AWS Compute Blog

Server-side rendering micro-frontends – the architecture
This first post starts the journey into micro-frontends, a distributed architecture for frontend applications. The next post will explore the UI composer and micro-frontends discovery implementations.

Building highly resilient applications with on-premises interdependencies using AWS Local Zones
This blog post is written by Rachel Rui Liu, Senior Solutions Architect. AWS Local Zones are a type of infrastructure deployment that places compute, storage, database, and other select AWS services close to large population and industry centers. Following the successful launch of the AWS Local Zones in 16 US cities since 2019, in Feb 2022, AWS […]

Implementing a UML state machine using AWS Step Functions
This post is written by Michael Havey, Senior Specialist Solutions Architect, AWS This post shows how to model a Unified Modeling Language (UML) state machine as an AWS Step Functions workflow. A UML state machine models the behavior of an object, naming each of its possible resting states and specifying how it moves from one […]

Serverless and Application Integration sessions at AWS re:Invent 2022
AWS re:Invent 2022 is only a few weeks away, featuring an exciting slate of sessions on Serverless and Application Integration. This post highlights many of the sessions we are hosting on Serverless and Application Integration. It groups sessions by theme to help you quickly find the sessions most interesting to you.

Propagating valid mTLS client certificate identity to downstream services using Amazon API Gateway
This blog written by Omkar Deshmane, Senior SA and Anton Aleksandrov, Principal SA, Serverless. This blog shows how to use Amazon API Gateway with a custom authorizer to process incoming requests, validate the mTLS client certificate, extract the client certificate subject, and propagate it to the downstream application in a base64 encoded HTTP header. This […]
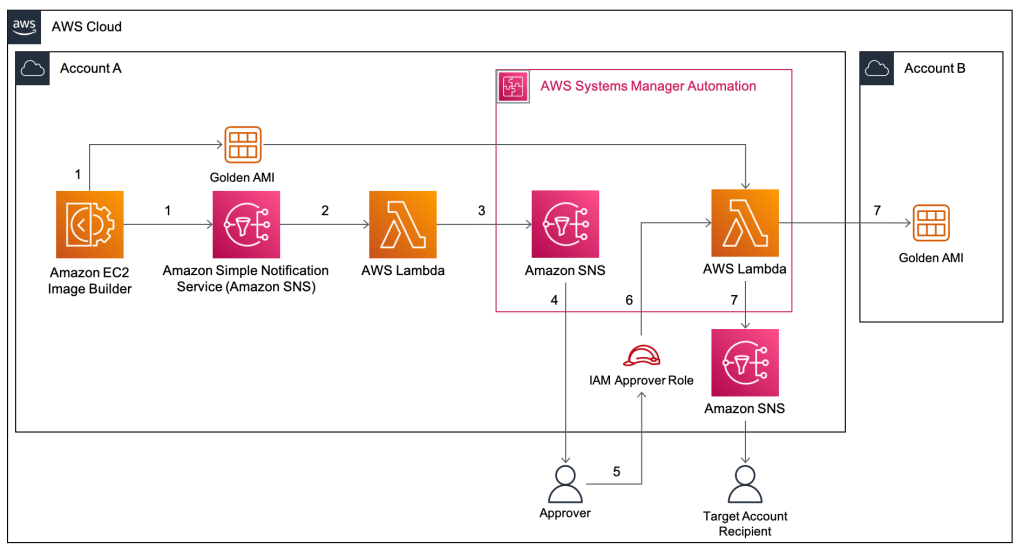
Adding approval notifications to EC2 Image Builder before sharing AMIs
This blog post is written by, Glenn Chia Jin Wee, Associate Cloud Architect, and Randall Han, Professional Services. You may be required to manually validate the Amazon Machine Image (AMI) built from an Amazon Elastic Compute Cloud (Amazon EC2) Image Builder pipeline before sharing this AMI to other AWS accounts or to an AWS organization. […]

Simplifying serverless permissions with AWS SAM Connectors
This post written by Kurt Tometich, Senior Solutions Architect, AWS. Developers have been using the AWS Serverless Application Model (AWS SAM) to streamline the development of serverless applications with AWS since late 2018. Besides making it easier to create, build, test, and deploy serverless applications, AWS SAM now further simplifies permission management between serverless components […]

Best Practices for Hosting Regulated Gaming Workloads in AWS Local Zones and on AWS Outposts
This blog post is written by Shiv Bhatt, Manthan Raval, and Pawan Matta, who are Senior Solutions Architects with AWS. Many industries are subject to regulations that are created to protect the interests of the various stakeholders. For some industries, the specific details of the regulatory requirements influence not only the organization’s operations, but also […]
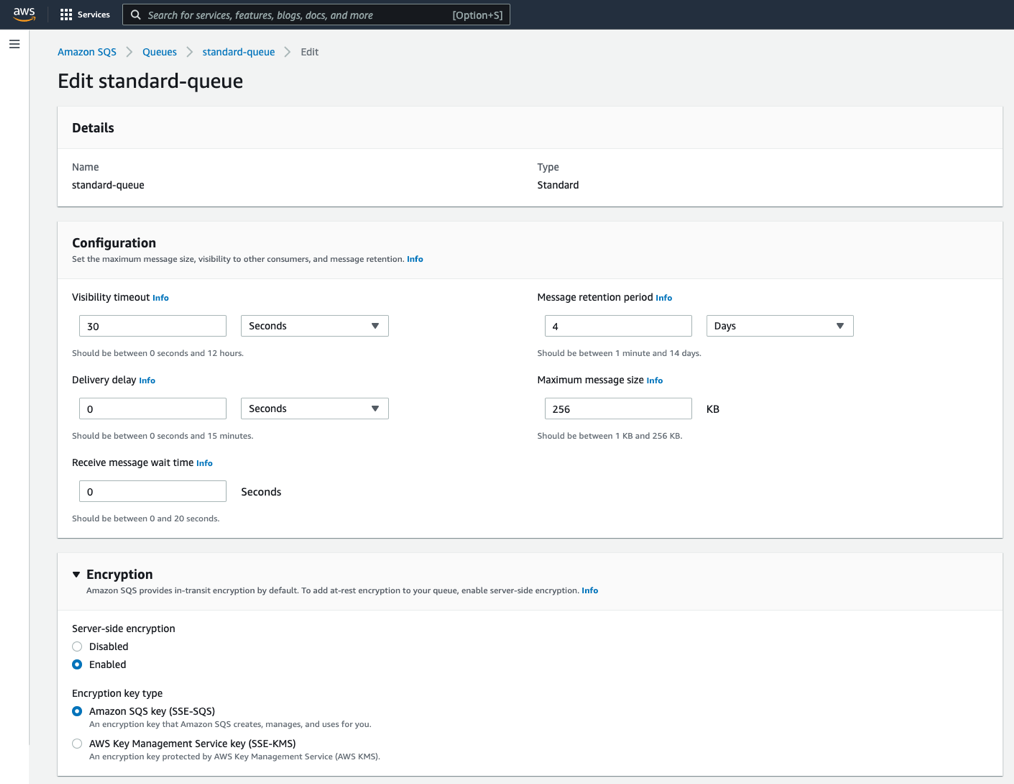
Announcing server-side encryption with Amazon Simple Queue Service -managed encryption keys (SSE-SQS) by default
SQS now provides server-side encryption (SSE) using SQS-owned encryption (SSE-SQS) by default. This enhancement makes it easier to create SQS queues, while greatly reducing the operational burden and complexity involved in protecting data.

ICYMI: Serverless Q3 2022
Welcome to the 19th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed! In case you missed our last ICYMI, check out what happened […]