AWS Big Data Blog
Category: Database

Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift
In this blog post, we’ll use a real customer scenario to show you how to create a caching layer in front of Amazon Redshift using pgpool and Amazon ElastiCache.
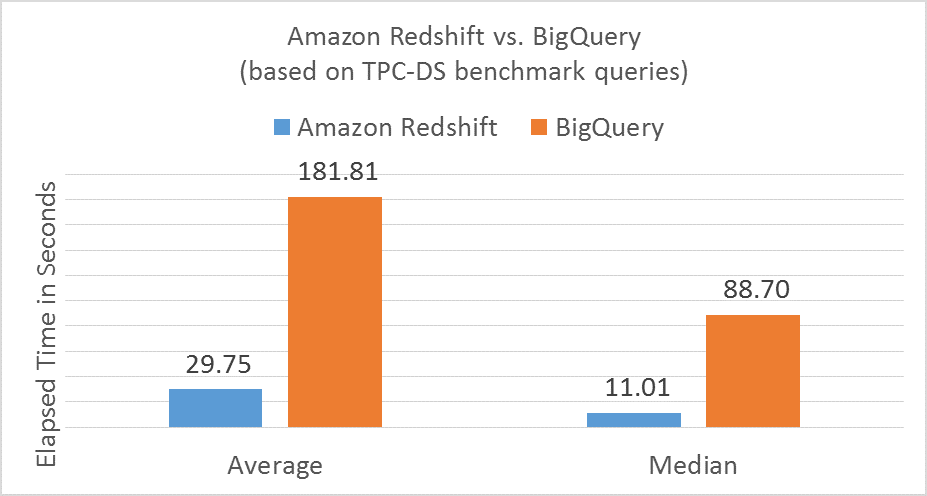
Fact or Fiction: Google BigQuery Outperforms Amazon Redshift as an Enterprise Data Warehouse?
Publishing misleading performance benchmarks is a classic old guard marketing tactic. It’s not surprising to see old guard companies (like Oracle) doing this, but we were kind of surprised to see Google take this approach, too. So, when Google presented their BigQuery vs. Amazon Redshift benchmark results at a private event in San Francisco on September 29, 2016, it piqued our interest and we decided to dig deeper.

Amazon EMR-DynamoDB Connector Repository on AWSLabs GitHub
Amazon Web Services is excited to announce that the Amazon EMR-DynamoDB Connector is now open-source. The code you see in the GitHub repository is exactly what is available on your EMR cluster, making it easier to build applications with this component.

Monitor Your Application for Processing DynamoDB Streams
In this post, I suggest ways you can monitor the Amazon Kinesis Client Library (KCL) application you use to process DynamoDB Streams to quickly track and resolve issues or failures so you can avoid losing data. Dashboards, metrics, and application logs all play a part. This post may be most relevant to Java applications running on Amazon EC2 instances.

Process Large DynamoDB Streams Using Multiple Amazon Kinesis Client Library (KCL) Workers
Asmita Barve-Karandikar is an SDE with DynamoDB Introduction Imagine you own a popular mobile health app, with millions of users worldwide, that continuously records new information. It sends over one million updates per second to its master data store and needs the updates to be relayed to various replicas across different regions in real time. […]

Simplify Management of Amazon Redshift Snapshots using AWS Lambda
NOTE: Amazon Redshift now supports creating an automatic snapshot schedule using the snapshot scheduler. For more information, please review this “What’s New” post. ———————————- Ian Meyers is a Solutions Architecture Senior Manager with AWS Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data […]
Processing Amazon DynamoDB Streams Using the Amazon Kinesis Client Library
Asmita Barve-Karandikar is an SDE with DynamoDB Customers often want to process streams on an Amazon DynamoDB table with a significant number of partitions or with a high throughput. AWS Lambda and the DynamoDB Streams Kinesis Adapter are two ways to consume DynamoDB streams in a scalable way. While Lambda lets you run your application […]

JOIN Amazon Redshift AND Amazon RDS PostgreSQL WITH dblink
Tony Gibbs is a Solutions Architect with AWS (Update: This blog post has been translated into Japanese) When it comes to choosing a SQL-based database in AWS, there are many options. Sometimes it can be difficult to know which one to choose. For example, when would you use Amazon Aurora instead of Amazon RDS PostgreSQL […]
Using Spark SQL for ETL
Ben Snively is a Solutions Architect with AWS With big data, you deal with many different formats and large volumes of data. SQL-style queries have been around for nearly four decades. Many systems support SQL-style syntax on top of the data layers, and the Hadoop/Spark ecosystem is no exception. This allows companies to try new […]

Real-time in-memory OLTP and Analytics with Apache Ignite on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Babu Elumalai is a Solutions Architect with AWS Organizations are generating tremendous amounts of data, and they increasingly need tools and systems that help them use this data to make decisions. The […]