AWS Compute Blog
Building an API poller with AWS Step Functions and AWS Lambda
This post is written by Siarhei Kazhura, Solutions Architect.
Many customers have to integrate with external APIs. One of the most common use cases is data synchronization between a customer and their trusted partner.
There are multiple ways of doing this. For example, the customer can provide a webhook that the partner can call to notify the customer of any data changes. Often the customer has to poll the partner API to stay up to date with the changes. Even when using a webhook, a complete synchronization happening on schedule is necessary.
Furthermore, the partner API may not allow loading all the data at once. Often, a pagination solution allows loading only a portion of the data via one API call. That requires the customer to build an API poller that can iterate through all the data pages to fully synchronize.
This post demonstrates a sample API poller architecture, using AWS Step Functions for orchestration, AWS Lambda for business logic processing, along with Amazon API Gateway, Amazon DynamoDB, Amazon SQS, Amazon EventBridge, Amazon Simple Storage Service (Amazon S3), and the AWS Serverless Application Model (AWS SAM).
Overall architecture

The application consists of the following resources defined in the AWS SAM template:
- PollerHttpAPI: The front door of the application represented via an API Gateway HTTP API.
- PollerTasksEventBus: An EventBridge event bus that is directly integrated with API Gateway. That means that an API call results in an event being created in the event bus. EventBridge allows you to route the event to the destination you want. It also allows you to archive and replay events as needed, adding resiliency to the architecture. Each event has a unique id that this solution uses for tracing purposes.
- PollerWorkflow: The Step Functions workflow.
- ExternalHttpApi: The API Gateway HTTP API that is used to simulate an external API.
- PayloadGenerator: A Lambda function that is generating a sample payload for the application.
- RawPayloadBucket: An Amazon S3 bucket that stores the payload received from the external API. The Step Functions supported payload size is up to 256 KB. For larger payloads, you can store the API payload in an S3 bucket.
- PollerTasksTable: A DynamoDB table that tracks each poller’s progress. The table has a TimeToLive (TTL) attribute enabled. This automatically discards tasks that exceed the TTL value.
- ProcessPayoadQueue: Amazon SQS queue that decouples our payload fetching mechanism from our payload processing mechanism.
- ProcessPayloadDLQ: Amazon SQS dead letter queue is collecting the messages that we are unable to process.
- ProcessPayload: Lambda function that is processing the payload. The function reports progress of each poller task, marking it as complete when given payload is processed successfully.
Data flow
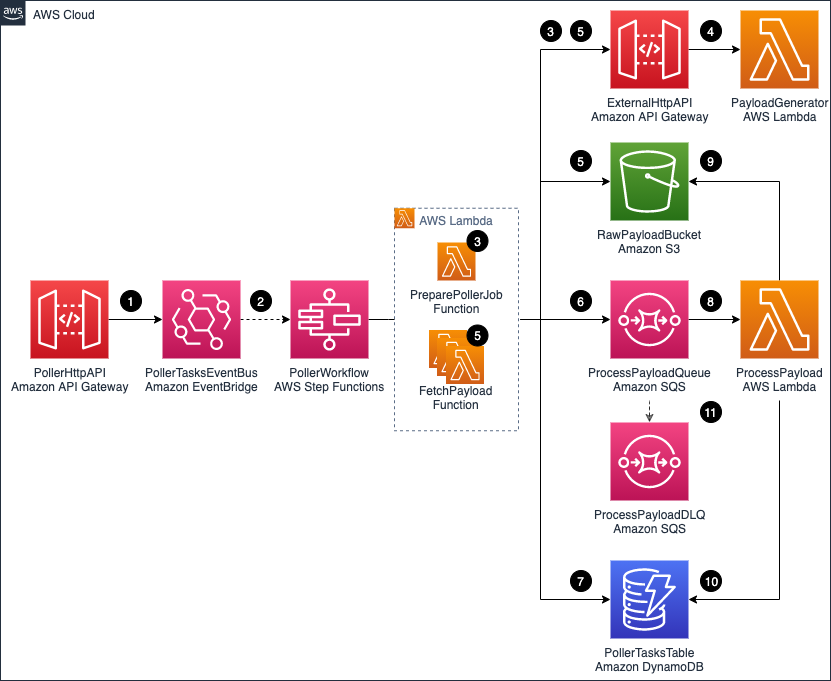
When the API poller runs:
- After a POST call is made to PollerHttpAPI /jobs endpoint, an event containing the API payload is put on the PollerTasksEventBus.
- The event triggers the PollerWorkflow execution. The event payload (including the event unique id) is passed to the PollerWorkflow.
- The PollerWorkflow starts by running the PreparePollerJob function. The function retrieves required metadata from the ExternalHttpAPI. For example, the total number of records to be loaded and maximum records that can be retrieved via a single API call. The function creates poller tasks that are required to fetch the data. The task calculation is based on the metadata received.
- The PayloadGenerator function generates random ExternalHttpAPI payloads. The PayloadGenerator function also includes code that simulates random errors and delays.
- All the tasks are processed in a fan-out fashion using dynamic-parallelism. The FetchPayload function retrieves a payload chunk from the ExternalHttpAPI, and the payload is saved to the RawPayloadBucket.
- A message, containing a pointer to the payload file stored in the RawPayloadBucket, the id of the task, and other task information is sent to the ProcessPayloadQueue. Each message has jobId and taskId attributes. This helps correlate the message with the poller task.
- Anytime a task is changing its status (for example, when the payload is saved to S3 bucket, or when a message has been sent to SQS queue) the progress is reported to the PollerTaskTable.
- The ProcessPayload function is long-polling the ProcessPayloadQueue. As messages appear on the queue, they are being processed.
- The ProcessPayload function is removing an object from the RawPayloadBucket. This is done to illustrate a type of processing that you can do with the payload stored in the S3 bucket.
- After the payload is removed successfully, the progress is reported to the PollerTasksTable. The corresponding task is marked as complete.
- If the ProcessPayload function experiences errors, it tries to process the message several times. If it cannot process the message, the message is pushed to the ProcessPayloadDLQ. This is configured as a dead-letter queue for the ProcessPayloadQueue.
Step Functions state machine
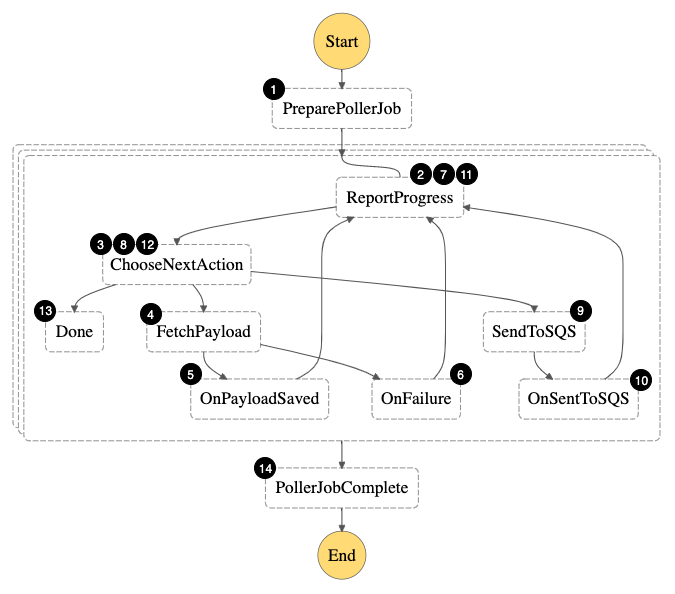
The Step Functions state machine orchestrates the following workflow:
- Fetch external API metadata and create tasks required to fetch all payload.
- For each task, report that the task has entered Started state.
- Since the task is in the Started state, the next action is FetchPayload
- Fetch payload from the external API and store it in an S3 bucket.
- In case of success, move the task to a PayloadSaved state.
- In case of an error, report that the task is in a failed state.
- Report that the task has entered PayloadSaved (or failed) state.
- In case the task is in the PayloadSaved state, move to the SendToSQS step. If the task is in a failed state, exit.
- Send the S3 object pointer and additional task metadata to the SQS queue.
- Move the task to an enqueued state.
- Report that the task has entered enqueued state.
- Since the task is in the enqueued state, we are done.
- Combine the results for a single task execution.
- Combine the results for all the task executions.
Prerequisites to implement the solution
The following prerequisites are required for this walk-through:
- An AWS account.
- The AWS SAM CLI installed.
- Node.js 14, npm, TypeScript, and jq installed.
Step-by-step instructions
You can use AWS Cloud9, or your preferred IDE, to deploy the AWS SAM template. Refer to the cleanup section of this post for instructions to delete the resources to stop incurring any further charges.
- Clone the repository by running the following command:
git clone https://github.com/aws-samples/sam-api-poller.git - Change to the sam-api-poller directory, install dependencies and build the application:
npm install
sam build -c -p - Package and deploy the application to the AWS Cloud, following the series of prompts. Name the stack sam-api-poller:
sam deploy --guided --capabilities CAPABILITY_NAMED_IAM  After stack creation, you see
After stack creation, you see ExternalHttpApiUrl,PollerHttpApiUrl,StateMachineName, andRawPayloadBucketin the outputs section.

- Store API URLs as variables:
POLLER_HTTP_API_URL=$(aws cloudformation describe-stacks --stack-name sam-api-poller --query "Stacks[0].Outputs[?OutputKey=='PollerHttpApiUrl'].OutputValue" --output text) EXTERNAL_HTTP_API_URL=$(aws cloudformation describe-stacks --stack-name sam-api-poller --query "Stacks[0].Outputs[?OutputKey=='ExternalHttpApiUrl'].OutputValue" --output text) - Make an API call:
REQUEST_PYLOAD=$(printf '{"url":"%s/payload"}' $EXTERNAL_HTTP_API_URL) EVENT_ID=$(curl -d $REQUEST_PYLOAD -H "Content-Type: application/json" -X POST $POLLER_HTTP_API_URL/jobs | jq -r '.Entries[0].EventId') - The EventId that is returned by the API is stored in a variable. You can trace all the poller tasks related to this execution via the EventId. Run the following command to track task progress:
curl -H "Content-Type: application/json" $POLLER_HTTP_API_URL/jobs/$EVENT_ID - Inspect the output. For example:
{"Started":9,"PayloadSaved":15,"Enqueued":11,"SuccessfullyCompleted":0,"FailedToComplete":0,"Total":35}% - Navigate to the Step Functions console and choose the state machine name that corresponds to the StateMachineName from step 4. Choose an execution and inspect the visual flow.

- Inspect each individual step by clicking on it. For example, for the PollerJobComplete step, you see:

Cleanup
- Make sure that the `RawPayloadBucket` bucket is empty. In case the bucket has some files, follow emptying a bucket guide.
- To delete all the resources permanently and stop incurring costs, navigate to the CloudFormation console. Select the sam-api-poller stack, then choose Delete -> Delete stack.
Cost optimization
For Step Functions, this example uses the Standard Workflow type because it has a visualization tool. If you are planning to re-use the solution, consider switching from standard to Express Workflows. This may be a better option for the type of workload in this example.
Conclusion
This post shows how to use Step Functions, Lambda, EventBridge, S3, API Gateway HTTP APIs, and SQS to build a serverless API poller. I show how you can deploy a sample solution, process sample payload, and store it to S3.
I also show how to perform clean-up to avoid any additional charges. You can modify this example for your needs and build a custom solution for your use case.
For more serverless learning resources, visit Serverless Land.