AWS Big Data Blog
Category: Amazon EMR on EKS

Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to […]
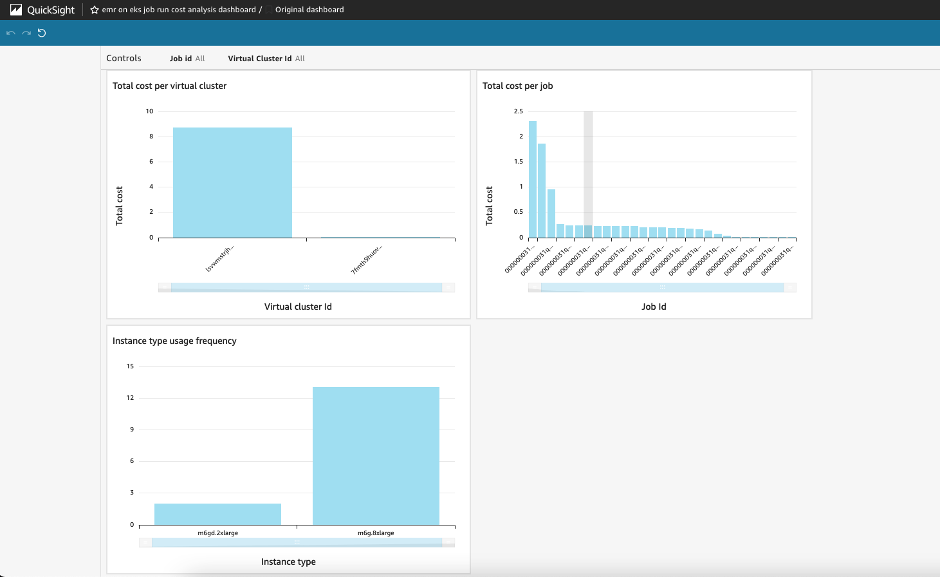
Cost monitoring for Amazon EMR on Amazon EKS
Amazon EMR is the industry-leading cloud big data solution, providing a collection of open-source frameworks such as Spark, Hive, Hudi, and Presto, fully managed and with per-second billing. Amazon EMR on Amazon EKS is a deployment option allowing you to deploy Amazon EMR on the same Amazon Elastic Kubernetes Service (Amazon EKS) clusters that is […]

Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

Improve reliability and reduce costs of your Apache Spark workloads with vertical autoscaling on Amazon EMR on EKS
Amazon EMR on Amazon EKS is a deployment option offered by Amazon EMR that enables you to run Apache Spark applications on Amazon Elastic Kubernetes Service (Amazon EKS) in a cost-effective manner. It uses the EMR runtime for Apache Spark to increase performance so that your jobs run faster and cost less. Apache Spark allows […]

Amazon EMR on EKS widens the performance gap: Run Apache Spark workloads 5.37 times faster and at 4.3 times lower cost
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. […]

How SafeGraph built a reliable, efficient, and user-friendly Apache Spark platform with Amazon EMR on Amazon EKS
This is a guest post by Nan Zhu, Tech Lead Manager, SafeGraph, and Dave Thibault, Sr. Solutions Architect – AWS SafeGraph is a geospatial data company that curates over 41 million global points of interest (POIs) with detailed attributes, such as brand affiliation, advanced category tagging, and open hours, as well as how people interact […]

Accelerate your data exploration and experimentation with the AWS Analytics Reference Architecture library
Organizations use their data to solve complex problems by starting small, running iterative experiments, and refining the solution. Although the power of experiments can’t be ignored, organizations have to be cautious about the cost-effectiveness of such experiments. If time is spent creating the underlying infrastructure for enabling experiments, it further adds to the cost. Developers […]

Run fault tolerant and cost-optimized Spark clusters using Amazon EMR on EKS and Amazon EC2 Spot Instances
Amazon EMR on EKS is a deployment option in Amazon EMR that allows you to run Spark jobs on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances save you up to 90% over On-Demand Instances, and is a great way to cost optimize the Spark workloads running on Amazon […]

Introducing ACK controller for Amazon EMR on EKS
AWS Controllers for Kubernetes (ACK) was announced in August, 2020, and now supports 14 AWS service controllers as generally available with an additional 12 in preview. The vision behind this initiative was simple: allow Kubernetes users to use the Kubernetes API to manage the lifecycle of AWS resources such as Amazon Simple Storage Service (Amazon […]