AWS for Industries
Process, Search, and Analyze Electronic Lab Notebooks Data on AWS
Retrieving, processing, and analyzing electronic lab notebook (ELN) data is slow, costly, and labor intensive. AWS storage, databases, and artificial intelligence/machine learning services can significantly enhance knowledge retrieval speed, unlock unstructured ELN assets, facilitate building knowledge graphs, and form scalable and cost-effective processing pipelines.
Introduction
ELN is computer software heavily used in research settings (especially in highly regulated industries such as pharmaceuticals) by scientists, engineers, and technicians to record research experiments, protocols, and notes. It is not only a replacement of traditional paper notebooks, but also offers a variety of features to enhance a user’s experience, productivity, and knowledge management by facilitating collaboration, data management, access controls, security, audits, and backups. ELN software typically allow the user to attach files (such as assay run results) to their experiments.
To reduce timelines and costs of new therapeutics, pharmaceutical companies are quickly moving toward unified knowledge management to enhance knowledge retrieval, enable machine learning applications on top of the consolidated knowledge, and facilitate end-to-end view from research to the production of products. In this paradigm shift, ELNs quickly become a bottleneck:
- Search functionality in most ELN software is limited
- Large amounts of information and insights are locked inside the attachments
- Attachments (such as pdf, excel files) are often not searchable/queryable which makes it difficult to find and retrieve information.
- ELNs contain valuable scientific results (such as assay runs)
- Extracting results for downstream analysis or machine learning applications requires costly manual effort and is error-prone.
- Significant portion of ELN data is unstructured or semi-structured
- Currently, there is no automated way to leverage that data to enrich drug discovery knowledge.
- Search beyond simple keywords is typically not possible in ELN software
- For example, a question such as “What is the distribution of aggregation temperature for a given protein in the past three years?” requires significant amounts of manual work.
- Pharmaceutical companies actively maintain multiple data sources capturing information from research to production (including ELN)
- Data sources are often siloed—making it difficult to answer complex questions across these data sources.
Amazon Web Services (AWS) storage, artificial intelligence/machine learning (AI/ML), analytics, and database services can address the challenges outlined above to increase efficiency, reduce costs, and enhance knowledge management, processing, and retrieval. In Figure 1, we provide a generic architecture comprised of some of the key services for building an ELN processing solution on AWS. Depending on the business needs and use cases, a solution can be created by customizing and enhancing this architecture.
Reference Architecture

Figure 1: ELN processing reference architecture on AWS comprised of Data Load, Data Processing, and Data Store
The architecture assumes that ELN assets are stored in an Amazon Simple Storage Service (Amazon S3) bucket and/or in relational databases. Amazon S3 is an object storage service offering industry-leading scalability, data availability, security, and performance. Customers of all sizes and industries can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps.
Typically, the ELN data consists of structured metadata and attachments. In some metadata fields, scientist can enter experiment details as free text. Attachments are files (typically PDF, Excel, CSV, and PowerPoint) either manually created or automatically generated by lab equipment. We’ll focus on unstructured text data, either those free text fields in ELN metadata (assuming those are saved as text files) or the attachments. In comparison to unstructured data, structured data mostly requires minimal processing.
The architecture can be divided into three main sections:
- Data Load
- Data Processing
- Data Store
Data Load:
In the data load section an AWS Lambda (Lambda) function is triggered once an ELN file is detected in the Amazon S3 bucket (Figure 1, area 1). Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. The file metadata is stored in a Amazon DynamoDB (DynamoDB) table for tracking purposes and also sent to a queue using Amazon Simple Queue Service (Amazon SQS) for processing.
DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools.
Amazon SQS is a fully managed message queuing for microservices, distributed systems, and serverless applications that lets you send, store, and receive messages between software components at any volume.
Furthermore, structured data associated with the ELN is ingested in another Amazon S3 bucket (Figure 1, area 2) by using one or more AWS Glue job. AWS Glue is a serverless data integration service that makes it straightforward to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning, and application development. The AWS Glue jobs can be scheduled to run periodically using an AWS Step Functions (Step Functions). Step Functions is a visual workflow service that helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and ML pipelines.
Data Processing:
Depending on the file type and the end goal, the data processing section consists of a selection of AI/ML services such as Amazon Textract, Amazon Comprehend, and Amazon SageMaker (SageMaker) extract information that is valuable in answering scientific and business questions.
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents. It goes beyond optical character recognition (OCR) to identify, understand, and extract data from forms and tables. For attachment files such as PDF and images (JPG, PNG), Amazon Textract is the first step to extract raw text, forms, and tables. Tables are converted to CSV (or other desired formats) and persisted in Amazon S3 for potential downstream analysis. The raw text extracted by Amazon Textract is now ready for natural language processing (NLP) and machine learning. Similarly tables and raw texts extracted by using Amazon Textract can be persisted in Amazon S3 as plain text files.
Extracted artifacts out of Amazon Textract can be used by Amazon Comprehend, which uses NLP to extract insights about the content of documents without the need of any special preprocessing. Amazon Comprehend processes any text files in UTF-8 format. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
For ELN processing, Amazon Comprehend is leveraged to extract entities, and key phrases. Custom entity recognition extends preset generic entities by identifying specific new entity types if the right training data is available. For example, if lot number is an entity of interest, Amazon Comprehend’s custom entity recognition is leveraged to train an accurate NLP models specific to that entity.
One common challenge in ELN data asset management is categorizing the attachments. In most cases, without manually inspecting the file, it is hard or impossible to know the type of document. Some examples of document types are assay runs, validation protocols, and Standard Operating Procedures (SOPs). In some cases, even the category of an ELN itself cannot be determined automatically if the users fail to populate the associated metadata in ELN properly.
Amazon Comprehend has two features which are useful for this challenge. First, you can use Amazon Comprehend to examine the content of a collection of documents to determine common themes. For example, you can give Amazon Comprehend a collection of attachments, and it will determine the subjects. The text in the documents doesn’t need to be annotated. This is called Topic Modelling.
Second, Amazon Comprehend’s custom classification can create custom classification models (classifiers) to organize your documents into your own categories. For each classification label, provide a set of documents that best represent that label and train your classifier on it. Once trained, a classifier can be used on any number of unlabeled document sets.
To leverage complex, custom AI/ML models, SageMaker provides a fully managed machine learning service. With SageMaker, data scientists and developers can quickly build and train machine learning models, and then directly deploy them into a production-ready hosted environment.
In cases where a custom NLP model is needed, data scientists can leverage SageMaker to build custom models, such as a custom document classifier, document similarity model, or a regularity risk assessment model. Once trained, the model can be deployed to an endpoint that can be used for near real-time inference. If near real-time inference is not needed, then the inference can be made either by batch transform or serverless inference.
Data Store:
Once the processing step is done, an enriched set of attributes such as detected entities, key phrases, and document types are available. This information can be stored by itself or along with the raw text data in a variety of ways depending on the use case. Below we describe some of the major types of data stores for ELN assets.
Typically, all the raw text data, such as extracted text, tables and forms are stored in Amazon S3. This data might be useful for additional processing, auditing, or downstream analysis in other applications.
DynamoDB can be leveraged to store processing status of the documents, extracted entities, and ML results (such as predicted document type). Other applications (such as dashboards) can use DynamoDB tables to query and extract results.
Amazon OpenSearch Service (OpenSearch Service) is a managed service that makes it straightforward to deploy, operate, and scale OpenSearch Clusters in the AWS Cloud. OpenSearch Service is an open source, distributed search and analytics suite derived from Elasticsearch with visualization capabilities such as OpenSearch Service Dashboards and Kibana. A common pattern in ELN processing is to index the raw text extracted from the files along with extracted attributes (such as metadata) into the OpenSearch Service clusters. This makes all the unstructured assets searchable and queryable.
OpenSearch Service supports key word search, OpenSearch SQL, and OpenSearch Piped Processing Language (PPL), a query language that lets you use pipe syntax, to explore, discover, and query your data. These features facilitate complex search as a standalone service and/or integration with other application and services such as Amazon Neptune (Neptune).
Neptune is a fast, reliable, fully managed graph database service that makes it straightforward to build and run applications that work with highly connected datasets. The core of Neptune is a purpose-built, high-performance graph database engine. This engine is optimized for storing billions of relationships and querying the graph with milliseconds latency.
Neptune supports popular graph query languages such as Apache TinkerPop’s Gremlin, the W3C’s SPARQL, and Neo4j’s openCypher, enabling users to build queries that efficiently navigate highly connected datasets. A foundation to build a graph network based on the processed data from the respective source systems sets the stage for a custom ontology. This is defined based on the rules set by the organization that forms the relationship between the processed ELN data to a given batch/sample.
Prior to building the ontology, the business organization needs to decide on the type of graph format to support, as it is not trivial to change the graph format midway through accumulating the graph format data. The two graph formats to consider are Labeled Property Graph (LPG) and Resource Description Framework (RDF). Furthermore, using Amazon Comprehend and SageMaker allows organizations to enrich the ELN with metadata based on entities and metadata that supports a growing custom ontology.
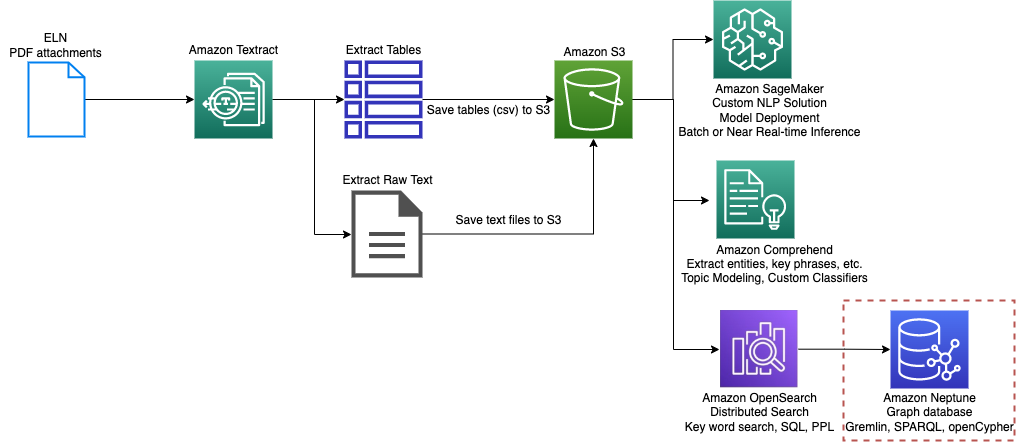
Figure 2: An example of an ELN processing pipeline on a PDF attachment
Figure 2 presents an example of processing a PDF file. Here we assume the PDF file is an ELN attachment that is stored in Amazon S3. Amazon Textract processes the PDF and stores raw text and tables in an S3 bucket. For processing, SageMaker is used to create custom NLP models; Amazon Comprehend extracts entities (including custom ones) and key phrases, and classifies the documents.

Figure 3: A schematic of a knowledge graph
The results are searchable and can be queried by Amazon OpenSearch Service. In addition, the extracted entities are indexed in a Neptune cluster, which populates corresponding nodes and edges. Figure 3 shows a schematic of a knowledge graph with four node types (project, batch, experiment, and parameter). This knowledge graph now supports cross data complex queries. To learn more about knowledge graphs, refer to Knowledge Graphs on AWS.
Cleanup
In the Data Load section, we assumed the data is already stored in Amazon S3. In reality, an extract, transform, and load (ETL) pipeline is needed to extract and load data from the ELN software backend database to Amazon S3. This pipeline depends on the type of database the ELN software uses. For an example of migrating an Oracle database to Amazon S3, please refer to Migrate Oracle databases to or within AWS using Amazon S3 integration with Oracle RMAN.
Conclusion
ELN is a medium for capturing business and scientific critical data. Despite vast benefits over traditional paper notebooks, they pose challenges when it comes to data modernization, knowledge management, and enabling machine learning applications.
The services described above work together to create a custom solution addressing the current challenges in ELN data processing and information retrieval. Benefits of such a solution are:
- Speed of information retrieval is significantly increased
- The ELN assets, including attachments such as PDF files become searchable and queryable by Amazon OpenSearch Service.
- Multiple query languages, advanced search functionality, and visualization capabilities are available out-of-the-box.
- Data is stored in desired formats
- Tabular data containing scientific critical results such as assay runs are stored individually as flat files on Amazon S3 enabling any type of downstream analysis.
- Unstructured and semi-structured data assets are unlocked
- Business and scientific critical attributes (including custom attributes) are extracted out of unstructured and semi-structured assets and stored as metadata in OpenSearch Service, properties on Neptune, and/or key/value pairs in DynamoDB.
- Integrating ELN into knowledge graphs is facilitated
- The enriched knowledge extracted from structured and unstructured ELN assets make it possible to integrate ELN into knowledge graphs.
- Knowledge graphs enable complex search spanning multiple data sources formed on the basis of defined relationships.
- Solution is scalable and cost effective
- A solution built based on the presented architecture is scalable (to millions of documents), cost effective (pay for what you use), and fast (multiple orders of magnitude over manual processing).
ELN processing presented here is an example of Intelligent Document Processing. Please refer to Intelligent document processing with AWS AI services: Part 1 for more information on leveraging AWS services to build an intelligent document processing solution.
In the context of a Lab of the Future, which is trending especially in pharmaceutical companies, automated ELN processing can increase efficiency and reducing cost.
To learn more about AWS solutions for building knowledge graphs please refer to Accelerating drug discovery through knowledge graph and Building a knowledge graph in Amazon Neptune using Amazon Comprehend Events.
To know what AWS can do for you contact an AWS Representative.