AWS Compute Blog
Tag: Amazon CloudWatch

Efficiently monitor your On Demand Capacity Reservations (ODCR) by Grouping on CloudWatch Dimensions
This post is written by Ballu Singh, Principal Solutions Architect at AWS, Ankush Goyal, Enterprise Support Lead in AWS Enterprise Support, Hasan Tariq, Principal Solutions Architect with AWS and Ninad Joshi, Senior Solutions Architect at AWS. The On-Demand Capacity Reservations (ODCR) allows you to reserve compute capacity for your Amazon Elastic Compute Cloud (Amazon EC2) […]
Scaling an ASG using target tracking with a dynamic SQS target
This blog post is written by Wassim Benhallam, Sr Cloud Application Architect AWS WWCO ProServe, and Rajesh Kesaraju, Sr. Specialist Solution Architect, EC2 Flexible Compute. Scaling an Amazon EC2 Auto Scaling group based on Amazon Simple Queue Service (Amazon SQS) is a commonly used design pattern in decoupled applications. For example, an EC2 Auto Scaling […]

Enabling load-balancing of non-HTTP(s) traffic on AWS Wavelength
This blog post is written by Jack Chen, Telco Solutions Architect, and Robert Belson, Developer Advocate. AWS Wavelength embeds AWS compute and storage services within 5G networks, providing mobile edge computing infrastructure for developing, deploying, and scaling ultra-low-latency applications. AWS recently introduced support for Application Load Balancer (ALB) in AWS Wavelength zones. Although ALB addresses […]

Monitoring shared AWS Outposts rack capacity
This post is written by Adam Imeson, Sr. Hybrid Edge Specialist Solutions Architect. AWS Outposts rack is a fully-managed service that offers the same AWS infrastructure, APIs, tools, and a subset of AWS services to any data center, colocation space, or on-premises facility for a consistent hybrid experience. Outposts rack is ideal for workloads that […]
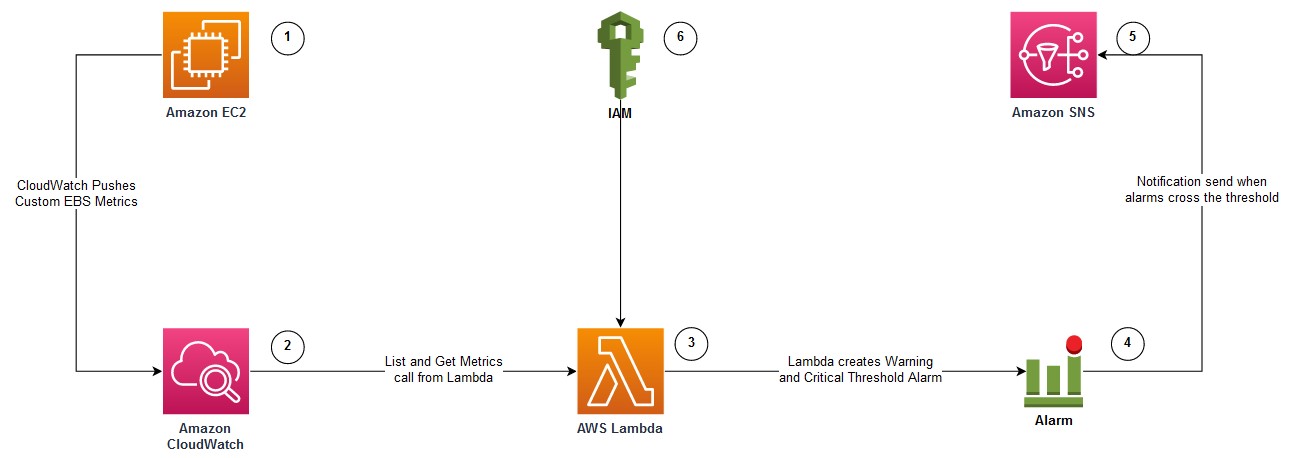
Automating Amazon EC2-Windows EBS Volumes monitoring and creating alarms
This blog post is written by, Santhosh Kumar Adapa, Database Consultant, AWS WWCO ProServe, Jeevan Shetty, Database Consultant, AWS WWCO ProServe, and Bhanu Ganesh Gudivada, Consultant Databases, AWS WWCO ProServe. Customers who are running fleets of Amazon Elastic Compute Cloud (Amazon EC2) instances use advanced monitoring techniques to observe their operational performance. Capabilities like aggregated and […]

Capturing GPU Telemetry on the Amazon EC2 Accelerated Computing Instances
This post is written by Amr Ragab, Principal Solutions Architect EC2. AWS is excited to announce the native integration of monitoring GPU metrics through the CloudWatch Agent. Customers can now easily monitor GPU utilization and its memory to scale their workloads more effectively without custom scripts. In this post, we’ll describe how to allow GPU […]

Optimizing EC2 Workloads with Amazon CloudWatch
This post is written by David (Dudu) Twizer, Principal Solutions Architect, and Andy Ward, Senior AWS Solutions Architect – Microsoft Tech. In December 2020, AWS announced the availability of gp3, the next-generation General Purpose SSD volumes for Amazon Elastic Block Store (Amazon EBS), which allow customers to provision performance independent of storage capacity and provide […]

How to monitor Windows and Linux servers and get internal performance metrics
This post was written by Dean Suzuki, Solution Architect Manager. Customers who run Windows or Linux instances on AWS frequently ask, “How do I know if my disks are almost full?” or “How do I know if my application is using all the available memory and is paging to disk?” This blog helps answer these […]

Monitoring AWS Outposts capacity
This post is authored by Mike Burbey, Sr. Outposts SA AWS Outposts is a fully managed service that offers the same AWS infrastructure, AWS services, APIs, and tools to any data center, colocation space, or on-premises facility for a consistent hybrid experience. AWS Outposts is ideal for workloads that require low latency, access to on-premises […]
Custom logging with AWS Batch
This post was written by Christian Kniep, Senior Developer Advocate for HPC and AWS Batch. For HPC workloads, visibility into the logs of jobs is important to debug a job which failed, but also to have insights into a running job and track its trajectory to influence the configuration of the next job or terminate […]