AWS Big Data Blog
Monitor and optimize cost on AWS Glue for Apache Spark
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores.
One of the most common questions we get from customers is how to effectively monitor and optimize costs on AWS Glue for Spark. The diversity of features and pricing options for AWS Glue offers the flexibility to effectively manage the cost of your data workloads and still keep the performance and capacity as per your business needs. Although the fundamental process of cost optimization for AWS Glue workloads remains the same, you can monitor job runs and analyze the costs and usage to find savings and take action to implement improvements to the code or configurations.
In this post, we demonstrate a tactical approach to help you manage and reduce cost through monitoring and optimization techniques on top of your AWS Glue workloads.
Monitor overall costs on AWS Glue for Apache Spark
AWS Glue for Apache Spark charges an hourly rate in 1-second increments with a minimum of 1 minute based on the number of data processing units (DPUs). Learn more in AWS Glue Pricing. This section describes a way to monitor overall costs on AWS Glue for Apache Spark.
AWS Cost Explorer
In AWS Cost Explorer, you can see overall trends of DPU hours. Complete the following steps:
- On the Cost Explorer console, create a new cost and usage report.
- For Service, choose Glue.
- For Usage type, choose the following options:
- Choose <Region>-ETL-DPU-Hour (DPU-Hour) for standard jobs.
- Choose <Region>-ETL-Flex-DPU-Hour (DPU-Hour) for Flex jobs.
- Choose <Region>-GlueInteractiveSession-DPU-Hour (DPU-Hour) for interactive sessions.
- Choose Apply.
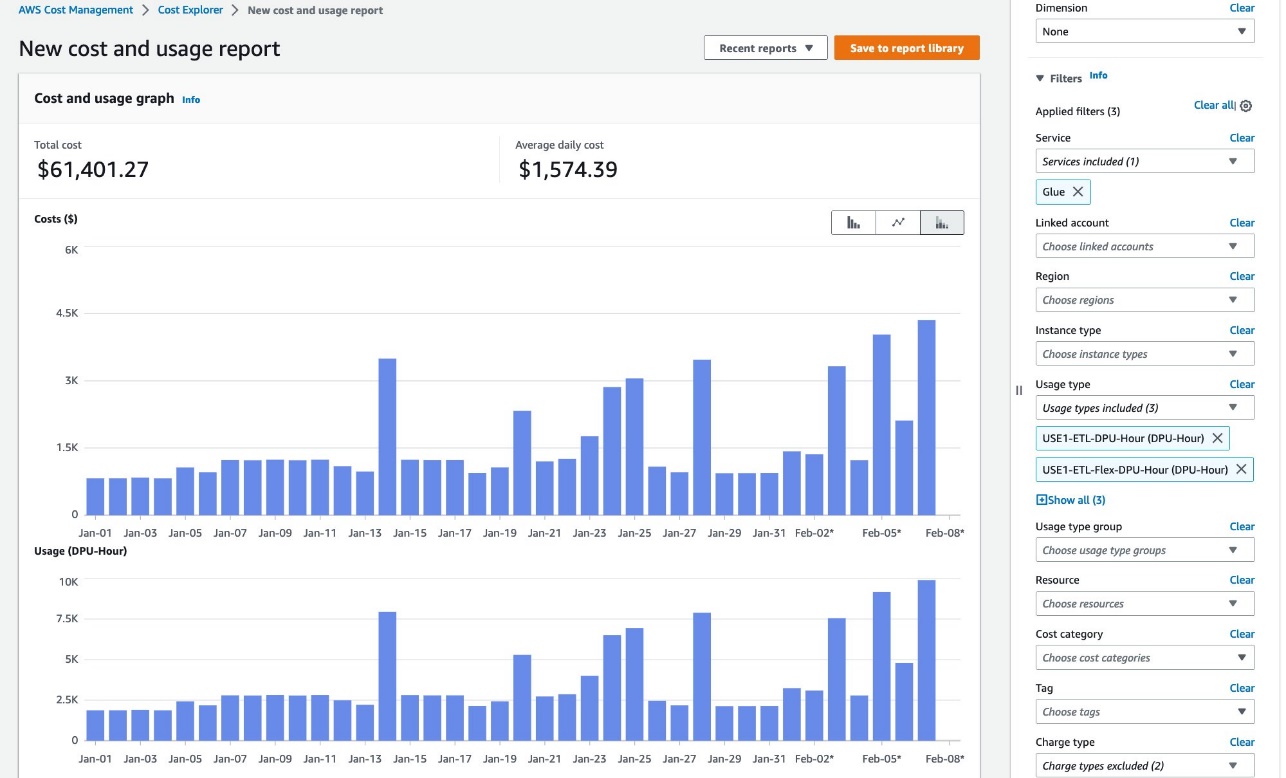
Learn more in Analyzing your costs with AWS Cost Explorer.
Monitor individual job run costs
This section describes a way to monitor individual job run costs on AWS Glue for Apache Spark. There are two options to achieve this.
AWS Glue Studio Monitoring page
On the Monitoring page in AWS Glue Studio, you can monitor the DPU hours you spent on a specific job run. The following screenshot shows three job runs that processed the same dataset; the first job run spent 0.66 DPU hours, and the second spent 0.44 DPU hours. The third one with Flex spent only 0.32 DPU hours.

GetJobRun and GetJobRuns APIs
The DPU hour values per job run can be retrieved through AWS APIs.
For auto scaling jobs and Flex jobs, the field DPUSeconds is available in GetJobRun and GetJobRuns API responses:
The field DPUSeconds returns 1137.0. This means 0.32 DPU hours which can be calculated in 1137.0/(60*60)=0.32.
For the other standard jobs without auto scaling, the field DPUSeconds is not available:
For these jobs, you can calculate DPU hours by ExecutionTime*MaxCapacity/(60*60). Then you get 0.44 DPU hour by 157*10/(60*60)=0.44. Note that AWS Glue versions 2.0 and later have a 1-minute minimum billing.
AWS CloudFormation template
Because DPU hours can be retrieved through the GetJobRun and GetJobRuns APIs, you can integrate this with other services like Amazon CloudWatch to monitor trends of consumed DPU hours over time. For example, you can configure an Amazon EventBridge rule to invoke an AWS Lambda function to publish CloudWatch metrics every time AWS Glue jobs finish.
To help you configure that quickly, we provide an AWS CloudFormation template. You can review and customize it to suit your needs. Some of the resources this stack deploys incur costs when in use.
The CloudFormation template generates the following resources:
- AWS Identity and Access Management (IAM) role
- Lambda function
- EventBridge rule
To create your resources, complete the following steps:
- Sign in to the AWS CloudFormation console.
- Choose Launch Stack:

- Choose Next.
- Choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.
Stack creation can take up to 3 minutes.
After you complete the stack creation, when AWS Glue jobs finish, the following DPUHours metrics are published under the Glue namespace in CloudWatch:
- Aggregated metrics – Dimension=[JobType, GlueVersion, ExecutionClass]
- Per-job metrics – Dimension=[JobName, JobRunId=ALL]
- Per-job run metrics – Dimension=[JobName, JobRunId]
Aggregated metrics and per-job metrics are shown as in the following screenshot.
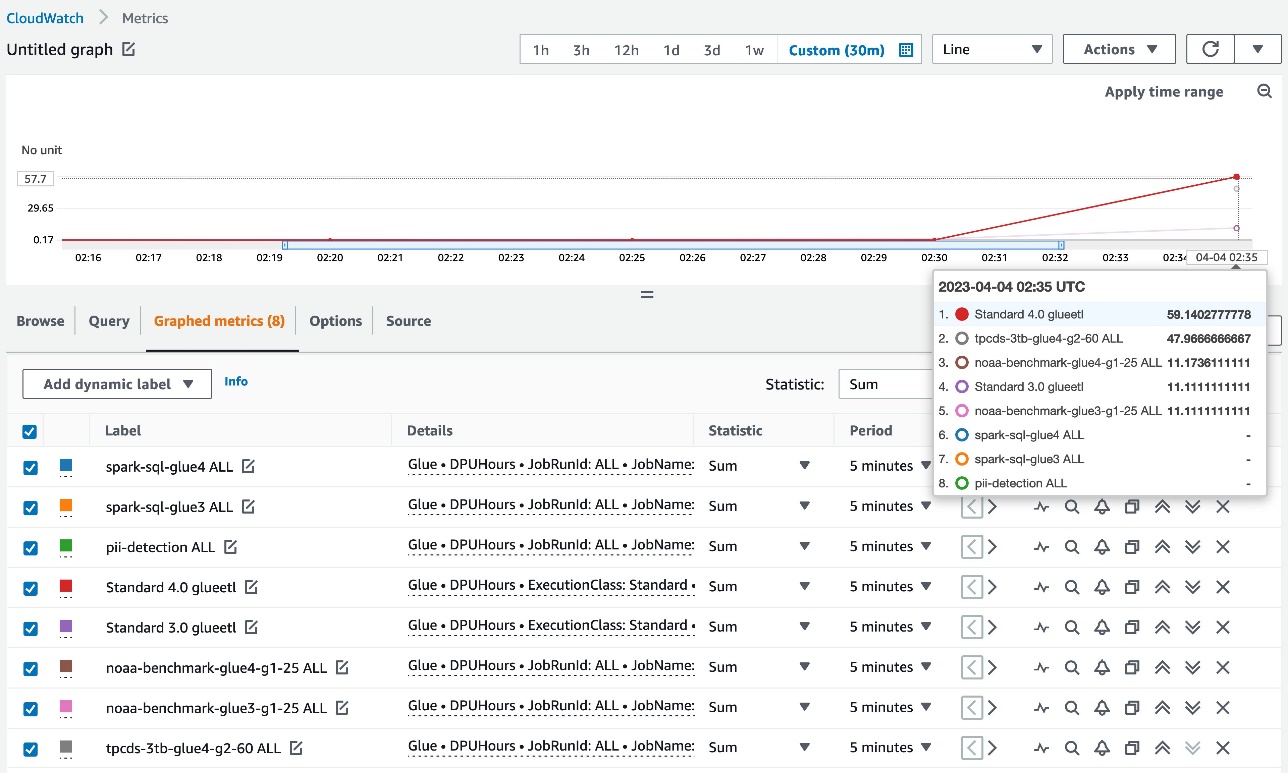
Each datapoint represents DPUHours per individual job run, so valid statistics for the CloudWatch metrics is SUM. With the CloudWatch metrics, you can have a granular view on DPU hours.
Options to optimize cost
This section describes key options to optimize costs on AWS Glue for Apache Spark:
- Upgrade to the latest version
- Auto scaling
- Flex
- Set the job’s timeout period appropriately
- Interactive sessions
- Smaller worker type for streaming jobs
We dive deep to the individual options.
Upgrade to the latest version
Having AWS Glue jobs running on the latest version enables you to take advantage of the latest functionalities and improvements offered by AWS Glue and the upgraded version of the supported engines such as Apache Spark. For example, AWS Glue 4.0 includes the new optimized Apache Spark 3.3.0 runtime and adds support for built-in pandas APIs as well as native support for Apache Hudi, Apache Iceberg, and Delta Lake formats, giving you more options for analyzing and storing your data. It also includes a new highly performant Amazon Redshift connector that is 10 times faster on TPC-DS benchmarking.
Auto scaling
One of the most common challenges to reduce cost is to identify the right amount of resources to run jobs. Users tend to overprovision workers in order to avoid resource-related problems, but part of those DPUs are not used, which increases costs unnecessarily. Starting with AWS Glue version 3.0, AWS Glue auto scaling helps you dynamically scale resources up and down based on the workload, for both batch and streaming jobs. Auto scaling reduces the need to optimize the number of workers to avoid over-provisioning resources for jobs, or paying for idle workers.
To enable auto scaling on AWS Glue Studio, go to the Job Details tab of your AWS Glue job and select Automatically scale number of workers.

You can learn more in Introducing AWS Glue Auto Scaling: Automatically resize serverless computing resources for lower cost with optimized Apache Spark.
Flex
For non-urgent data integration workloads that don’t require fast job start times or can afford to rerun the jobs in case of a failure, Flex could be a good option. The start times and runtimes of jobs using Flex vary because spare compute resources aren’t always available instantly and may be reclaimed during the run of a job. Flex-based jobs offer the same capabilities, including access to custom connectors, a visual job authoring experience, and a job scheduling system. With the Flex option, you can optimize the costs of your data integration workloads by up to 34%.
To enable Flex on AWS Glue Studio, go to the Job Details tab of your job and select Flex execution.

You can learn more in Introducing AWS Glue Flex jobs: Cost savings on ETL workloads.
Interactive sessions
One common practice among developers that create AWS Glue jobs is to run the same job several times every time a modification is made to the code. However, this may not be cost-effective depending of the number of workers assigned to the job and the number of times that it’s run. Also, this approach may slow down the development time because you have to wait until every job run is complete. To address this issue, in 2022 we released AWS Glue interactive sessions. This feature let developers process data interactively using a Jupyter-based notebook or IDE of their choice. Sessions start in seconds and have built-in cost management. As with AWS Glue jobs, you pay for only the resources you use. Interactive sessions allow developers to test their code line by line without needing to run the entire job to test any changes made to the code.
Set the job’s timeout period appropriately
Due to configuration issues, script coding errors, or data anomalies, sometimes AWS Glue jobs can take an exceptionally long time or struggle to process the data, and it can cause unexpected charges. AWS Glue gives you the ability to set a timeout value on any jobs. By default, an AWS Glue job is configured with 48 hours as the timeout value, but you can specify any timeout. We recommend identifying the average runtime of your job, and based on that, set an appropriate timeout period. This way, you can control cost per job run, prevent unexpected charges, and detect any problems related to the job earlier.
To change the timeout value on AWS Glue Studio, go to the Job Details tab of your job and enter a value for Job timeout.

Interactive sessions also have the same ability to set an idle timeout value on sessions. The default idle timeout value for Spark ETL sessions is 2880 minutes (48 hours). To change the timeout value, you can use %idle_timeout magic.
Smaller worker type for streaming jobs
Processing data in real time is a common use case for customers, but sometimes these streams have sporadic and low data volumes. G.1X and G.2X worker types could be too big for these workloads, especially if we consider streaming jobs may need to run 24/7. To help you reduce costs, in 2022 we released G.025X, a new quarter DPU worker type for streaming ETL jobs. With this new worker type, you can process low data volume streams at one-fourth of the cost.
To select the G.025X worker type on AWS Glue Studio, go to the Job Details tab of your job. For Type, choose Spark Streaming, then choose G 0.25X for Worker type.

You can learn more in Best practices to optimize cost and performance for AWS Glue streaming ETL jobs.
Performance tuning to optimize cost
Performance tuning plays an important role in reducing cost. The first action for performance tuning is to identify the bottlenecks. Without measuring the performance and identifying bottlenecks, it’s not realistic to optimize cost-effectively. CloudWatch metrics provide a simple view for quick analysis, and the Spark UI provides deeper view for performance tuning. It’s highly recommended to enable Spark UI for your jobs and then view the UI to identify the bottleneck.
The following are high-level strategies to optimize costs:
- Scale cluster capacity
- Reduce the amount of data scanned
- Parallelize tasks
- Optimize shuffles
- Overcome data skew
- Accelerate query planning
For this post, we discuss the techniques for reducing the amount of data scanned and parallelizing tasks.
Reduce the amount of data scanned: Enable job bookmarks
AWS Glue job bookmarks are a capability to process data incrementally when running a job multiple times on a scheduled interval. If your use case is an incremental data load, you can enable job bookmarks to avoid a full scan for all job runs and process only the delta from the last job run. This reduces the amount of data scanned and accelerates individual job runs.
Reduce the amount of data scanned: Partition pruning
If your input data is partitioned in advance, you can reduce the amount of data scan by pruning partitions.
For AWS Glue DynamicFrame, set push_down_predicate (and catalogPartitionPredicate), as shown in the following code. Learn more in Managing partitions for ETL output in AWS Glue.
For Spark DataFrame (or Spark SQL), set a where or filter clause to prune partitions:
Parallelize tasks: Parallelize JDBC reads
The number of concurrent reads from the JDBC source is determined by configuration. Note that by default, a single JDBC connection will read all the data from the source through a SELECT query.
Both AWS Glue DynamicFrame and Spark DataFrame support parallelize data scans across multiple tasks by splitting the dataset.
For AWS Glue DynamicFrame, set hashfield or hashexpression and hashpartition. Learn more in Reading from JDBC tables in parallel.
For Spark DataFrame, set numPartitions, partitionColumn, lowerBound, and upperBound. Learn more in JDBC To Other Databases.
Conclusion
In this post, we discussed methodologies for monitoring and optimizing cost on AWS Glue for Apache Spark. With these techniques, you can effectively monitor and optimize costs on AWS Glue for Spark.
If you have comments or feedback, please leave them in the comments.
Appendix: Amazon CloudWatch charges
When you use Amazon CloudWatch with AWS Glue jobs, you are charged standard rates for CloudWatch Metrics, and CloudWatch Logs. Learn more in Amazon CloudWatch pricing.
- Job metrics: You incur additional charges when you enable job metrics, and CloudWatch custom metrics are created.
- Application logging: You incur additional charges for aggregated application logs in CloudWatch log group
/aws-glue/jobs/outputand/aws-glue/jobs/error. - Continuous logging: You incur additional charges when you enable continuous logging, and CloudWatch log events are emitted in CloudWatch log group
/aws-glue/jobs/logs-v2.
When you want to optimize CloudWatch charges related to Glue jobs, first you should see breakdown information in the AWS Cost Explorer.
Optimize cost for CloudWatch metrics
To reduce charges for metrics, you can disable job metrics. Note that the CloudFormation template provided in this post creates custom metrics and you also incur additional charges from that.
Optimize cost for CloudWatch logs
CloudWatch Logs pricing is defined mainly in ingestion and archive storage.
To reduce charges for log ingestion, you can do following:
- Reduce unneeded logging such as
print(),df.show(), and custom logger calls in your job script - Configure standard log filter instead of no filter
- Avoid setting log level to
DEBUGfor production jobs
To reduce charges for log archive storage, you can configure retention period for your log groups. Learn more in Change log data retention in CloudWatch Logs.
About the Authors
 Leonardo Gómez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on LinkedIn
Leonardo Gómez is a Principal Analytics Specialist Solutions Architect at AWS. He has over a decade of experience in data management, helping customers around the globe address their business and technical needs. Connect with him on LinkedIn
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.