AWS Big Data Blog
Category: Announcements

Introducing Apache Hudi support with AWS Glue crawlers
Apache Hudi is an open table format that brings database and data warehouse capabilities to data lakes. Apache Hudi helps data engineers manage complex challenges, such as managing continuously evolving datasets with transactions while maintaining query performance. Data engineers use Apache Hudi for streaming workloads as well as to create efficient incremental data pipelines. Hudi provides tables, transactions, efficient […]

Introducing persistent buffering for Amazon OpenSearch Ingestion
Amazon OpenSearch Ingestion is a fully managed, serverless pipeline that delivers real-time log, metric, and trace data to Amazon OpenSearch Service domains and OpenSearch Serverless collections. Customers use Amazon OpenSearch Ingestion pipelines to ingest data from a variety of data sources, both pull-based and push-based. When ingesting data from pull-based sources, such as Amazon Simple […]

Decentralize LF-tag management with AWS Lake Formation
In today’s data-driven world, organizations face unprecedented challenges in managing and extracting valuable insights from their ever-expanding data ecosystems. As the number of data assets and users grow, the traditional approaches to data management and governance are no longer sufficient. Customers are now building more advanced architectures to decentralize permissions management to allow for individual […]
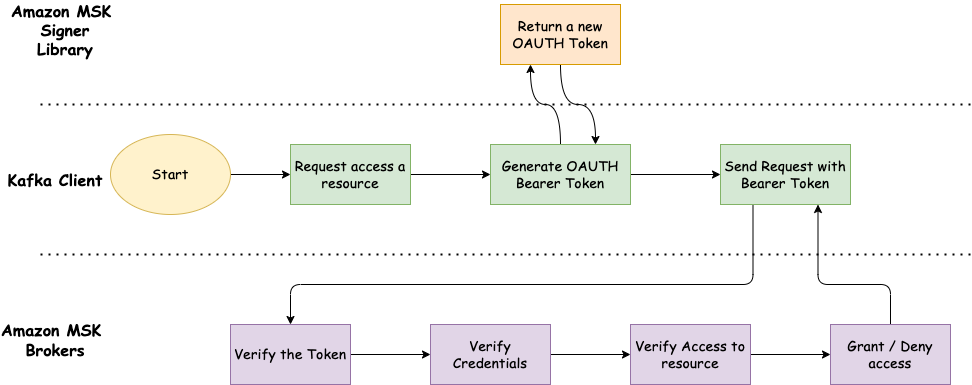
Amazon MSK IAM authentication now supports all programming languages
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Administrators can simplify and standardize access control to Kafka resources using IAM. This support is based on SASL/OUATHBEARER, an open standard for authorization and authentication. Both Amazon MSK provisioned and serverless cluster […]

Configure dynamic tenancy for Amazon OpenSearch Dashboards
Amazon OpenSearch Service securely unlocks real-time search, monitoring, and analysis of business and operational data for use cases like application monitoring, log analytics, observability, and website search. In this post, we talk about new configurable dashboards tenant properties. OpenSearch Dashboards tenants in Amazon OpenSearch Service are spaces for saving index patterns, visualizations, dashboards, and other […]

Migrate data from Azure Blob Storage to Amazon S3 using AWS Glue
In this post, we use Azure Blob Storage as an example and demonstrate how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it. Regarding the Azure Data Lake Storage Gen2 Connector, we highlight any major differences in this post.

Unlock data across organizational boundaries using Amazon DataZone – now generally available
We are excited to announce the general availability of Amazon DataZone. Amazon DataZone enables customers to discover, access, share, and govern data at scale across organizational boundaries, reducing the undifferentiated heavy lifting of making data and analytics tools accessible to everyone in the organization. With Amazon DataZone, data users like data engineers, data scientists, and data analysts can share and access […]

Introducing hybrid access mode for AWS Glue Data Catalog to secure access using AWS Lake Formation and IAM and Amazon S3 policies
To ease the transition of data lake permissions from an IAM and S3 model to Lake Formation, we’re introducing a hybrid access mode for AWS Glue Data Catalog. This feature lets you secure and access the cataloged data using both Lake Formation permissions and IAM and S3 permissions. Hybrid access mode allows data administrators to onboard Lake Formation permissions selectively and incrementally, focusing on one data lake use case at a time. For example, say you have an existing extract, transform and load (ETL) data pipeline that uses the IAM and S3 policies to manage data access. Now you want to allow your data analysts to explore or query the same data using Amazon Athena. You can grant access to the data analysts using Lake Formation permissions, to include fine-grained controls as needed, without changing access for your ETL data pipelines.

Introducing Amazon MSK as a source for Amazon OpenSearch Ingestion
Ingesting a high volume of streaming data has been a defining characteristic of operational analytics workloads with Amazon OpenSearch Service. Many of these workloads involve either self-managed Apache Kafka or Amazon Managed Streaming for Apache Kafka (Amazon MSK) to satisfy their data streaming needs. Consuming data from Amazon MSK and writing to OpenSearch Service has been a challenge for customers. AWS Lambda, custom code, Kafka Connect, and Logstash have been used for ingesting this data. These methods involve tools that must be built and maintained. In this post, we introduce Amazon MSK as a source to Amazon OpenSearch Ingestion, a serverless, fully managed, real-time data collector for OpenSearch Service that makes this ingestion even easier.

Amazon OpenSearch Service H1 2023 in review
Since its release in January 2021, the OpenSearch project has released 14 versions through June 2023. Amazon OpenSearch Service supports the latest versions of OpenSearch up to version 2.7. OpenSearch Service provides two configuration options to deploy and operate OpenSearch at scale in the cloud. With OpenSearch Service managed domains, you specify a hardware configuration […]