AWS Big Data Blog
Category: Amazon EMR
Dynamically scale up storage on Amazon EMR clusters
February 2025: The bootstrap action script in this blog post uses IMDS v1 for accessing EC2 instance metadata. The script does not support IMDS v2 and cannot be used in an AWS account which has IMDS v2 enforced across the account. Using the script in an IMDS v2 enabled account will cause issues and unexpected […]

Migrate to Apache HBase on Amazon S3 on Amazon EMR: Guidelines and Best Practices
This whitepaper walks you through the stages of a migration. It also helps you determine when to choose Apache HBase on Amazon S3 on Amazon EMR, plan for platform security, tune Apache HBase and EMRFS to support your application SLA, identify options to migrate and restore your data, and manage your cluster in production.
Real-time bushfire alerting with Complex Event Processing in Apache Flink on Amazon EMR and IoT sensor network
In this blog post, we discuss how to build a real-time IoT stream processing, visualization, and alerting pipeline using various AWS services. We took advantage of the Complex Event Processing feature provided by Apache Flink to detect patterns within a network from the incoming events.

Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).

Build a Concurrent Data Orchestration Pipeline Using Amazon EMR and Apache Livy
In this post, we explore orchestrating a Spark data pipeline on Amazon EMR using Apache Livy and Apache Airflow, we create a simple Airflow DAG to demonstrate how to run spark jobs concurrently, and we see how Livy helps to hide the complexity to submit spark jobs via REST by using optimal EMR resources.
Exploratory data analysis of genomic datasets using ADAM and Mango with Apache Spark on Amazon EMR
In this post, we describe how to set up and run ADAM and Mango on Amazon EMR. We demonstrate how you can use these tools in an interactive notebook environment to explore the 1000 Genomes dataset, which is publicly available in Amazon S3 as a public dataset.

Encrypt data in transit using a TLS custom certificate provider with Amazon EMR
Many enterprises have highly regulated policies around cloud security. Those policies might be even more restrictive for Amazon EMR where sensitive data is processed. EMR provides security configurations that allow you to set up encryption for data at rest stored on Amazon S3 and local Amazon EBS volumes. It also allows the setup of Transport […]
Best practices for resizing and automatic scaling in Amazon EMR
In this post, I detail how EMR clusters resize, and I present some best practices for getting the maximum benefit and resulting cost savings for your own cluster through this feature.
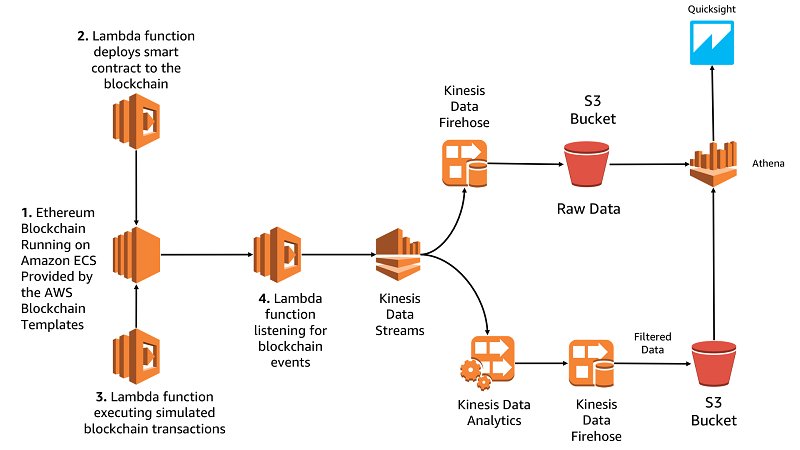
Build a blockchain analytic solution with AWS Lambda, Amazon Kinesis, and Amazon Athena
In this post, we’ll show you how to deploy an Ethereum blockchain using the AWS Blockchain Templates, deploy a smart contract, and build a serverless analytics pipeline for that contract based around AWS Lambda, Amazon Kinesis, and Amazon Athena.

Orchestrate Apache Spark applications using AWS Step Functions and Apache Livy
In this post, I’ll show you how to use AWS Step Functions to orchestrate your Spark jobs that are running on Amazon EMR.