AWS Database Blog
Perform parallel load for partitioned data into Amazon S3 using AWS DMS
With AWS Database Migration Service (AWS DMS), you can migrate data between SQL, NoSQL, and text-based targets. With Amazon Simple Storage Service (Amazon S3), you can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps. In this post, we demonstrate how to improve load times for migrating data from Amazon Relational Database Service (Amazon RDS) for MySQL into Amazon S3, by using parallel load for partitioned data in AWS DMS v3.4.6 and above. The same principals with parallel load for partitioned data can apply to other relational database source engines.
Partitioned tables
Table partitioning is the practice of dividing a database table into independent parts, which can be distributed across a file system. We don’t dive deep into table partitioning in this post, because there are many variations within different database engines, but it’s useful to know some of the benefits, as well as when partitioning a table can be effective.
Partitions allow you to define conditions for the data in your table, and determine which partition data will belong to. For example, consider a table of orders for a busy ecommerce platform. If you partition on the month and year of the order date, all orders placed in January 2022 will be in one partition, and all orders for February 2022 will be in another. When you query order data for February 2022 (with appropriate predicates), data from partitions outside of this range can be excluded, which can result in more optimized queries. Similarly, when the January 2022 data is no longer required and has been archived, dropping the partition is a much cheaper and quicker operation than deleting the data, without affecting data for other months in other partitions.
Parallel load for partitioned data
AWS DMS allows you to configure a parallel full load of partitioned data within your migration task, when using Amazon S3 as a target and a supported database engine as a source. During the full load, data is migrated to the target using parallel threads and stored in subfolders mapped to the partitions of the source database objects. Three parallel load rule types are available. If the source object has partitions defined, you can use partitions-auto and partitions-list to automatically identify the partitions to load from the source metadata. For objects without partitions, but where the data can be defined by ranges or boundaries (for example, using date/time values), you can use partitions-range to specify the segments to be loaded. For more information on using partitions-range, see AWS Database Migration Service improves migration speeds by adding support for parallel full load and new LOB migration mechanisms.
Testing performance of parallel load for partitioned data
Although you can partition almost any table with appropriate partition types and values, larger tables with high volumes of data typically see the most benefit. In this post, we use the MySQL Employees sample database as a source, which utilizes RANGE partitioning for the salaries table. For more information on MySQL 5.7 partitioning types, refer to Partitioning Types.
Additional data has been added within the salaries table, bringing the total row count to just over 364 million rows and the table size to just over 25 GB. This database is running on an Amazon RDS t3.large instance. To perform the data migration, a t3.medium replication instance has been provisioned using AWS DMS. A source endpoint has been created to connect to the source MySQL database, and a target endpoint has been created to connect to a target bucket in Amazon S3. For more information on setting up AWS DMS replication instances and replication tasks, refer to the AWS DMS User Guide.
This exercise consists of four separate runs of a full load task in AWS DMS. The first two tasks are run on comparatively low-powered hardware. The first is run without parallel load to establish a baseline, and the second enables this feature in order to compare performance. The next two tasks are run on comparatively high-powered hardware, first without parallel load and then with, in order to understand the impact of both the setting itself and the hardware used.
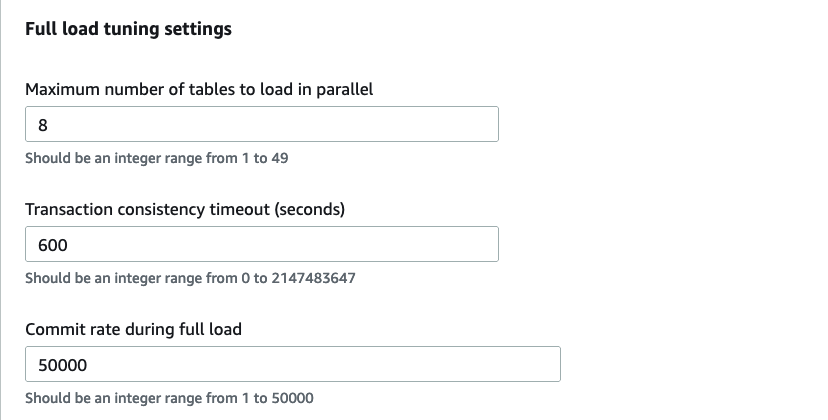
In our first example, we use a database migration task to load the data from our source salaries table into our target S3 bucket without utilizing parallel load. This task has been configured with all settings as default, with the exception of the Commit rate during full load setting, which has been changed to 50,000 rows from the default of 10,000 rows.
The following image shows the full load tuning settings via the AWS Console.
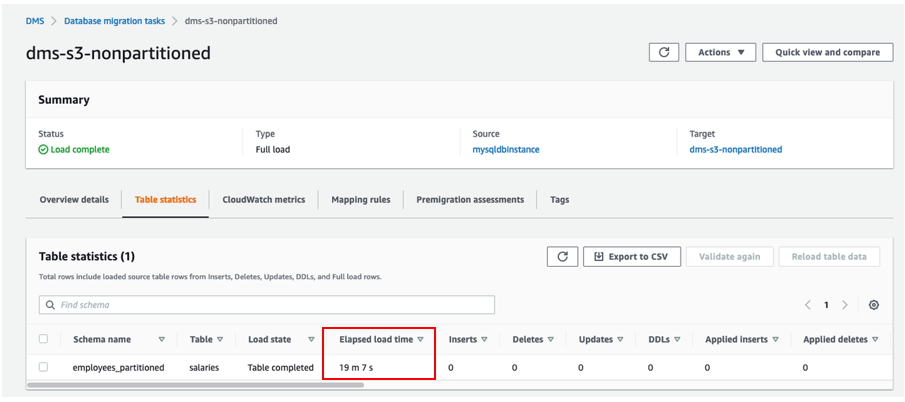
The following image shows the output for the DMS task without parallel load, which completes in 19 minutes and 7 seconds.
Next, we repeat the process using the same resources, but with a database migration task configured to utilize parallel load for partitioned data. The following JSON describes the task configuration for AWS DMS task mapping to specify data on source:
The following image shows the output for the DMS task with parallel load, which completes in 17 minutes and 29 seconds.

With parallel load enabled, the task runtime is reduced by 8.5%. The following screenshots are Amazon CloudWatch metrics showing an increase in average CPU utilization and network receive throughput on the AWS DMS replication instance, as well as a higher average CPU utilization on the RDS DB instance.
The following CloudWatch metric shows the CPU utilization for the AWS DMS instance.

The following CloudWatch metric shows the network receive throughput for the AWS DMS instance.

The following CloudWatch metric shows the CPU utilization for the RDS DB instance.

To understand the impact of the chosen hardware, and the considerations to make when using the parallel load setting, we now repeat the same test using more powerful instances. The RDS DB instance is modified to an r5.8xlarge, and the AWS DMS replication instance is modified to a c5.12xlarge.
When we run a repeat of our first example on the new hardware, without parallel load, the task completes in 6 minutes and 37 seconds. The increased hardware capability has led to a reduction in load time against the first test of approximately 65%.
The following image shows the output for the DMS task without parallel load.

Lastly, we repeat our second example and utilize the parallel load feature. This task completes in 3 minutes and 36 seconds, with a reduction in load time of approximately 45% when compared with the previous task run on equivalent hardware.
The following image shows the output for the DMS task with parallel load.

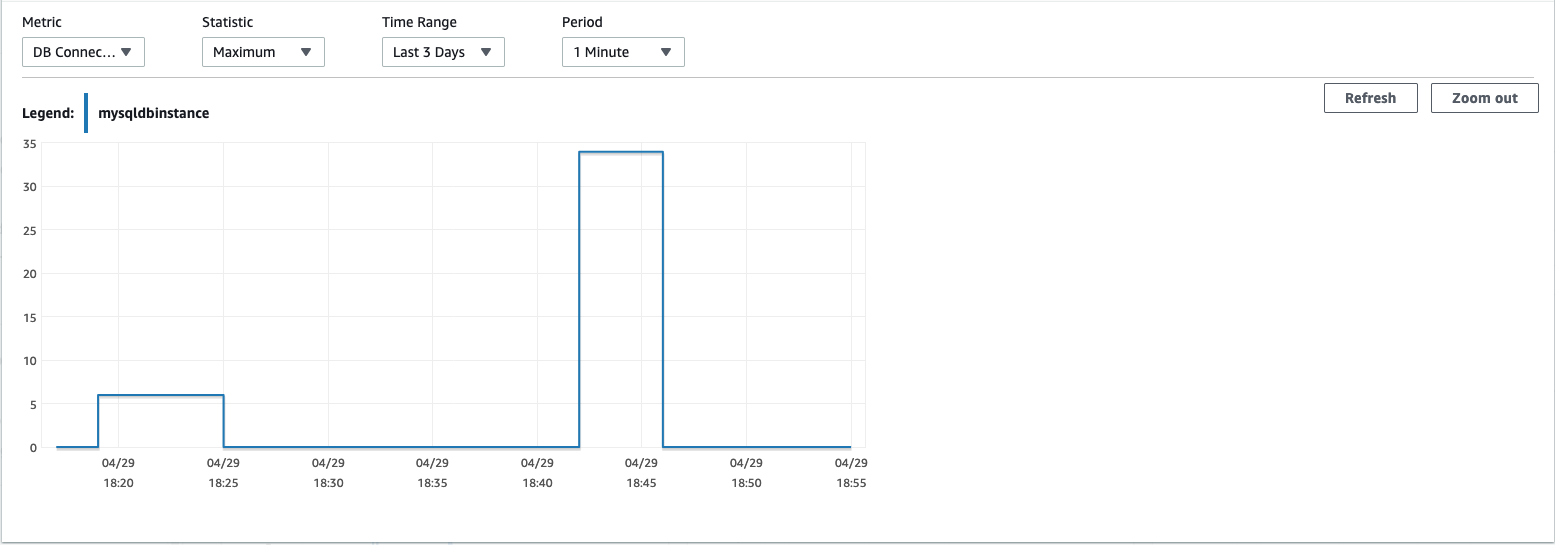
The following CloudWatch metrics show increases in network transmit throughput and CPU utilization on the AWS DMS replication instance, as well as a higher number of connections to the source RDS DB instance, when the parallel load setting is enabled.
The following CloudWatch metric shows the network transmit throughput on the AWS DMS instance.

The following CloudWatch metric shows CPU utilization on the AWS DMS instance.

The following CloudWatch metric shows the database connections on the RDS DB instance.
The following table summarizes our results.
| AWS DMS Instance | Amazon RDS Instance | Parallel Load? | Runtime |
| t3.medium | t3.large | No | 19 mins 7 secs |
| t3.medium | t3.large | Yes | 17 mins 29 secs |
| c5.12xlarge | r5.8xlarge | No | 6 mins 37 secs |
| c5.12xlarge | r5.8xlarge | Yes | 3 mins 36 secs |
Conclusion
In this post, we demonstrated how to use parallel load for partitioned data in AWS DMS version 3.4.6 to improve data migration times into Amazon S3. We also highlighted how the chosen hardware can affect performance, with more improvement realized on comparatively more powerful hardware. We recommend performing sufficient testing or proof of concept evaluations in a separate environment prior to modifying or enabling any settings or features for a production migration.
To learn more about using parallel load for partitioned data please see the documentation.
Disclaimer: The testing done in this post is not a real performance test and your own workload may vary.
About the authors
 Robert Daly is a Senior Database Specialist Solutions architect at AWS, focusing on RDS, Aurora and DMS Services. He has helped multiple enterprise customers move their databases to AWS, providing assistance on performance and best practices. Robert enjoys helping customers build technical solutions to solve business problems.
Robert Daly is a Senior Database Specialist Solutions architect at AWS, focusing on RDS, Aurora and DMS Services. He has helped multiple enterprise customers move their databases to AWS, providing assistance on performance and best practices. Robert enjoys helping customers build technical solutions to solve business problems.
 Lawrence Britt is a Database Specialist Solutions Architect at AWS based in London. In his role he helps customers across the UK and Ireland to migrate, modernise, and optimise database solutions on AWS.
Lawrence Britt is a Database Specialist Solutions Architect at AWS based in London. In his role he helps customers across the UK and Ireland to migrate, modernise, and optimise database solutions on AWS.