Artificial Intelligence
Tag: distributed training

Train CodeFu-7B with veRL and Ray on Amazon SageMaker Training jobs
In this post, we demonstrate how to train CodeFu-7B, a specialized 7-billion parameter model for competitive programming, using Group Relative Policy Optimization (GRPO) with veRL, a flexible and efficient training library for large language models (LLMs) that enables straightforward extension of diverse RL algorithms and seamless integration with existing LLM infrastructure, within a distributed Ray cluster managed by SageMaker training jobs. We walk through the complete implementation, covering data preparation, distributed training setup, and comprehensive observability, showcasing how this unified approach delivers both computational scale and developer experience for sophisticated RL training workloads.

Scale LLM fine-tuning with Hugging Face and Amazon SageMaker AI
In this post, we show how this integrated approach transforms enterprise LLM fine-tuning from a complex, resource-intensive challenge into a streamlined, scalable solution for achieving better model performance in domain-specific applications.
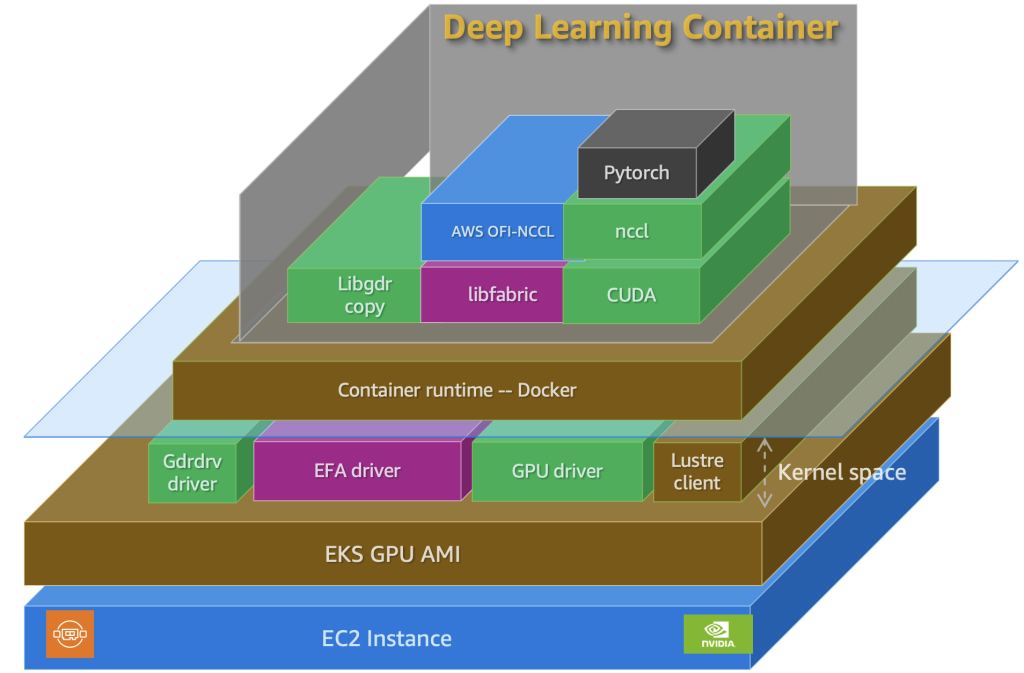
Configure and verify a distributed training cluster with AWS Deep Learning Containers on Amazon EKS
Misconfiguration issues in distributed training with Amazon EKS can be prevented following a systematic approach to launch required components and verify their proper configuration. This post walks through the steps to set up and verify an EKS cluster for training large models using DLCs.

Fraud detection empowered by federated learning with the Flower framework on Amazon SageMaker AI
In this post, we explore how SageMaker and federated learning help financial institutions build scalable, privacy-first fraud detection systems.

Accelerate pre-training of Mistral’s Mathstral model with highly resilient clusters on Amazon SageMaker HyperPod
In this post, we present to you an in-depth guide to starting a continual pre-training job using PyTorch Fully Sharded Data Parallel (FSDP) for Mistral AI’s Mathstral model with SageMaker HyperPod.
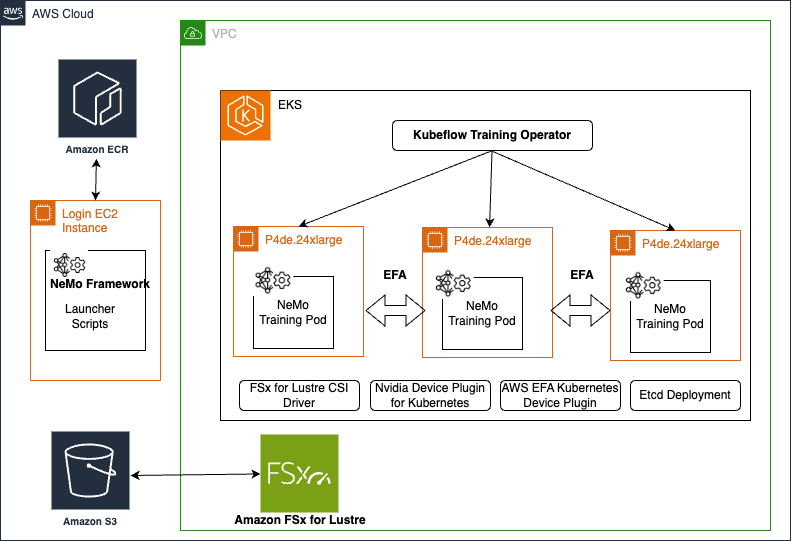
Accelerate your generative AI distributed training workloads with the NVIDIA NeMo Framework on Amazon EKS
In today’s rapidly evolving landscape of artificial intelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Without a structured framework, the process can become prohibitively time-consuming, costly, and complex. Enterprises struggle with managing […]

End-to-end LLM training on instance clusters with over 100 nodes using AWS Trainium
In this post, we show you how to accelerate the full pre-training of LLM models by scaling up to 128 trn1.32xlarge nodes, using a Llama 2-7B model as an example. We share best practices for training LLMs on AWS Trainium, scaling the training on a cluster with over 100 nodes, improving efficiency of recovery from system and hardware failures, improving training stability, and achieving convergence.

Amazon SageMaker model parallel library now accelerates PyTorch FSDP workloads by up to 20%
Large language model (LLM) training has surged in popularity over the last year with the release of several popular models such as Llama 2, Falcon, and Mistral. Customers are now pre-training and fine-tuning LLMs ranging from 1 billion to over 175 billion parameters to optimize model performance for applications across industries, from healthcare to finance […]

Fast and cost-effective LLaMA 2 fine-tuning with AWS Trainium
Large language models (LLMs) have captured the imagination and attention of developers, scientists, technologists, entrepreneurs, and executives across several industries. These models can be used for question answering, summarization, translation, and more in applications such as conversational agents for customer support, content creation for marketing, and coding assistants. Recently, Meta released Llama 2 for both […]

Scaling Large Language Model (LLM) training with Amazon EC2 Trn1 UltraClusters
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. At the server level, such training workloads demand faster compute and increased memory allocation. As models grow to hundreds of billions of parameters, they require a distributed training mechanism that spans multiple nodes (instances). In October 2022, we launched Amazon EC2 […]