AWS Compute Blog
Creating AWS Serverless batch processing architectures
This post is written by Reagan Rosario, AWS Solutions Architect and Mark Curtis, Solutions Architect, WWPS.
Batch processes are foundational to many organizations and can help process large amounts of information in an efficient and automated way. Use cases include file intake processes, queue-based processing, and transactional jobs, in addition to heavy data processing jobs.
This post explains a serverless solution for batch processing to implement a file intake process. This example uses AWS Step Functions for orchestration, AWS Lambda functions for on-demand instance compute, Amazon S3 for storing the data, and Amazon SES for sending emails.
Overview
This post’s example takes a common use-case of a business’s need to process data uploaded as a file. The test file has various data fields such as item ID, order date, order location. The data must be validated, processed, and enriched with related information such as unit price. Lastly, this enriched data may need to be sent to a third-party system.
Step Functions allows you to coordinate multiple AWS services in fully managed workflows to build and update applications quickly. You can also create larger workflows out of smaller workflows by using nesting. This post’s architecture creates a smaller and modular Chunk processor workflow, which is better for processing smaller files.
As the file size increases, the size of the payload passed between states increases. Executions that pass large payloads of data between states can be stopped if they exceed the maximum payload size of 262,144 bytes.
To process large files and to make the workflow modular, I split the processing between two workflows. One workflow is responsible for splitting up a larger file into chunks. A second nested workflow is responsible for processing records in individual chunk files. This separation of high-level workflow steps from low-level workflow steps also allows for easier monitoring and debugging.
Splitting the files in multiple chunks can also improve performance by processing each chunk in parallel. You can further improve the performance by using dynamic parallelism via the map state for each chunk.
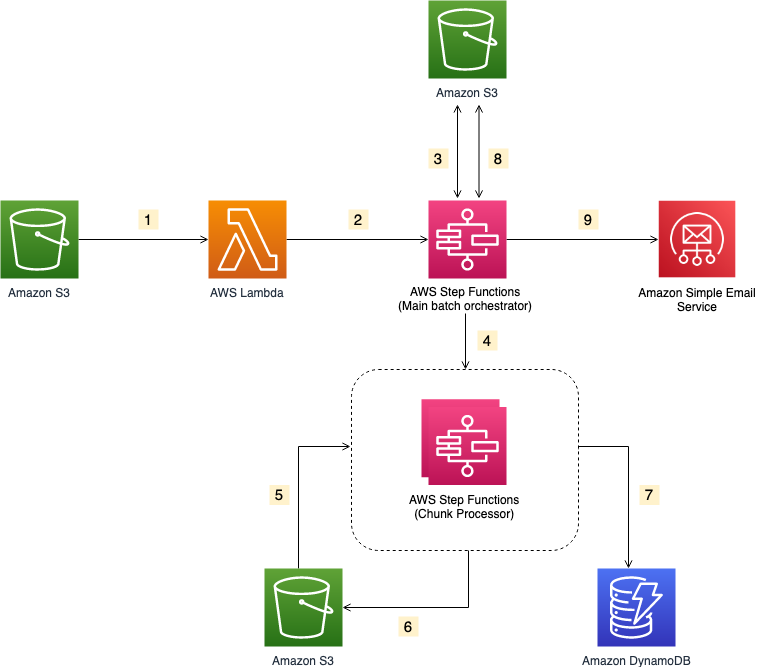
- The file upload to an S3 bucket triggers the S3 event notification. It invokes the Lambda function asynchronously with an event that contains details about the object.
- Lambda function calls the Main batch orchestrator workflow to start the processing of the file.
- Main batch orchestrator workflow reads the input file and splits it into multiple chunks and stores them in an S3 bucket.
- Main batch orchestrator then invokes the Chunk Processor workflow for each split file chunk.
- Each Chunk processor workflow execution reads and processes a single split chunk file.
- Chunk processor workflow writes the processed chunk file back to the S3 bucket.
- Chunk processor workflow writes the details about any validation errors in an Amazon DynamoDB table.
- Main batch orchestrator workflow then merges all the processed chunk files and saves it to an S3 bucket.
- Main batch orchestrator workflow then emails the consolidated files to the intended recipients using Amazon Simple Email Service.

- The Main batch orchestrator workflow orchestrates the processing of the file.
- The first task state Split Input File into chunks calls a Lambda function. It splits the main file into multiple chunks based on the number of records and stores each chunk into an S3 bucket.
- The next state is a map state called Call Step Functions for each chunk. It uses the Step Functions service integration to trigger the Chunk Processor workflow for each chunk of the file. It also passes the S3 bucket path of the split file chunk as a parameter to the Chunk Processor workflow.
- Then the Main batch orchestrator waits for all the child workflow executions to complete.
- Once all the child workflows are processed successfully, the next task state is Merge all Files. This combines all the processed chunks into a single file and then stores the file back to the S3 bucket.
- The next task state Email the file takes the output file. It generates an S3 presigned URL for the file and sends an email with the S3 presigned URL.
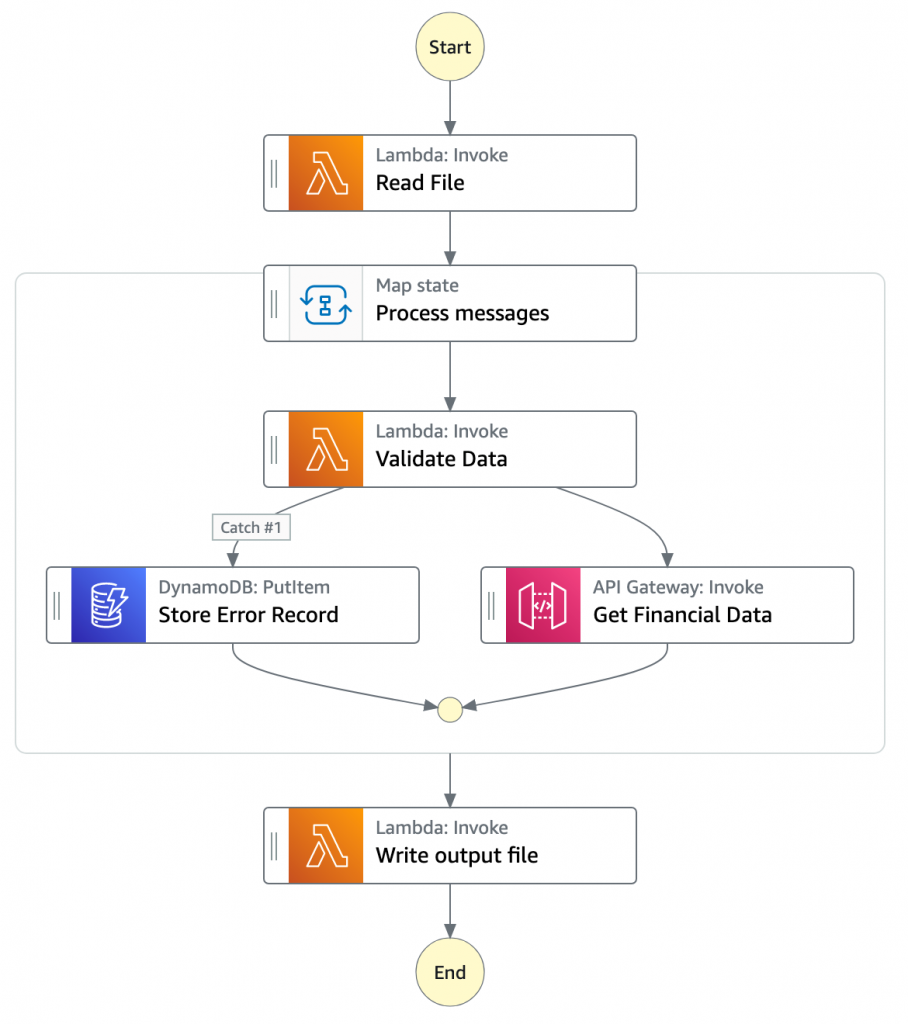
- The Chunk processor workflow is responsible for processing each row from the chunk file that was passed.
- The first task state Read reads the chunked file from S3 and converts it to an array of JSON objects. Each JSON object represents a row in the chunk file.
- The next state is a map state called Process messages. It runs a set of steps for each element of an input array. The input to the map state is an array of JSON objects passed by the previous task.
- Within the map state, Validate Data is the first state. It invokes a Lambda function that validates each JSON object using the rules that you have created. Records that fail validation are stored in an Amazon DynamoDB table.
- The next state Get Financial Data invokes Amazon API Gateway endpoints to enrich the data in the file with data from a DynamoDB table.
- When the map state iterations are complete, the Write output file state triggers a task. It calls a Lambda function, which converts the JSON data back to CSV and writes the output object to S3.

Prerequisites
- AWS account.
- AWS SAM CLI.
- Python 3.
- An AWS Identity and Access Management (IAM) role with appropriate access.
Deploying the application
- Clone the repository.
- Change to the directory and build the application source:
sam build
- Package and deploy the application to AWS. When prompted, input the corresponding parameters as shown below:
sam deploy --guided
 Note the template parameters:
Note the template parameters:
- SESSender: The sender email address for the output file email.
- SESRecipient: The recipient email address for the output file email.
- SESIdentityName: An email address or domain that Amazon SES users use to send email.
- InputArchiveFolder: Amazon S3 folder where the input file will be archived after processing.
- FileChunkSize: Size of each of the chunks, which is split from the input file.
- FileDelimiter: Delimiter of the CSV file (for example, a comma).
- After the stack creation is complete, you see the source bucket created in Outputs.
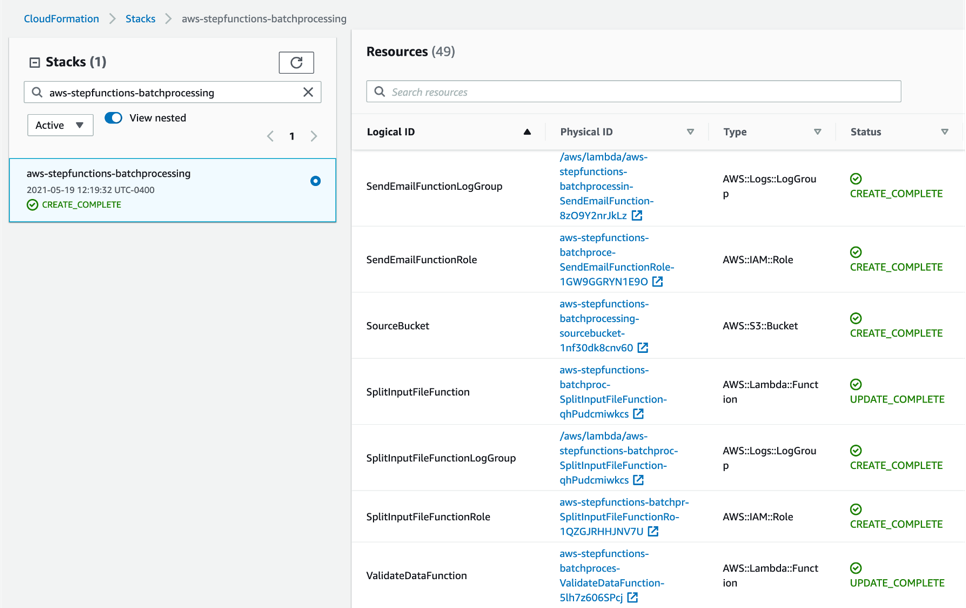
- Review the deployed components in the AWS CloudFormation Console.
Testing the solution
- Before you can send an email using Amazon SES, you must verify each identity that you’re going to use as a “From”, “Source”, “Sender”, or “Return-Path” address to prove that you own it. Refer Verifying identities in Amazon SES for more information.
- Locate the S3 bucket (SourceBucket) in the Resources section of the CloudFormation stack. Choose the physical ID.

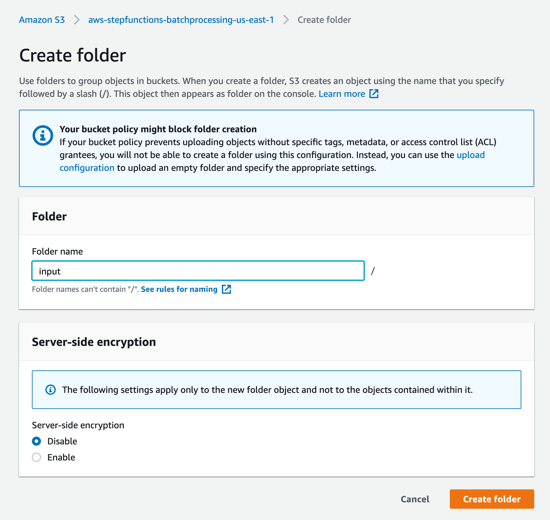
- In the S3 console for the SourceBucket, choose Create folder. Name the folder input and choose Create folder.
- The S3 event notification on the SourceBucket uses “input” as the prefix and “csv” as the suffix. This triggers the notification Lambda function. This is created as a part of the custom resource in the AWS SAM template.

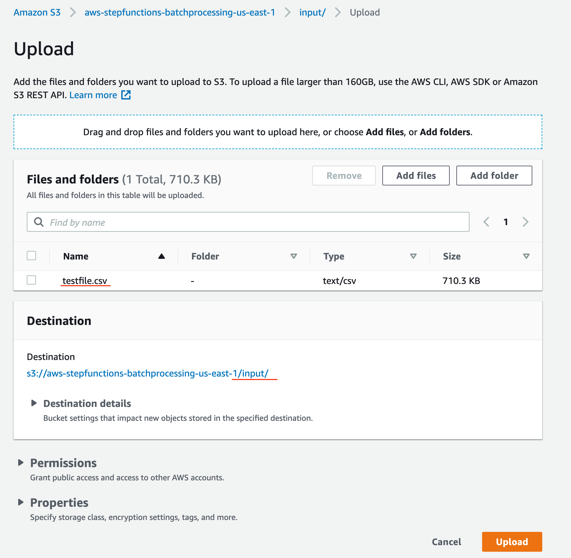
- In the S3 console for the SourceBucket, choose the Upload button. Choose Add files and browse to the input file (testfile.csv). Choose Upload.
- Review the data in the input file testfile.csv.
- After the object is uploaded, the event notification triggers the Lambda Function. This starts the main orchestrator workflow. In the Step Functions console, you see the workflow is in a running state.

- Choose an individual state machine to see additional information.
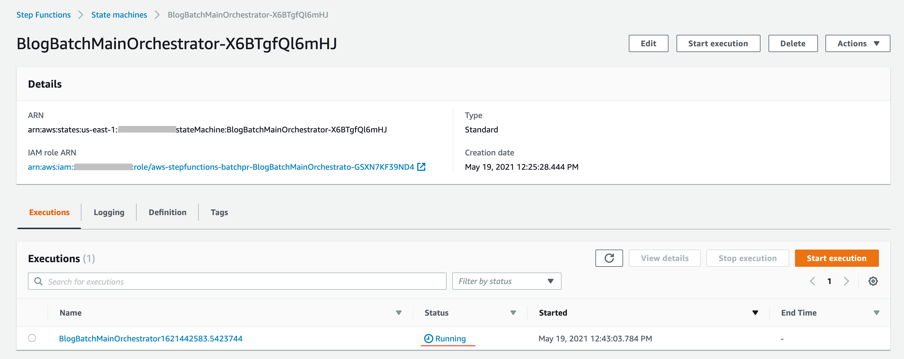
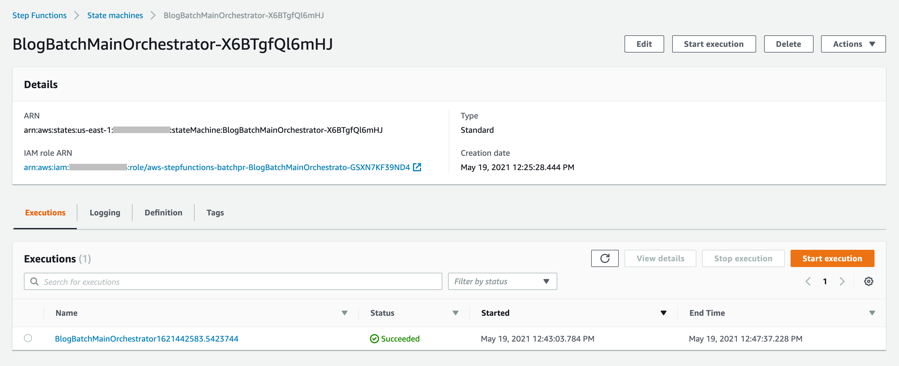
- After a few minutes, both BlogBatchMainOrchestrator and BlogBatchProcessChunk workflows have completed all executions. There is one execution for the BlogBatchMainOrchestrator workflow and multiple invocations of the BlogBatchProcessChunk workflow. This is because the BlogBatchMainOrchestrator invokes the BlogBatchProcessChunk for each of the chunked files.
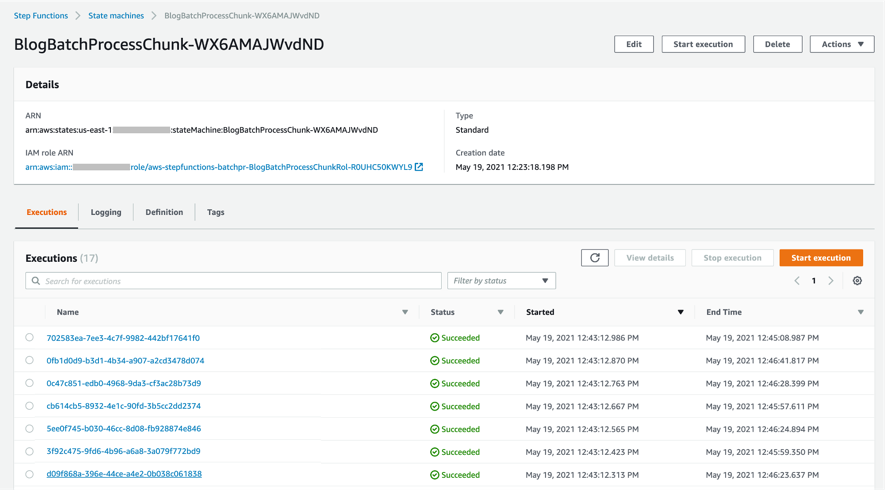

Checking the output
- Open the S3 console and verify the folders created after the process has completed.
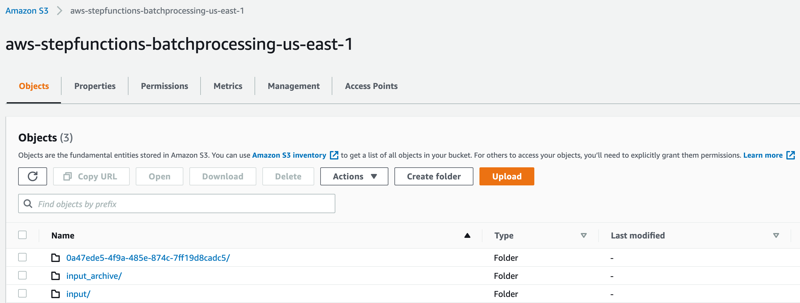
The following subfolders are created after the processing is complete:
– input_archive – Folder for archival of the input object.
– 0a47ede5-4f9a-485e-874c-7ff19d8cadc5 – Subfolder with a unique UUID in the name. This is created for storing the objects generated during batch execution. - Select the folder 0a47ede5-4f9a-485e-874c-7ff19d8cadc5.
output – This folder contains the completed output objects, some housekeeping files, and processed chunk objects.
to_process – This folder contains all the split objects from the original input file.
- Open the processed object from the output/completed folder.
Inspect the output object testfile.csv. It is enriched with additional data (columns I through N) from the DynamoDB table fetched through an API call.

Viewing a completed workflow
Open the Step Functions console and browse to the BlogBatchMainOrchestrator and BlogBatchProcessChunk state machines. Choose one of the executions of each to locate the Graph Inspector. This shows the execution results for each state.
BlogBatchMainOrchestrator:

BlogBatchProcessChunk:

Batch performance
For this use case, this is the time taken for the batch to complete, based on the number of input records:
| No. of records | Time for batch completion |
| 10 k | 5 minutes |
| 100 k | 7 minutes |
The performance of the batch depends on other factors such as the Lambda memory settings and data in the file. Read more about Profiling functions with AWS Lambda Power Tuning.
Conclusion
This blog post shows how to use Step Functions’ features and integrations to orchestrate a batch processing solution. You use two Steps Functions workflows to implement batch processing, with one workflow splitting the original file and a second workflow processing each chunk file.
The overall performance of our batch processing application is improved by splitting the input file into multiple chunks. Each chunk is processed by a separate state machine. Map states further improve the performance and efficiency of workflows by processing individual rows in parallel.
Download the code from this repository to start building a serverless batch processing system.
Additional Resources:
- Orchestration examples with Step Functions
- Create a Serverless Workflow
- Building Business Workflows with AWS Step Functions
- Using a Map State to Call Lambda Multiple Times
For more serverless learning resources, visit Serverless Land.