AWS Database Blog
Optimize the cost of your Amazon ElastiCache for Redis workloads
Customers often use a caching service like Amazon ElastiCache to boost application performance and scale. In this post, we go over 5 different recommendations to optimize the cost of your Amazon ElastiCache for Redis clusters.
Amazon ElastiCache for Redis, a fully managed caching service, is a cost-effective solution that provides ultra-fast response for modern applications. AWS takes care of all the operational aspects of running Redis, including hardware provisioning, software patching, horizontal and vertical scaling, upgrading engine versions, automatic backup and monitoring. This allows customers to focus on their applications rather than managing the underlying infrastructure. These factors make it an attractive choice for customers looking for a hassle-free and highly reliable Redis solution. Refer to Optimize costs by moving your self-managed open source Redis to Amazon ElastiCache to learn more about how you can reduce cost and lower Total Cost of Ownership (TCO) by migrating your open source Redis workload to ElastiCache.
As a first step, determining the optimal size for your cache nodes is important to ensure efficient resource utilization and cost-effectiveness. To perform right sizing in ElastiCache, you need to understand your application’s workload requirements like memory, CPU and network throughput. Based on these workload characteristics, you can choose the right cache node types optimized for different use cases. If your workload is memory-bound, you can select memory optimized ‘R’ instance family. Further, if the dataset is large but only small subset is accessed frequently, then R6gd instances is the right choice as it provides nearly 5x more total storage capacity by utilizing lower cost solid state drives (SSDs) in addition to storing regularly accessed data in memory. If your workload is CPU or network-bound, you can select the general purpose ‘M’ instance family as it provides lower cost per network throughput. To learn more about the network bandwidth of cache nodes, refer ElastiCache supported node types. By continuously monitoring your ElastiCache deployment, you can ensure that it’s appropriately sized to meet your application’s caching needs while optimizing cost and performance.
After right sizing ElastiCache clusters, you can follow the 5 recommendations in this post to further optimize the cost of your ElastiCache for Redis workloads.
1. Use Graviton based instances
In October 2020, AWS announced Graviton M6g and R6g instance families in ElastiCache. The Graviton instance is a custom-designed AWS processor, that is built on 64-bit Arm Neoverse cores, that offers superior performance, efficiency, security for various workloads. With ElastiCache clusters running on these instances, you can achieve better price-performance when compared to x86 instance types, making it an ideal choice for customers looking to reduce their cost. These instances come in different sizes, ranging from large to 16xlarge, offering memory flexibility.
Graviton instances (M6g/R6g) are priced 5% lower than M5/R5 instances on ElastiCache. For use cases that require the highest possible raw performance, the x86-based instances are recommended. If you find that testing with Graviton does not impact your application’s performance, you can easily save 5% by changing the instance type.
ElastiCache offers online scaling for Redis version 3.2.10 and above, which allows you to change your cluster’s node type with minimal disruption to your applications. To change the ElastiCache cluster nodes to m6g/r6g node types, refer to Modifying an ElastiCache cluster.
2. Use reserved instances
ElastiCache offers users the option of purchasing reserved instances to provide cost savings in exchange for time-bound commitment; saving up to 55% when compared to on-demand nodes. You can reserve the instances you need for your ElastiCache clusters in advance for a specific term, based on your application usage. Reserved nodes are available in two term lengths (1 year or 3 years) with three payment options (no up-front, partial up-front, and all up-front). To learn more, refer to ElastiCache reserved nodes.
Table 1 shows the cost savings when using reserved instances for different time durations and payment options.
| Cache node type | On-demand rate ($/hour) | Term length | Payment Option | RI upfront fee ($) | RI effective hourly rate ($) | Savings over On-demand |
| cache.r6g.large
(in the us-east-1 region) |
0.206 | 1 year | No upfront | 0 | 0.141 | 32% |
| Partial upfront | 585 | 0.134 | 35% | |||
| All upfront | 1146 | 0.131 | 36% | |||
| 3 year | No upfront | 0 | 0.107 | 48% | ||
| Partial upfront | 1295 | 0.099 | 52% | |||
| All upfront | 2434 | 0.093 | 55% |
Table 1: Different price options in the us-east-1 region for node type cache.r6g.large
As shown, the all upfront payment option with 3-year term provides the largest discount. Depending on the term length and payment option you choose, you get savings ranging from 32–55% over all the available on-demand instances for ElastiCache making it an attractive option for customers looking to reduce their cost. For more information, refer to Amazon ElastiCache pricing.
3. Achieve over 60% cost savings with data tiering
In November 2021, ElastiCache for Redis introduced data tiering, which provides a new price-performance option for Redis workloads by utilizing lower-cost NVMe solid state drives (SSDs) in each cluster node in addition to storing data in memory. The data tiering feature in ElastiCache for Redis offers a low-cost way to scale your clusters to up to 1 petabyte total capacity. It’s ideal for workloads that access up to 20% of their overall dataset regularly, and for applications that can tolerate additional latency when accessing data on SSD (300 – 450 microseconds on average). Several customers, including Rokt have told us that using data tiering for their workload has had virtually no noticeable performance impact on their applications.
Not all use cases require all the data to be stored in memory. For example, an application accessing only 20% of overall dataset regularly considered as “hot data” can be stored in memory and the rest of 80% of data on SSD to optimize storage costs. When using clusters with data tiering, ElastiCache is designed to automatically and transparently move the least recently used (LRU) items from memory to locally attached NVMe SSDs when available memory capacity is completely consumed. When an item that moves to SSD is subsequently accessed, ElastiCache moves it back to memory asynchronously before serving the request.
ElastiCache data tiering is available when using Redis version 6.2 and above on Graviton-based R6gd nodes. These nodes have nearly five times more total capacity (memory + SSD) and can help you achieve over 60% savings when running at maximum utilization compared to R6g nodes (memory only). The following table 2 compares cache.r6g.xlarge and cache.r6gd.xlarge nodes.
| cache.r6g.xlarge | cache.r6gd.xlarge with Data Tiering | |
| vCPU | 4 | 4 |
| RAM (GiB) | 26.32 | 26.32 |
| SSD (GiB) | 0 | 99.33 |
| Total Capacity (GiB) | 26.32 | 125.65 <– 4.8x capacity |
| Hourly node price | $0.411 | $0.781 |
| Price per GiB-hour | $0.016 | $0.006 <– 66% savings |
Table 2: Compares instances cache.r6g.xlarge vs cache.r6gd.xlarge price in the us-east-1 region.
Reserved Instances are available for data tiering nodes as well which provides further cost savings up to 55%.
4. Automatically scale your ElastiCache clusters to meet demand
ElastiCache for Redis often plays an integral part of architectures. It is designed to improve application performance and reduce burden on your primary database. As workloads grow and applications demand more resources from increased traffic and data growth, it is necessary to scale the ElastiCache footprint accordingly to meet business requirements. In the majority of cases, it is common to overprovision ElastiCache resources to handle the peak volume and to maintain application’s performance resulting in an undesired cost increase. To overcome this challenge, ElastiCache for Redis introduced support for Application Auto scaling to simplify the scaling experience and help customers easily right size their ElastiCache resources.
With autoscaling, ElastiCache automatically scales the clusters in and out by adding or removing shards or read replicas. To use autoscaling, you define and apply a scaling policy that uses Amazon CloudWatch metrics and target values that you assign. ElastiCache for Redis auto scaling uses the policy to increase or decrease the number of instances in response to changes in application workload.
ElastiCache for Redis supports target tracking and scheduled auto scaling policies. With target tracking, you define a target metric and ElastiCache adjusts resource capacity in response to live changes in utilization. The intention is to provide enough capacity to maintain utilization at the target value specified. We recommend that you analyze your workload patterns to identify periods of high and low demand, peak traffic times and seasonal variations. This analysis helps you to determine the appropriate scaling threshold and set the target value appropriately for autoscaling. The threshold value differs for every use case and there is no fixed value. As a best practice, it’s good to start with a target utilization in the range of 70-80% and adjust this value accordingly as you progress.
For a workload which is CPU bound, you can use EngineCPUUtilization CloudWatch metric in the autoscaling policy and scale ElastiCache resources based on the target utilization. Usually, complex operations or high-volume operations cause the engine utilization to increase. Similarly for a workload which is network-bound, you can use NetworkBytesIn and NetworkBytesOut CloudWatch metrics. You can use these metrics to configure your autoscaling settings and take action based on the type of operation driving the load. Identifying the type of operation which is driving the load (CPU or network) help us to configure how autoscaling has to behave. If it is due to read operations, then configure the scaling policy to add replica to the shard or if its due to write operations, then add more shards to your ElastiCache cluster.
For a workload which is memory bound workload, you can use DatabaseMemoryUsagePercentage CloudWatch metric to determine when to scale. You can configure the autoscaling policy to add more shards to your ElastiCache cluster to adjust capacity automatically whenever the value of this metric is above the target value. Conversely, when memory utilization drops below the specified target value, ElastiCache for Redis will remove nodes from your cluster to reduce over-provisioning and lower costs. For an extended example on using metrics to scale your ElastiCache for Redis clusters, refer to Scale your Amazon ElastiCache for Redis clusters with Auto Scaling.
The scheduled auto scaling can help manage the cost for workloads that have a predefined schedule. For example, if you have business hours from 9 AM to 5 PM or follow the sun model, where we see a significant difference in traffic between day and night, you can scale out to distribute the workload among more nodes and scale back in when the workload decreases at specific times.
By considering these factors, you can design and implement an effective autoscaling strategy for your ElastiCache deployment. We highly recommend to periodically review and adjust your autoscaling policies based on the evolving needs of your application. Refer to Auto Scaling ElastiCache for Redis clusters for more details on managing capacity automatically with ElastiCache for Redis auto scaling.
5. Upgrade to ElastiCache for Redis 7 with Enhanced I/O multiplexing
ElastiCache for Redis 7+ offers many enhancements including enhanced I/O multiplexing, which enables you to use the extra cores in the CPU to perform client connection establishment, manage TLS handling, and process Redis commands in pipelines to increase throughput up to 72% and reduce latency by up to 71% per node. For more information, refer to New for Amazon ElastiCache for Redis 7: Get up to 72% better throughput with enhanced I/O multiplexing. Enhanced I/O multiplexing helps to achieve higher throughput when interacting with hundreds or even thousands of clients. In ElastiCache for Redis versions before 7.0.5, high connection concurrency could sometimes exhaust available compute capacity and reduce overall performance. With Enhanced I/O multiplexing, you can reduce the overall footprint of your cluster to handle more requests with fewer nodes. The following diagram illustrates the architecture of this feature.
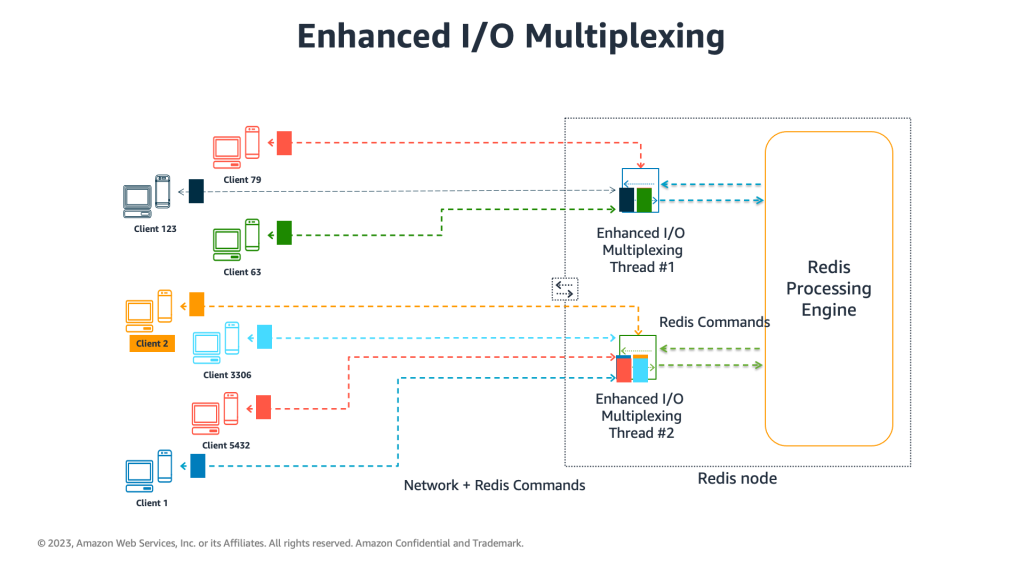
Image 1. Enhanced I/O Multiplexing showing seven Redis clients connected to one ElastiCache for Redis node, with a single threaded processing engine and 2 Enhanced I/O Multiplexing threads that handle connections and pipeline commands from clients to engine.
With this innovation, you can revisit your workload requirements and expectations and reshape the cluster topology to fit your needs. After you analyze your expected throughput in total transactions per second (TPS), the ratio of reads and writes (usually 80/20), and the expected latency, you can run performance tests with the open-source Redis benchmark tool. For example, with 400 clients performing 1,000,000 simple caching operations using GET and SET commands for keys with 500 bytes running on a two-shard cluster with cache.m6g.xlarge instances and one replica per shard, we use the following code (running on a c6gn.4xlarge):
In the following output results, we’re able to get almost 1.2M TPS with an average latency of 600 microseconds consistently in this use case:
You can gauge your own test results and modify the cluster accordingly to reduce or increase the number of shards and replicas or even scale down. Note that enhanced I/O multiplexing is available on nodes with 4+ vCPUs. For more information, refer supported node types.
Conclusion
In this post, we covered the top five recommendations on how to optimize the cost when running ElastiCache for Redis workloads using native ElastiCache features. We talked about lowering ElastiCache costs by utilizing Graviton nodes and reserved instances, avoiding over provisioning and scaling your clusters per business needs with auto scaling, achieving 4.8 times the capacity with two times less cost using data tiering nodes, and enhancing throughput and lowering resource utilization with I/O multiplexing by upgrading to ElastiCache for Redis 7. Contact your AWS account team to get assistance on how to take advantage of these cost-optimization options in your use cases.
Get started today with ElastiCache for Redis. Happy caching!!!
About the authors
 Shirish Kulkarni is a Sr. Solutions Architect specialized in In-Memory NoSQL databases based in Sydney, Australia. He has more than a decade of experience working with various NoSQL databases and architecting highly scalable applications with distributed technologies. He is highly passionate about NoSQL databases and loves helping customers choose the right database for their use case. In his free time, you can see him spending time outdoors playing with his twin kids.
Shirish Kulkarni is a Sr. Solutions Architect specialized in In-Memory NoSQL databases based in Sydney, Australia. He has more than a decade of experience working with various NoSQL databases and architecting highly scalable applications with distributed technologies. He is highly passionate about NoSQL databases and loves helping customers choose the right database for their use case. In his free time, you can see him spending time outdoors playing with his twin kids.
 Roberto Luna Rojas is an AWS Sr. Solutions Architect specialized in In-Memory NoSQL databases based in NY. He works with customers from around the globe to get the most out of in-memory databases one bit at the time. When not in front of the computer, he loves spending time with his family, listening to music, and watching movies, TV shows, and sports.
Roberto Luna Rojas is an AWS Sr. Solutions Architect specialized in In-Memory NoSQL databases based in NY. He works with customers from around the globe to get the most out of in-memory databases one bit at the time. When not in front of the computer, he loves spending time with his family, listening to music, and watching movies, TV shows, and sports.