Artificial Intelligence
Running BigDL, Deep Learning for Apache Spark, on AWS
In recent years, deep learning has significantly improved several AI applications, such as recommendation engines, voice and speech recognition, and image and video recognition. Many customers process the massive amounts of data that feed these deep neural networks in Apache Spark, only to later feed it into a separate infrastructure to train models using popular frameworks, such as Apache MXNet and TensorFlow. Because of the popularity of Apache Spark and contributors that exceed a thousand, the developer community has expressed interest in uniting the big data infrastructure and deep learning into a single workflow under Apache Spark.
Apache Spark is an open-source cluster-computing framework. Originally developed at the University of California, Berkeley‘s AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which maintains it. Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
BigDL is a distributed deep learning framework for Apache Spark that was developed by Intel and contributed to the open source community for the purposes of uniting big data processing and deep learning. BigDL helps make deep learning more accessible to the big data community by allowing developers to continue using familiar tools and infrastructure to build deep learning applications. BigDL is licensed under the Apache 2.0 license.
As the following diagram shows, BigDL is implemented as a library on top of Spark, so that users can write their deep learning applications as standard Spark programs. As a result, BigDL can be seamlessly integrated with other libraries on top of Spark—Spark SQL and DataFrames, Spark ML pipelines, Spark Streaming, Structured Streaming, etc.—and can run directly on top of existing Spark or Hadoop clusters.
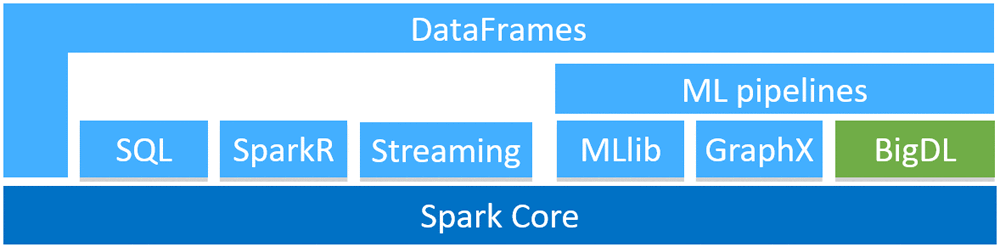
Highlights of the BigDL v0.1.0 release
Since its initial open source release in December 2016, BigDL has been used to build applications for fraud detection, recommender systems, image recognition, and many other purposes . The recent BigDL v0.1.0 release addresses many user requests, with a strong focus on ease of use:
- Python support. Python support is one of the most requested features by the BigDL user community. BigDL v0.1.0 provides full support for Python APIs (built on top of PySpark). As a result, you can use deep learning models in BigDL with existing Python libraries (e.g., NumPy and pandas), which automatically run in a distributed fashion to process large volumes of data on Spark.
- Notebook integration. With full Python API support in BigDL v0.1.0, data scientists and analysts can now explore their data using powerful notebooks (such as Jupyter notebooks) in a distributed fashion across the cluster. Notebooks combine Python libraries, Spark SQL and DataFrames, MLlib, deep learning models in BigDL, and interactive visualization tools.
- TensorBoard support. TensorBoard is a suite of visualization tools from Google that allows you to visualize deep learning programs. BigDL v0.1.0 provides TensorBoard support, so that you can use it to visualize and understand the behavior of BigDL programs.
- Better RNN support. Recurrent neural networks (RNNs) are important technologies for text analysis, natural language processing, time series analysis, etc. BigDL v0.1.0 provides better RNN support, including faster implementations and more algorithmic support (e.g., long short term memory, gated recurrent unit, etc.).
- Improved robustness. BigDL is built on top of Spark, and benefits from automatic fault tolerance in the Spark framework. BigDL v0.1.0 provides several additional improvements to increase robustness, such as eliminating the dreaded Detect multi-task run error and automatic recovery from previous snapshots.
Tutorial: Running BigDL v0.1.0 on AWS
In the rest of this post, we demonstrate how you can run BigDL using its Python API (together with a Jupyter notebook and TensorBoard) for distributed interactive data explorations and visualizations on AWS.
Deploy BigDL on AWS
To install BigDL on Amazon EMR, you can use the following bootstrap action with the –bigdl argument in an AWS CLI command or in the AWS EMR console:
For details on using this bootstrap action, see this blog post.
To use the AWS CLI to launch the EMR cluster, use the following commands:
After the EMR cluster is ready and the SSH tunnel and web proxy are set up, you should be able to access Jupyter at http://localhost:8880. As specified in the preceding CLI command, the password is jupyter. TensorBoard should be available at http://localhost:6006.
Classify text using BigDL
In this tutorial, we demonstrate how to solve a text classification problem based on the example found here. This example uses a convolutional neural network to classify posts in the 20 Newsgroup dataset into 20 categories.
We’ve provided a companion Jupyter notebook example on GitHub that you can open in the Jupyter dashboard to execute the code sections.
In the notebook, initialize the BigDL engine as follows:

Load the dataset (and the pre-trained GloVe word embeddings) using the helper functions provided in BigDL, which automatically download the data and parse it into lists:

After the data is loaded, you can visualize the text for the posts, for instance as a word cloud:


Transform text data to resilient distributed datasets
To analyze the text data using BigDL on Spark in a distributed fashion, transform it into resilient distributed datasets (RDDs) by using a series of RDD transformations written in PySpark:


Train a convolutional neural network
In machine learning, a convolutional neural network (CNN or ConvNet) is a type of feed-forward artificial neural network in which the connectivity pattern between its neurons is inspired by the organization of the animal visual cortex. You can apply CNNs to a variety of domains, including image and video recognition and speech recognition.
Build the convolutional neural network model:

Create the optimizer and train the model with the following code. The code specifies that the optimizer should output summary information to /tmp/bigdl_summaries. After training starts, you can read the summary to visualize the training process either in TensorBoard or in the notebook itself.

Evaluate the prediction results
After training is complete, you can use the trained model to make the predictions on val_rdd. To evaluate the prediction result, use two metrics: accuracy and a confusion matrix. A confusion matrix is a table that allows you to visualize the performance of a supervised learning algorithm. Each column represents the instances in a predicted class and each row represents the instances in an actual class (or vice versa). A confusion matrix makes it easy to see if the system is confusing two classes (i.e., commonly mislabeling one as another). In the following confusion matrix, the diagonal line of darker numbers indicates correct predictions. All others are incorrect.


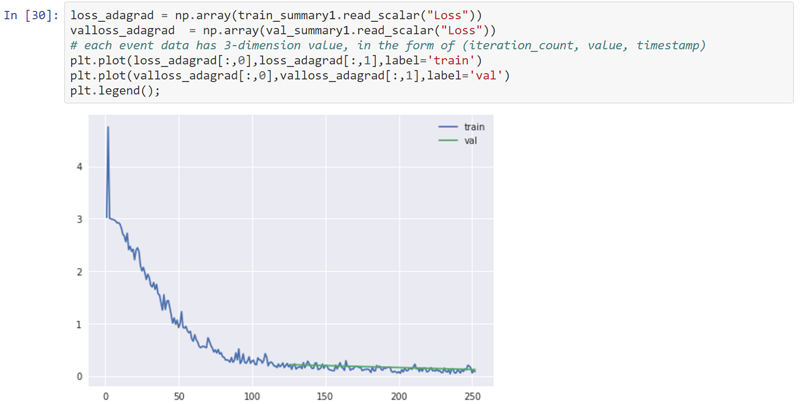
In addition, you can view metrics within the summary information generated by the optimizer in BigDL, and then visualize the metrics using inline plotting libraries, such as Matplotlib, in the notebook. For example, the following chart illustrates the training and validation loss, where lower is better:
Visualize the training with TensorBoard
TensorBoard is a suite of web applications for inspecting and understanding your deep learning program runs and graphs. You can also use TensorBoard during BigDL training to visualize the behavior of the BigDL program. For more details, see the BigDL Home page on GitHub.
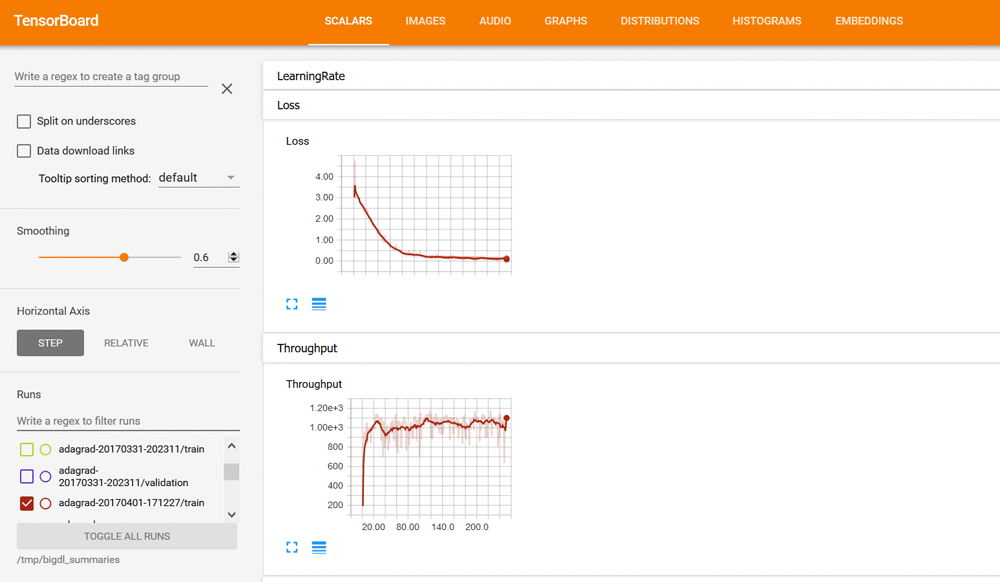
Use a browser to navigate to the TensorBoard dashboard at http://localhost:6006. In the dashboard, on the SCALARS tab, you can review the visualizations of each run, including the Loss and Throughput curves:
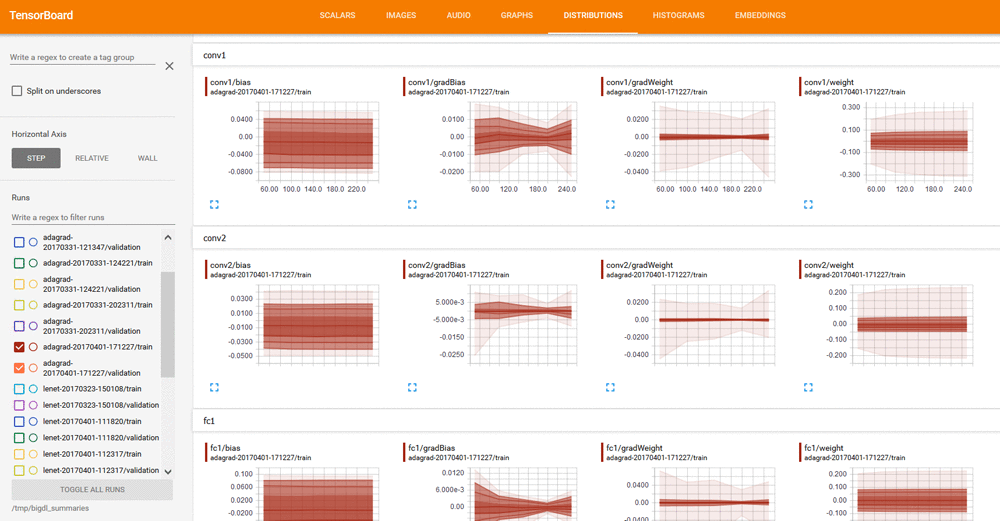
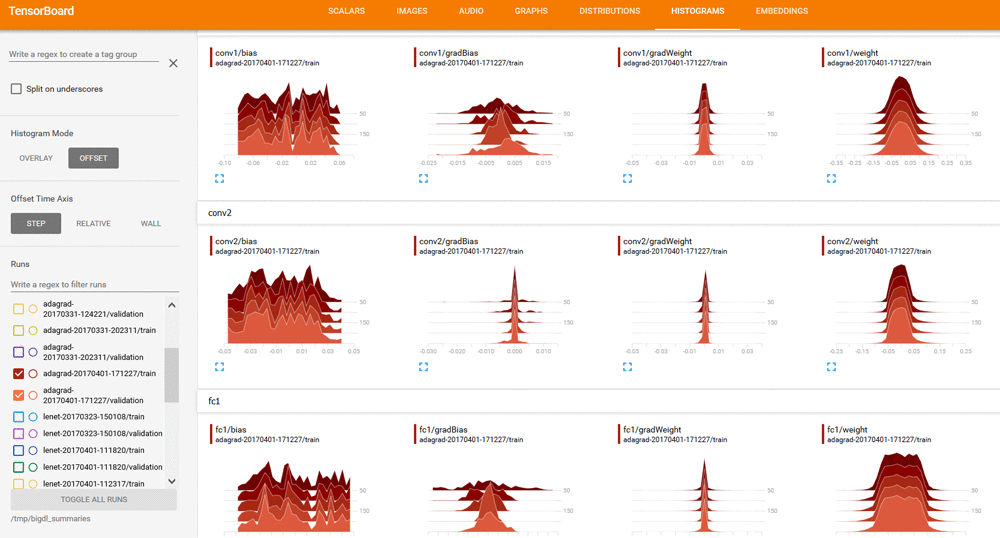
On the DISTRIBUTIONS and HISTOGRAMS tabs, you can review visualization for weights, bias, gradientWeights, and gradientBias:
Summary
In this post, we demonstrated how you can use familiar tools, such as Spark, and BigDL v0.1.0, to easily build deep learning applications in a distributed fashion on AWS. BigDL v0.1.0 includes support for Python, Jupyter notebooks, TensorBoard, etc. To get started with BigDL on AWS, try out the companion notebook. To learn more about the BigDL project, see the BigDL GitHub page. If you have questions or suggestions, please comment below.
About the Authors
Joseph Spisak leads Deep Learning Product Management in AmazonAI
Tom Zeng is a Solutions Architect for Amazon EMR
Jason Dai is a Senior Principal Engineer and Chief Architect, Big Data Technologies for Intel
Radhika Rangarajan is an Engineering Engagement Director, Big Data Technologies for Intel