AWS HPC Blog
Running cost-effective GROMACS simulations using Amazon EC2 Spot Instances with AWS ParallelCluster
This post was contributed by Santhan Pamulapati, Solutions Architect, and Sean Smith, Sr. Solutions Architect at AWS.
GROMACS is a popular open-source software package designed for simulations of proteins, lipids, and nucleic acids. To effectively perform the simulations, users may require access to high-performance computing (HPC) environment. AWS provides such HPC environment through AWS ParallelCluster and in the previous workshops, we’ve shown examples of running GROMACS simulations using AWS ParallelCluster.
By using Amazon EC2 Spot Instances for simulations, you can cost-effectively run GROMACS simulations and save up to 90% off the on-demand price. The trade off with Spot Instances is that they can be interrupted at any time with a 2-minute warning.
Depending on simulation complexity, the run time can be for hours or even multiple days. As simulation run time grows, their interruption risk potentially increases. Therefore, it becomes critical to preserve the progress of the simulation as it completes. Simulation checkpointing is a way to achieve this. By combining GROMACS native checkpointing with Spot instances, you can resume simulations and lose minimal progress if you experience an interruption. Spot instances offer an alternative scaling solution to an accelerated graphics processing unit (GPU) approach.
Solution Overview
In this post, we demonstrate that by combining GROMACS checkpointing with Spot pricing and scheduling with Slurm, we architected a cost-effective solution for running GROMACS simulations. We built the solution with GROMACS installed on AWS ParallelCluster.
Prerequisites
The following pre-requisites are recommended:
- AWS account with appropriate user privileges in a test environment
- Familiarity with AWS ParallelCluster deployment as outlined in the AWS HPC workshop
- Familiarity with running GROMACS simulations in a Linux environment
Solution Walkthrough
In this section, we show an example setup to get started with GROMACS with checkpointing and Spot Instances. This solution works for single-node and multi-node instance runs. The sample setup involves following steps:
Create and deploy AWS ParallelCluster with Spot instances
AWS ParallelCluster orchestrates and manages HPC clusters in the AWS Cloud. In this post, a Slurm based cluster is deployed using AWS ParallelCluster with one head node and multiple Spot Instance worker nodes. To create and deploy AWS ParallelCluster with Spot instances, refer to AWS ParallelCluster Documentation. An example template with SPOT capacity type is following.
Region: us-east-2
Image:
Os: alinux2
HeadNode:
InstanceType: c6i.xlarge
Networking:
SubnetId: subnet-0xxxxxxxxxxxxxx77
Ssh:
KeyName: key_name
Dcv:
Enabled: true
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: compute
Networking:
SubnetIds:
- subnet-0xxxxxxxxxxxxxxe0
CapacityType: SPOT
ComputeResources:
- Name: spot
InstanceType: c6i.32xlarge
MinCount: 0
MaxCount: 10
Efa:
Enabled: true
GdrSupport: false
SharedStorage:
- Name: FsxLustre
StorageType: FsxLustre
MountDir: /shared
FsxLustreSettings:
StorageCapacity: '1200'
DeploymentType: PERSISTENT_1
PerUnitStorageThroughput: '200'
Install Spack on your cluster
After creating the cluster, you can use Spack, a package manager for HPC, to install GROMACS. A cluster can share a single Spack installation with all members by installing software in shared storage. In our AWS ParallelCluster configuration, we selected Amazon FSx for Lustre as shared storage with a /shared mount point. Run the following commands on the head node to install Spack in the shared filesystem (/shared):
export SPACK_ROOT=/shared/spack
mkdir -p $SPACK_ROOT
git clone -c feature.manyFiles=true https://github.com/spack/spack
echo "export SPACK_ROOT=$SPACK_ROOT" >> $HOME/.bashrc
echo "source \$SPACK_ROOT/share/spack/setup-env.sh" >> $HOME/.bashrc
source $HOME/.bashrc
To preserve data across multiple clusters, link your filesystem to an Amazon Simple Storage Service (Amazon S3) bucket and setup a data repository task in FSx for Lustre. Linking a filesystem to Amazon S3 allows you to manage the transfer of data and metadata between FSx for Lustre and Amazon S3. This allows you to delete your FSx for Lustre filesystem between runs and can be a cost-effective option if running short-term clusters with long-wait times between runs.
Install GROMACS on your cluster
Refer to the Installing GROMACS with Spack workshop. Spack builds the binaries from source code and targets the build for a specific architecture. You can let Spack automatically detect the architecture or manually specify parameters to define the build. (You may take on additional dependencies if you manually define the build.) For this blog, we will build the binary with Spack automatically detecting the architecture on the instance family used in our cluster.
Configure GROMACS to handle Spot instance interruptions
Amazon EC2 Spot Instances can be reclaimed with simulations interrupted. Ideally users would like to continue the simulation from the point of interruption instead of restarting a new run. To minimize any lost work during an interruption, use checkpointing with GROMACS to save your simulation state as your simulation runs. Once saved, replace interrupted instances and resubmit your Slurm job to finish your simulation.
GROMACS supports checkpointing simulations at a user-defined interval. We configured checkpointing with command-line flags for Mdrun, the main computational chemistry engine in GROMACS. The following table explains our selected flags.
| Flag and value | Explanation |
|---|---|
- cpt 1 |
User defined checkpoint interval in minutes |
- cpi spot-cpu.cpt |
User defined file for reading the preserved state |
- cpo spot-cpu-output.cpt |
User defined file for writing the state |
The cpt flag turns on checkpointing and saves data needed to continue the GROMACS simulation in the event of node interruption. If an instance is interrupted, AWS ParallelCluster automatically deploys a new instance and requeues the Slurm job to the new instance.
The default checkpointing time is every 15 minutes. In our testing with a GROMACS simulation of 82,000 atoms with 500,000 steps for 1ns time, we found that enabling checkpoint every minute adds a negligible overhead of 5-7 seconds (less than 1% overhead) to the total simulation time.
We used a Slurm job submission script to run a benchmark simulation, and for details on running the simulation, see the GROMACS workshop. The following script is an example of setting up a GROMACS Mdrun job with checkpointing options described in the previous table. This script is saved on the cluster’s head node to a spot.sbatch file.
#!/bin/bash
#SBATCH --job-name=spot-gromacs-demo
#SBATCH --exclusive
#SBATCH --output=/shared/logs/%x_%j.out
#SBATCH --partition=spot
NTOMP=2
mkdir -p /shared/jobs/${SLURM_JOBID}
cd /shared/jobs/${SLURM_JOBID}
echo ">>> loading gromacs module "
spack load gromacs
module load intelmpi
set -x
mpirun gmx mdrun -nsteps 500000 -pme cpu -ntomp ${NTOMP} -s /shared/input/gromacs/benchMEM.tpr -resethway -cpt 1 -cpi spot-cpu-${SLURM_JOBID}.cpt -cpo spot-cpu-${SLURM_JOBID}.cpt -e spot-cpu-${SLURM_JOBID}.edr -g spot-cpu-${SLURM_JOBID}.log
To use multiple compute nodes, submit the job with sbatch -N [num_of_nodes] spot.sbatch.
Test GROMACS with a Spot interruption
You can simulate a Spot instance interruption to verify your GROMACS configuration and restart behavior. From the head node, submit a job to Slurm using the following sbatch command and wait for it to start running.
$ sbatch spot.sbatchAfter submitting the job, use the squeue command to see the job is initially in configure, “CF” state, and subsequently run, “R” state.

Figure 1 – A terminal session where the squeue command is used to see the job is initially in configure, “CF” state, and subsequently run, “R” state.
After the job enters the running state, simulate a Spot interruption by terminating one or more Spot instances from the AWS Management Console or through AWS Command Line Interface (AWS CLI). Monitor the queue using squeue and see the same job requeued on to a new Spot Instance(s) after interruption.

Figure 2 – A terminal session showing the use of squeue to monitor the job queue and showing the same job requeued on to new Spot Instances after interruption.
Optional: Verifying Spot Interruption Behavior
AWS ParallelCluster exports system logs to Amazon CloudWatch Logs. You can find these log messages in slurmctld file within the AWS ParallelCluster log group in the CloudWatch Logs console or in cluster at /var/log/parallelcluster/slurmctld.
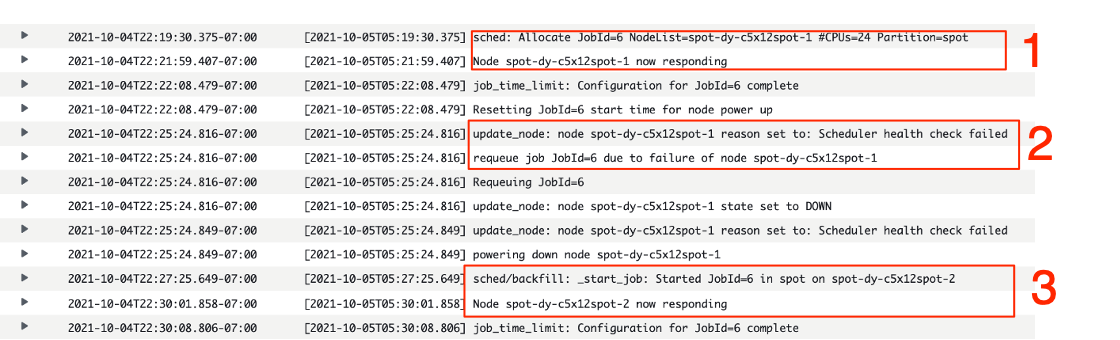
Figure 3 – A view of the ParallelCluster log entries showing the reported Slurm activity for launching Spot Instances (1), starting jobs (2), and requeuing of jobs that were interrupted (3).
The screenshot shows the following Slurm activity in the log group:
- Launching a Spot instance and starting a job
- Marking an instance as unhealthy after a failed scheduler health check
- Requeuing the job on a new instance due to node failure
Finally, confirm the job successfully completed from the checkpoint by examining the job logs stored on the head node. The log messages should indicate that the simulation is continued from the preserved state.
Cleanup
To clean up the ParallelCluster environment you have created, run the following command.
pcluster delete-cluster --cluster-name <name of the cluster>The cluster and all its resources will be deleted by CloudFormation. You can check the status in the CloudFormation dashboard.
Conclusion
In this blog, we demonstrated that by using Amazon EC2 Spot Instances, AWS ParallelCluster, and GROMACS checkpointing, users can reduce their simulations costs up to 90% with Spot instances and reduce the impact of Spot interruptions. The checkpointing method can also be used with On-Demand Instances. Although this blog focused on GROMACS, the same approach applies to other application that support checkpointing and restarting from a checkpoint.
You can get started by deploying this solution in to your AWS environment to realize the benefits of running GROMACS simulations with EC2 Spot Instances. We also encourage you to look at our HPC solutions using ParallelCluster listed in the AWS HPC blogs.