AWS Big Data Blog
Category: AWS Glue DataBrew
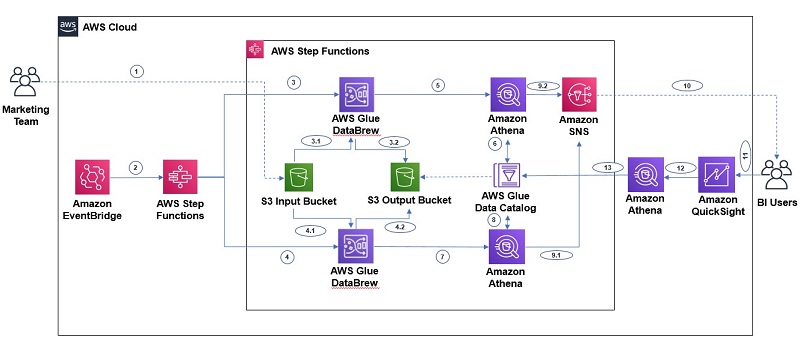
Orchestrating an AWS Glue DataBrew job and Amazon Athena query with AWS Step Functions
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Also, as we start building complex data engineering or data analytics pipelines, we look for a simpler orchestration mechanism with graphical user interface-based ETL (extract, transform, load) tools. Recently, AWS […]

7 most common data preparation transformations in AWS Glue DataBrew
For all analytics and ML modeling use cases, data analysts and data scientists spend a bulk of their time running data preparation tasks manually to get a clean and formatted data to meet their needs. We ran a survey among data scientists and data analysts to understand the most frequently used transformations in their data […]

Setting up automated data quality workflows and alerts using AWS Glue DataBrew and AWS Lambda
Proper data management is critical to successful, data-driven decision-making. An increasingly large number of customers are adopting data lakes to realize deeper insights from big data. As part of this, you need clean and trusted data in order to gain insights that lead to improvements in your business. As the saying goes, garbage in is […]

Transform data and create dashboards simply using AWS Glue DataBrew and Amazon QuickSight
Before you can create visuals and dashboards that convey useful information, you need to transform and prepare the underlying data. The range and complexity of data transformation steps required depends on the visuals you would like in your dashboard. Often, the data transformation process is time-consuming and highly iterative, especially when you are working with […]

Preparing data for ML models using AWS Glue DataBrew in a Jupyter notebook
AWS Glue DataBrew is a new visual data preparation tool that makes it easy for data analysts and data scientists to clean and normalize data to prepare it for analytics and machine learning (ML). In this post, we examine a sample ML use case and show how to use DataBrew and a Jupyter notebook to […]

Enabling self-service data publication to your data lake using AWS Glue DataBrew
Data lakes have been providing a level of flexibility to organizations unparalleled to anything before them. Having the ability to load and query data in place—and in its natural form—has led to an explosion of data lake deployments that have allowed organizations to accelerate against their data strategy faster than ever before. Most organizations have […]

Data preprocessing for machine learning on Amazon EMR made easy with AWS Glue DataBrew
The machine learning (ML) lifecycle consists of several key phases: data collection, data preparation, feature engineering, model training, model evaluation, and model deployment. The data preparation and feature engineering phases ensure an ML model is given high-quality data that is relevant to the model’s purpose. Because most raw datasets require multiple cleaning steps (such as […]