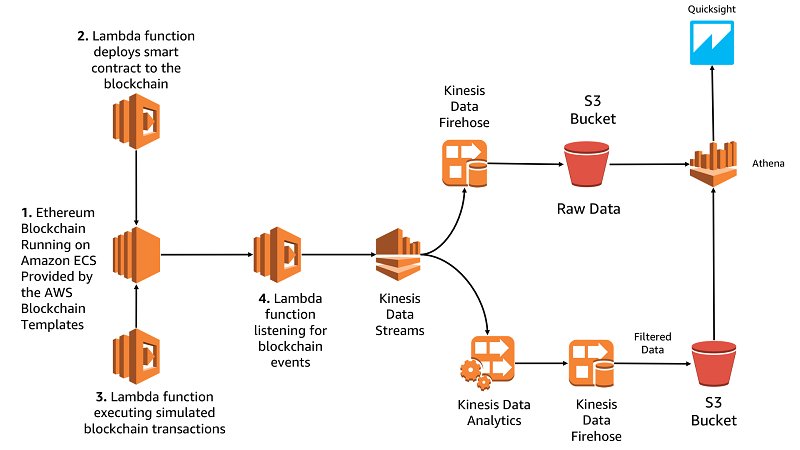
Build a blockchain analytic solution with AWS Lambda, Amazon Kinesis, and Amazon Athena
In this post, we’ll show you how to deploy an Ethereum blockchain using the AWS Blockchain Templates, deploy a smart contract, and build a serverless analytics pipeline for that contract based around AWS Lambda, Amazon Kinesis, and Amazon Athena.
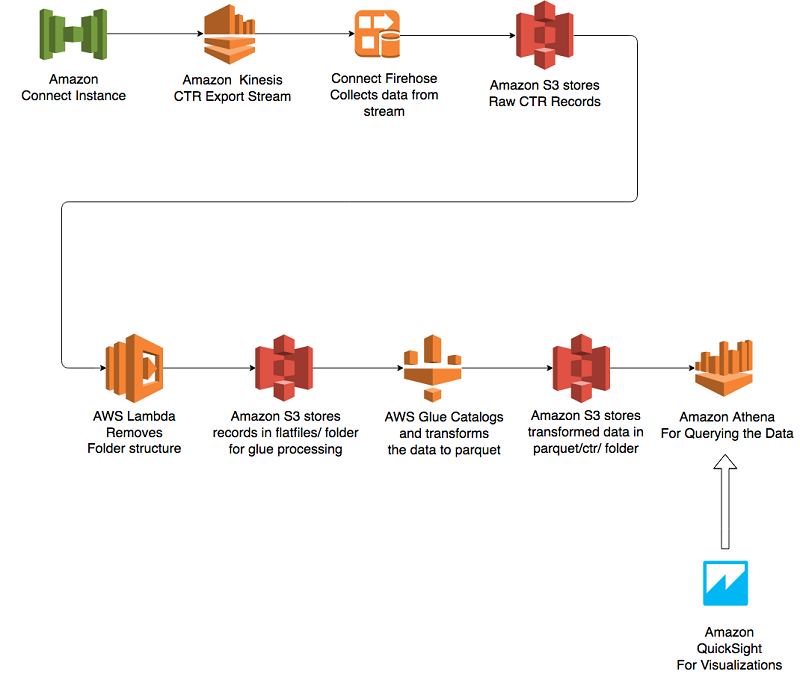
Analyze Amazon Connect records with Amazon Athena, AWS Glue, and Amazon QuickSight
In this blog post, we focus on how to get analytics out of the rich set of data published by Amazon Connect. We make use of an Amazon Connect data stream and create an end-to-end workflow to offer an analytical solution that can be customized based on need.
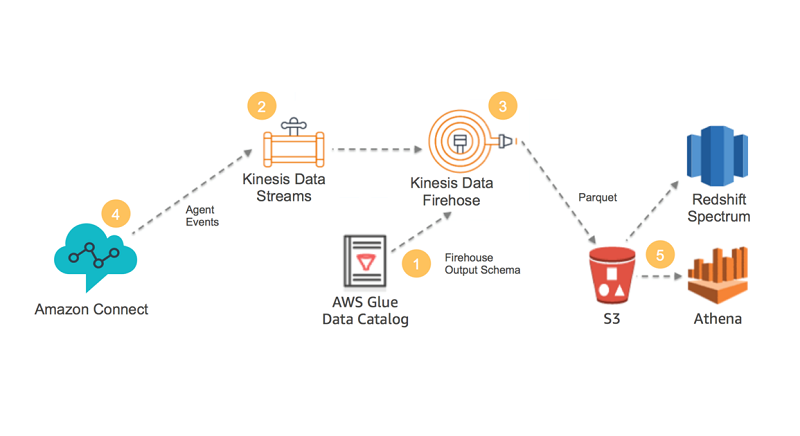
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.