AWS Database Blog
Serverless Scaling for Ingesting, Aggregating, and Visualizing Apache Logs with Amazon Kinesis Firehose, AWS Lambda, and Amazon Elasticsearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
Pubali Sen and Shankar Ramachandran are solutions architects at Amazon Web Services.
In 2016, AWS introduced the EKK stack (Amazon Elasticsearch Service, Amazon Kinesis, and Kibana, an open source plugin from Elastic) as an alternative to ELK (Amazon Elasticsearch Service, the open source tool Logstash, and Kibana) for ingesting and visualizing Apache logs. One of the main features of the EKK stack is that the data transformation is handled via the Amazon Kinesis Firehose agent. In this post, we describe how to optimize the EKK solution—by handling the data transformation in Amazon Kinesis Firehose through AWS Lambda.
In the ELK stack, the Logstash cluster handles the parsing of the Apache logs. However, the Logstash cluster must be designed and maintained for scale management. This type of server management requires a lot of heavy lifting on the user’s part. The EKK solution eliminates this work with Amazon Kinesis Firehose, AWS Lambda, and Amazon Elasticsearch Service (Amazon ES).
Solution overview
Let’s look at the components and architecture of the EKK optimized solution.
Amazon Kinesis Firehose
Amazon Kinesis Firehose provides the easiest way to load streaming data into AWS. In this solution, Firehose helps capture and automatically load the streaming log data to Amazon ES, and backs it up in Amazon S3. For more information about Firehose, see What is Amazon Kinesis Firehose?
AWS Lambda
AWS Lambda lets you run code without provisioning or managing servers. It automatically scales your application by running code in response to each trigger. Your code runs in parallel and processes each trigger individually, scaling precisely with the size of the workload. In the EKK solution, Amazon Kinesis Firehose invokes the Lambda function to transform incoming source data and deliver the transformed data to the managed Amazon ES cluster. For more information about AWS Lambda, see the AWS Lambda documentation.
Amazon Elasticsearch Service
Amazon ES is a popular search and analytics engine that provides real-time application monitoring and log and clickstream analytics. In this solution, the Apache logs are stored and indexed in Amazon ES. As a managed service, Amazon ES is easy to deploy, operate, and scale in the AWS Cloud. Using a managed service eliminates administrative overhead, including patch management, failure detection, node replacement, backups, and monitoring. Because Amazon ES includes built-in integration with Kibana, it eliminates having to install and configure that platform—simplifying your process even more. For information about Amazon ES, see What Is Amazon Elasticsearch Service?
Amazon Kinesis Data Generator
This solution uses the Amazon Kinesis Data Generator (KDG) to produce the Apache access logs. The KDG makes it easy to simulate Apache access logs and demonstrate the processing pipeline and scalability of the solution.
Architecture
The following diagram shows the architecture of the EKK optimized stack.
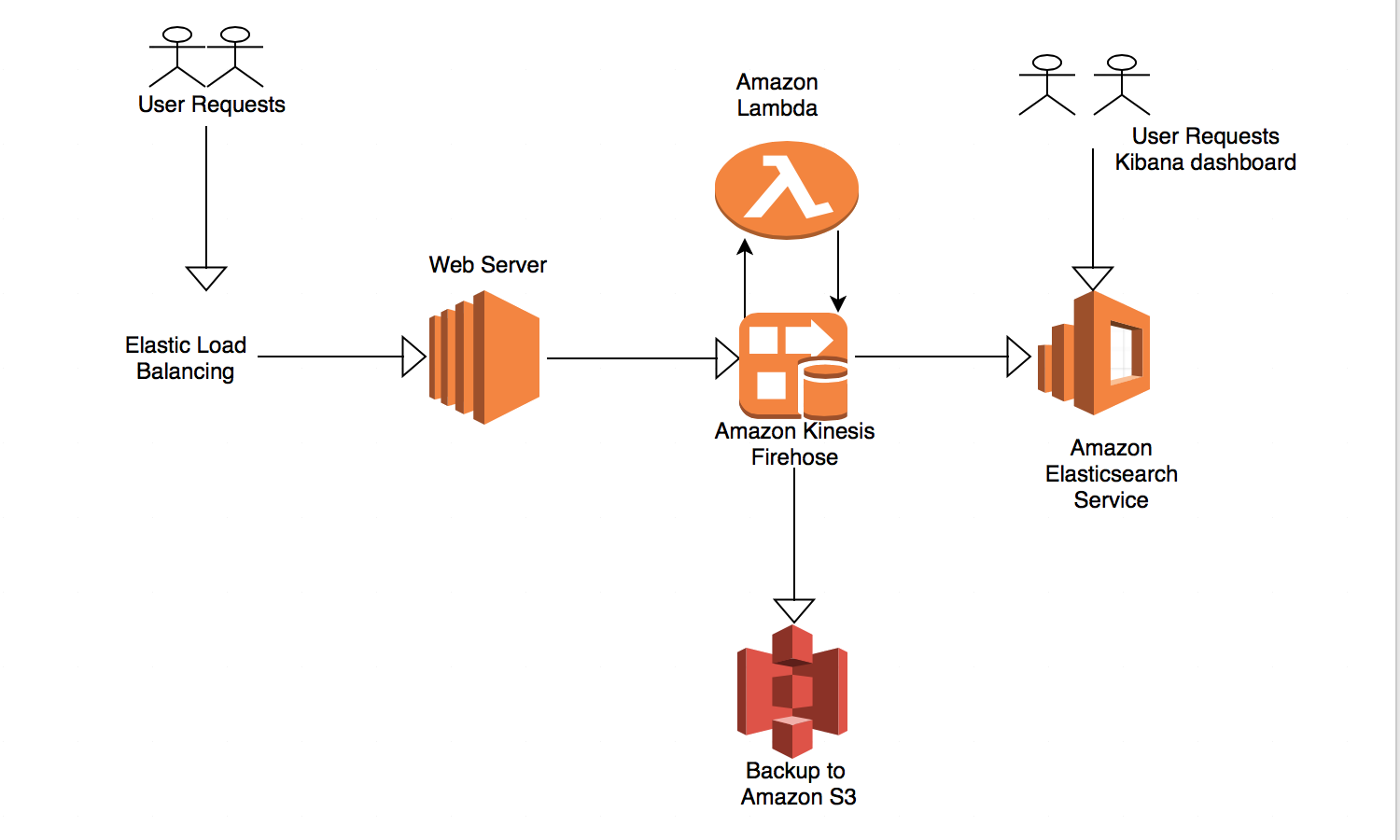
Configuring the EKK optimized stack
This section describes the steps for setting up the EKK optimized solution. (Feel free to set it up in any Region you want.)
Create the AWS Lambda function for data transformation
Firehose provides the following Lambda blueprints that you can use to create a Lambda function for data transformation:
- General Firehose Processing:Contains the data transformation and status. Use this blueprint for any custom transformation logic.
- Apache Log to JSON:Parses and converts Apache log lines to JSON objects, using predefined JSON field names.
- Apache Log to CSV:Parses and converts Apache log lines to CSV format.
- Syslog to JSON:Parses and converts Syslog lines to JSON objects, using predefined JSON field names.
- Syslog to CSV:Parses and converts Syslog lines to CSV format.
In the AWS Lambda console, create a new Lambda function by selecting the kinesis-firehose-apachelog-to-json blueprint. Set the timeout for the Lambda function to one minute.
Attach Amazon ES and Amazon CloudWatch Logs full access policies to the Lambda function. By attaching the Amazon ES permission, you allow the Lambda function to write to the logs in the Amazon ES cluster. The CloudWatch Logs access will help you monitor the Lambda function.
Set up the Elasticsearch cluster
Create the Amazon ES domain in the Amazon ES console or by using the create-elasticsearch-domain command in the AWS CLI.
This example uses the following configuration:
- Domain Name: LogESCluster
- Elasticsearch Version: 1
- Instance Count: 2
- Instance type:medium.elasticsearch
- Enable dedicated master: true
- Enable zone awareness: true
Other settings are left as default.
Set up the Firehose delivery stream and link the Lambda function
In the Firehose console, create a new delivery stream with Amazon ES as the destination. In the Configuration section, enable data transformation, and choose the generic Firehose processing Lambda function that was created from the blueprint.
For detailed steps in this process, see Create a Firehose Delivery Stream to Amazon Elasticsearch Service.

Create an Amazon Cognito user and sign in to the KDG
Before you can send data to Amazon Kinesis, you must create an Amazon Cognito user in your AWS account with permissions to access Amazon Kinesis. To simplify this process, a Lambda function and an AWS CloudFormation template are provided to create the user and assign just enough permissions to use the KDG. To learn more, see the KDG Help page.
You can create the CloudFormation stack by clicking the following link. This link takes you to the AWS CloudFormation console and starts the stack creation wizard.
09/20/2021: We’re updating the following link. Please refer back to this post in a day or two for the most accurate and helpful information.
Create an Amazon Cognito user with AWS CloudFormation
Provide a username and password for the user that you will use to sign in to the Amazon Kinesis Data Generator. Accept the defaults for the other options.
After you create the CloudFormation stack, you must use a special URL to access the Amazon Kinesis Data Generator. AWS CloudFormation creates this URL as part of the stack generation. To get the URL, choose the CloudFormation stack, and then choose the Outputs tab as shown in the following screenshot. Bookmark this URL in your browser for easy access to the KDG.

Click the URL and sign in to the KDG using the username and password you provided while setting up the CloudFormation stack.
Set up the KDG record template for the Apache access logs
The Amazon Kinesis Data Generator can generate records using random data based on a template that you provide. The record template can be of any type: JSON, CSV, or unstructured. The KDG creates a unique record based on the template, replacing your template records with actual data.
The following shows the template for the Apache logs:
{{internet.ip}} - - [{{date.now("DD/MMM/YYYY:HH:mm:ss ZZ")}}] "GET /index.html HTTP/1.1" 200 104 "-" "ELB-HealthChecker/1.0"
In the KDG, set Records per Second to 100.
To start the data streaming, choose Send Data to Amazon Kinesis.
Data transformation
The following shows the Apache logs before transformation:

The following shows the Apache logs after transformation:
File backup in Amazon S3
The raw files are backed up in Amazon S3. The following shows the Amazon S3 console.

Monitoring and troubleshooting the Firehose delivery stream
The Amazon Kinesis Firehose console helps you monitor and troubleshoot the data delivery and data transformation.

The following screenshot shows the details of the log delivery to Amazon S3 and Amazon ES. Notice that there were errors while delivering the logs to the Elasticsearch cluster.

Setting up Kibana for the Elasticsearch cluster
Amazon ES provides a default installation of Kibana with every Amazon ES domain. You can find the Kibana endpoint on your domain dashboard in the Amazon ES console. (You can restrict Amazon ES to an IP-based access policy.)
In Kibana, for the Index name or pattern, type logdiscovery. This is the name of the Amazon ES index that you created for the web server access logs.
In the Time-field name list, choose @timestamp_utc.

On the Kibana console, choose the Discover tab on the left side to view the Apache access logs.

Conclusion
This post described how to transform and ship Apache logs using a serverless architecture. Firehose and AWS Lambda automatically scale up or down based on the rate at which your application generates logs. You can increase the records per second in the Amazon Kinesis Data Generator to easily test the end-to-end scalability of this solution. This solution addresses the challenges encountered in Logstash—that is, hard-to-manage scaling and tedious cluster management.
To learn more about scaling Amazon ES clusters, see the Amazon Elasticsearch Service Developer Guide.
Managed services like Amazon Kinesis Firehose, AWS Lambda, and Amazon ES simplify provisioning and managing a log aggregation system. The ability to run transformations and add any custom transformation logic against your streaming log data using AWS Lambda further strengthens the case for using an EKK optimized stack.