Desktop and Application Streaming
Business Continuity and Disaster Recovery with Amazon WorkSpaces
In my customer conversations, I am frequently asked how customers can use Amazon WorkSpaces in their Disaster Recovery (DR) and Business Continuity Planning (BCP). Questions involve what are the design options for their Amazon WorkSpaces service, and what other services must be planned for. This is especially important when end users are running Amazon WorkSpaces as their primary desktop. This blog post covers the following frequently asked topics:
- Standard out of the box capabilities for the Amazon WorkSpaces service
- Infrastructure considerations
- User environment
- DR Deployment models
- Validating your DR plans
The most important part of the conversation with customers is to help them define what their business needs from a DR plan what constitutes a DR, what the timelines are before they execute their DR plans and what the timelines are on having a DR execution completed. As an example, a customer of mine needed to build a BCP and DR plan to cover a scenario where a portion of their workforce needed to go home (and continue working from home) due to a natural disaster. They needed their DR plans executed within 4 hours. In this scenario, the customer must ensure that their WorkSpaces fleet was also able to withstand this disaster.
Out of the box fault tolerance and availability for Amazon WorkSpaces
Let’s drop back to basics to make sure we are all level set and we can then build on the picture – AWS Cloud infrastructure is built around Regions and Availability Zones. AWS Regions provide multiple, physically separated and isolated Availability Zones, which are connected with low latency, high throughput, and highly redundant networking. Availability Zones offer AWS customers an effective way to design and operate applications and databases, making them more highly available, fault tolerant, and scalable than traditional single data center infrastructures or multi-datacenter infrastructures.
When you deploy Amazon WorkSpaces, each WorkSpace is associated with a specific Amazon Virtual Private Cloud (VPC) and AWS Directory Service construct you used to create it. All AWS Directory Service services require two subnets to operate. Each should be placed in different Availability Zones. There is no need to build out your own complex, highly available directory topology. This is because each directory is deployed across multiple Availability Zones, and monitoring automatically detects and replaces domain controllers that fail.
Each user you provision a WorkSpace for must exist in an AWS Directory Service. Your options here are to use a Simple Active Directory, AWS managed Microsoft Active Directory or Active Directory Connector.
WorkSpaces environments are deployed across two Availability Zones (AZ) in your AWS Account. The deployments into each AZ occur in a round robin to maintain an even split into each AZ.
For each WorkSpace deployed, there are two Amazon EBS volumes present. Amazon EBS volumes are designed to be highly available and reliable. At no additional charge to you, Amazon EBS volume data is replicated across multiple servers in an Availability Zone. This prevents the loss of data from the failure of any single component.
The two EBS volumes are visible to the end user as a System and User drive within the WorkSpace. When a WorkSpace instance is first launched, the system and user EBS volumes are created from the original base Image that was used as the bundle template for that WorkSpace.
Your user is then able to customize the storage on these volumes by installing additional applications (assuming they have appropriate permissions to do so), customizing their user profile, and adding documents and files.
Both the System and User EBS volumes are now automatically snapshotted (using EBS Snapshots) every 12 hours, which gives your users and administrators an easy path to roll the WorkSpace back to a last known good configuration. These EBS snapshots are stored in Amazon Simple Storage Service (S3), where the snapshots are replicated across a minimum of three Availability Zone to protect against the loss of one entire AZ.
Now that we have established that a WorkSpace Instance and its EBS Volumes are deployed into a Single-AZ, the key architectural components (to support your WorkSpaces deployment) are deployed across multiple Availability Zones, and we automatically snapshot the EBS Volumes every 12 hours. What happens during an AZ impacting event?
We give this choice to you as our customer to decide what to do here, and for good reason (which should be self-explanatory as you read on). You have two options:
- Wait for the AZ to come back to normal operations (do nothing, noting that half of your WorkSpaces fleet may be impacted for the duration).
- Execute your BCP plans and take action, to do this you can Perform a “Rebuild” of the impacted WorkSpaces. This will launch a new WorkSpace instance for each user with the System volume coming from the Image and the User volume coming from the latest EBS Snapshot (which could be up to 12 hours old). New documents or files saved post the snapshot will be lost) – This new WorkSpace instance will be launched into the Healthy AZ.
Our standard Amazon WorkSpaces Architecture Diagram is below:
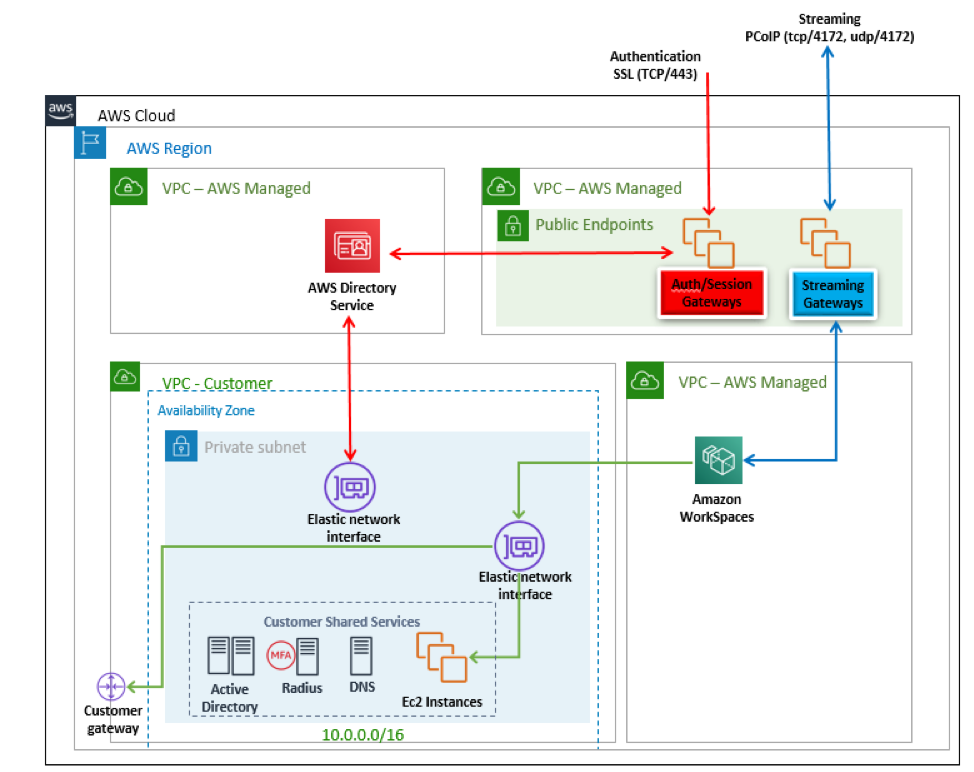
If you break this down and look deeper under the covers, the underlying infrastructure has been deployed across multiple Availability Zones (make note of the multiple Availability Zones):

Additional Infrastructure considerations
Depending on your infrastructure deployment, and desired DR recovery objectives you may also want to think about:
- Active Directory Domain Controller placement
- RADIUS Server placement (if you are using MFA)
- Supporting ancillary infrastructure services (such as DNS, application deployment, patch management, A/V management etc.)
- Supporting application infrastructure such as file shares, database, and email servers
AWS Best Practices are to have these hosted in AWS either as Managed Service offerings (if applicable) or on EC2 instance (which ensures you have the lowest backend latency as possible) and have them replicated in multiple Availability Zones.
We have customers who choose to run their Domain Controllers and other supporting infrastructure on premises and use an AWS Direct Connect to connect their private VPCs and their on premises network together. For this type of deployment, I encourage customers to look deeper at their network configuration here to eliminate single points of failure in the network path. AWS has established architecture patterns to give customers further resiliency here. I always recommend at least a failover IPSecVPN, a second redundant Direct Connect connected to a different AWS Direct Connect point of presence (which can be used in an Active/Active manner). Taking it a step further, customers can also use multiple Direct Connects terminating to different data centers on the customers’ side to increase resiliency.
WorkSpaces User Environment
Now you have looked at the underlying Amazon WorkSpaces infrastructure and the infrastructure that supports the Amazon WorkSpaces deployment. Let’s dig deeper on the user’s working environment.
In the out of the box Amazon WorkSpaces solution that has been described so far, the user’s user profile and documents are stored on an EBS Volume, which has a volume level snapshot taken every 12 hours. This means at worst your recovery point objective (RPO) for their documents and storage is 12 hours. The files also exist in the WorkSpace (meaning the user must be logged into that WorkSpace to be able to access their files).
Customers can extend on the WorkSpaces solution offering by implementing additional measures to reduce recovery and restoration times. Roaming User Profiles or User Profile Synchronization (using either standard Windows technologies or third-party solutions to file shares on EC2 is one such example. Amazon FSx can also be used with WorkSpaces (a fully managed Windows file storage service) as another option. Additionally, some APN Partners such as LiquidWare ProfileUnity have solutions on the AWS Marketplace.
These additional overlay services help your end users to reduce their risk profile by giving them the ability to store and synchronize their documents to a Cloud-based service, and gives them the added benefit of document sharing and collaboration at the same time.
If you have made it this far, what are the next steps?
From customer engagements I have worked on for DR, here is a summary of what works:
- For customers that are on a tight budget I would suggest that they stay with the Single Region (Multi-Availability Zone) deployment.
- For customers who need a greater re-assurance, a higher recovery point, and have recovery time objectives, a Pilot Light deployment in another AWS Region is a good price balance.
- For customers who need a very low recovery point and recovery time objective, a Hot Standby deployment in another AWS Region may be the best path for you. This deployment however, can be costly.
Pilot Light deployment
Having a Pilot Light deployment in an alternate AWS Region helps you cater for an AWS Region level event. This will reduce your reliance on a single AWS Region (security and data sovereignty must be thought through and explored). However, this has cost implications for hosting a Pilot Light solution ready to go and for having data replicated to that alternate AWS Region.
For this to be a success, you should have your supporting and ancillary infrastructure already running in the target AWS Region and replicating with your primary Region (including full replicas of your Active Directory Domain Controllers, DNS, File shares, patch, and application deployment servers). There will obviously be some cost associated with having these running, however they will be a necessary piece of the failover.
For a Pilot Light deployment in WorkSpaces, we suggest that you deploy the WorkSpaces as you are executing the DR procedure (hence the Pilot Light bit). The important piece to understand (and test in your environment before you do a live DR) is that a deployment will take some time. API limits may come into play here depending how many and how fast you are deploying the WorkSpaces. Most of the time taken will be for each WorkSpace that’s launched to be joined to your Active Directory, apply group policies, download patches, and applications etc.
Once the WorkSpaces instances have completed their launch process and are available, your Users must change the Registration Code in the WorkSpaces client to point to the new AWS Region and AWS Directory Service.
Check out a recent blog post from one of my colleagues on orchestrating a Pilot Light WorkSpaces solution in a different AWS Region: Building a multi-region disaster recovery environment for Amazon WorkSpaces
Hot Standby deployment
Another option you have in your tool-belt is a Hot Standby deployment of WorkSpaces. This concept builds on the Pilot Light deployment. The difference is you have pre-launched your WorkSpaces fleet, so that they are ready to go at a moment’s notice.
Once you execute your DR, your Users must change the Registration Code in the WorkSpaces client to point to the new AWS Region and AWS Directory Service.
Having a complete WorkSpaces deployment in another AWS Region could be costly, however given we have AutoStop instances (you pay for the WorkSpace instance by the hour), costs are minimized as much as they can be, but then they are also ready rapidly when you need them.
WorkSpaces Client Cross-Region Redirection
When your users need to switch between Regions for their WorkSpaces (for either Pilot Light or Hot Standby deployments), they traditionally would have to change the Registration Code in the WorkSpaces Client to point that client to a different Region and Directory Service to authenticate against.
With the Cross-Region Redirection feature in the WorkSpaces Client, users are able to consume a fully qualified domain name (FQDN) and domain name system (DNS) record which can be updated to point to the fail-over Region.
You can either (administratively) update the DNS record manually (suitable for Pilot Light Deployment) or using automated DNS failover to automatically switch the Regions for the user in the WorkSpaces Client (good option for a Hot Standby deployment).
An example of an automated DNS failover could include Amazon Route53 and Amazon CloudWatch Alarms to monitor the health of your Active Directory infrastructure to then invoke the DNS failover in the event your Active Directory becomes unhealthy. Depending the failure scenario you are building for, you could look at a cross region monitoring capability that triggers the DNS failover in the event the primary region becomes unresponsive to health checks.
More information on configuring the Cross-Region Redirection capability can be found here.
Validating DR and BCP Plans for your deployment
While it is not possible to simulate an Availability Zone level event, you can test and prove your recovery strategy. For a Single Region DR scenario, this could be as simple as performing a WorkSpaces Rebuild action across one or more of your WorkSpaces instances. This will launch a new underlying instance with the user volume from the latest Snapshot from S3 (up to 12 hours old), and a system volume from the original bundle image.
You will be able to validate the Availability Zone that the WorkSpace instance launched into by reviewing the private IP address assigned to the WorkSpace instance and correlating that back to your Subnet Availability Zone deployment and mapping.
This test will also help you validate and stress test any other overlay functions or services that you leverage for your User environment such as Roaming Profiles, File Synchronization capabilities, patch and application deployment technologies.
Wrap up
I hope this post has helped explain how Amazon WorkSpaces is architected out of the box in a multi-availability zone deployment and has given you some additional insights and thoughts to take it even further along with helping you test your readiness for recovery.
If you would like to explore different design scenarios or need help with setting up a DR and BCP test plan for you and your business, please reach out to your AWS account team.
I would love to hear your thoughts on this blog post, how you have done DR and BCP in your WorkSpaces deployment. Please feel free to reach out with any feedback or lessons learned. I add it into strategies for dealing with these design patterns in future.
About the Author
Phil Persson is a Specialized Solutions Architect for End User Computing. Phil has been with AWS since December 2012 where he was a founding member of AWS Premium Support in the Sydney Region and then a Technical Account Manager for AWS Enterprise Support.
