Artificial Intelligence
Best practices for TensorFlow 1.x acceleration training on Amazon SageMaker
Today, a lot of customers are using TensorFlow to train deep learning models for their clickthrough rate in advertising and personalization recommendations in ecommerce. As the behavior of their clients change, they can accumulate large amounts of new data every day. Model iteration is one of a data scientist’s daily jobs, but they face the problem of taking too long to train on large datasets.
Amazon SageMaker is a fully managed machine learning (ML) platform that could help data scientists focus on models instead of infrastructure, with native support for bring-your-own-algorithms and frameworks such as TensorFlow and PyTorch. SageMaker offers flexible distributed training options that adjust to your specific workflows. Because many data scientists may lack experience in the acceleration training process, in this post we show you the factors that matter for fast deep learning model training and the best practices of acceleration training for TensorFlow 1.x on SageMaker. We also have a sample code of DeepFM distributed training on SageMaker on the GitHub repo.
There are many factors you should consider to maximize CPU/GPU utilization when you run your TensorFlow script on SageMaker, such as infrastructure, type of accelerator, distributed training method, data loading method, mixed precision training, and more.
We discuss best practices in the following areas:
- Accelerate training on a single instance
- Accelerate training on multiple instances
- Data pipelines
- Automatic mixed precision training
Accelerate training on a single instance
When running your TensorFlow script on a single instance, you could choose a computer optimized series such as the Amazon Elastic Compute Cloud (Amazon EC2) C5 series, or an accelerated computing series with multiple GPU in a single instance such as p3.8xlarge, p3.16xlarge, p3dn.24xlarge, and p4d.24xlarge.
In this section, we discuss strategies for multiple CPUs on a single instance, and distributed training with multiple GPUs on a single instance.
Multiple CPUs on a single instance
In this section, we discuss manually setting operators’ parallelism on CPU devices, the tower method, TensorFlow MirroredStrategy, and Horovod.
Manually setting operators’ parallelism on CPU devices
TensorFlow automatically selects the appropriate number of threads to parallelize the operation calculation in the training process. However, you could set the intra_op threads pool and inter_op parallelism settings provided by TensorFlow and use environment variables of MKL-DNN to set binding for the OS thread. See the following code:
The environment variable KMP_AFFINITY of MKL-DNN is set to granularity=fine,compact,1,0 by default. After setting both intra and inter of TensorFlow to the maximum number of vCPUs of the current instance, the upper limit of CPU usage is almost the same as the number of physical cores of the training instance.
If you set os.environ["KMP_AFFINITY"]= "verbose,disabled", the OS thread isn’t bound to the hardware hyper thread, and CPU usage could exceed the number of physical cores.
Regarding the settings of TensorFlow intra parallelism, TensorFlow inter parallelism, and the number of MKL-DNN threads, different combinations of these three parameters result in different training speeds. Therefore, you need to test each case to find the best combination. A common situation is to set the three parameters (intra_op_parallelism_threads and inter_op_parallelism_threads for TensorFlow, os.environ['OMP_NUM_THREADS'] for MKL-DNN) to half the number of vCPUs (physical core) or the total number of vCPUs.
Tower method
To replicate a model over GPUs, each GPU gets its own instance of the forward pass. The instance of the forward pass is called a tower. The tower method is almost always used for GPU devices. To compare training speed with other methods, here we also use the tower method for our CPU device.
If you don’t set the CPU device manually, TensorFlow don’t use the tower method to average the gradients, so you don’t need to scale the batch size in such cases.
- Set the CPU device manually:
- Use
replicate_model_fnto wrapmodel_fn:
- Use
TowerOptimizerto wrapoptimizer:
- Wrap your
model_fn:
- Scale batch size to (NUM_CPU – 1).
Let’s look at the difference of CPU utilization with tower mode enabled. The following figure shows ml.c5.18xlarge instance’s CPU utilization with the following configuration:
No Tower + LibSVM data + pipe mode + MKL-DNN disable binding + TensorFlow intra/inter op parallelism setting to max number of instance’s vCPUs

The following figure shows the ml.c5.18xlarge instance’s CPU utilization with the following configuration:
Tower with set CPU device + LibSVM data + pipe mode + MKL-DNN disable binding + TensorFlow intra/inter op parallelism setting to max number of instance’s vCPUs
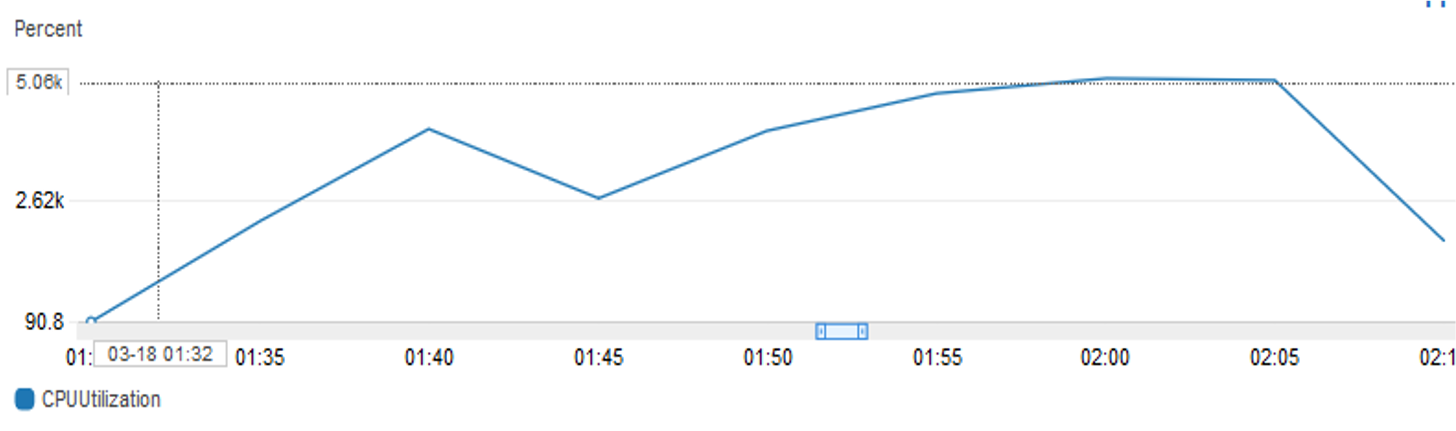
The CPU usage is higher when using the tower method, and it exceeds the number of physical cores.
TensorFlow MirroredStrategy
TensorFlow MirroredStrategy means synchronous training across multiple replicas on one machine. This strategy is typically used for training on one machine with multiple GPUs. To compare training speed with another method, we use MirroredStrategy for our CPU device.
When using TensorFlow MirroredStrategy, if you don’t set the CPU device, TensorFlow just uses one CPU as single worker, which is a waste of resources. We recommend manually setting the CPU device, because it will do a reduce operation on /CPU:0, so the /CPU:0 device isn’t used as a replica here. See the following code:
You need to scale batch size when using MirroredStrategy; for example, scale the batch size to a multiple of the number of GPU devices.
For the sub-strategy when you set CPU device, if you don’t set the cross_device_ops parameter in tf.distribute.MirroredStrategy(), TensorFlow uses the ReductionToOneDevice sub-strategy by default. However, if you set HierarchicalCopyAllReduce as the sub-strategy, TensorFlow just does the reduce work on /CPU:0. When you use the TensorFlow dataset API and distribute strategy together, the dataset object should be returned instead of features and labels in function input_fn.
Usually, TensorFlow MirroredStrategy is slower than the tower method on CPU training, so we don’t recommend using MirroredStrategy on a multi-CPU single host.
Horovod
Horovod is a distributed deep learning training framework for TensorFlow, Keras, PyTorch, and Apache MXNet. The goal of Horovod is to make distributed deep learning fast and easy to use.
There is a parameter of distribution in the SageMaker Python SDK Estimator API, which you could use to state the Horovod distributed training. SageMaker provisions the infrastructure and runs your script with MPI. See the following code:
When choosing a GPU instance such as ml.p3.8xlarge, you need to pin each GPU for every worker:
To speed up model convergence, scale the learning rate by the number of workers according to the Horovod official documentation. However, in real-world projects, you should scale the learning rate to some extent, but not by the number of workers, which results in bad model performance. For example, if the original learning rate is 0.001, we scale the learning rate to 0.0015, even if number of workers is four or more.
Generally, only the primary (Horovod rank 0) saves the checkpoint and model as well as the evaluation operation. You don’t need to scale the batch size when using Horovod. SageMaker offers Pipe mode to stream data from Amazon Simple Storage Service (Amazon S3) into training instances. When you enable Pipe mode, be aware that different workers on the same host need to use different channels to avoid errors. This is because the first worker process reads the FIFO/channel data, and other worker processes on the same instance will hang because they can’t read data from the same FIFO/channel, so Horovod doesn’t work properly. To avoid this issue, set the channels according to the number of workers per instance. At least make sure that different workers on the same host consume different channels; the same channel can be consumed by workers on a different host.
When using Horovod, you may encounter the following error:
The possible cause for this issue is that a certain rank (such as rank 0) works slower or does more jobs than other ranks, and this causes other ranks to wait for a long time. Although rank 0 sometimes has to do more work than other ranks, it should be noted that rank 0 shouldn’t do much for a long time. For example, for the model evaluation on the validation set and saving checkpoints during training, if it’s inevitable that these operations will take a long time, which could cause errors, one workaround is to let all workers do the same work as rank 0 (checkpoints saving, evaluation, and so on).
Data sharding is one of the most important things to consider when using distributed training. You can use TensorFlow dataset.shard() in your script. SageMaker also offers a dataset shard feature in the inputs channel by setting distribution=S3shardbykey in the dataset channel. See the following code:
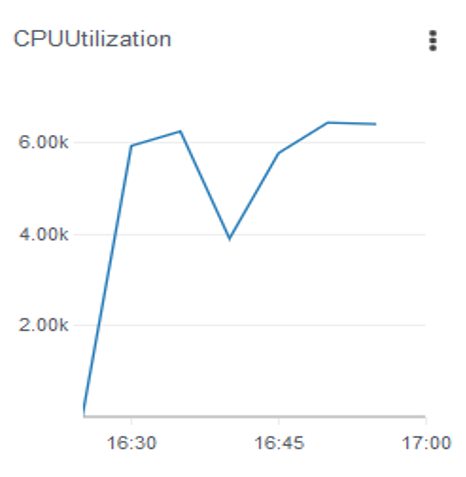
The following figure shows the result when using Horovod (ml.c5.18xlarge, Horovod + LibSVM + default intra op and inter op setting), which you can compare to the tower method.
Distributed training with multiple GPUs on a single instance
It’s normal to start distributed training with multiple GPUs on a single instance because data scientists only need to manage one instance and take advantage of the high-speed interlink between GPUs. SageMaker training jobs support multiple instance types that have multiple GPUs on a single instance, such as ml.p3.8xlarge, ml.p3.16xlarge, ml.p3dn.24xlarge, and ml.p4d.24xlarge. The method is the same as multiple CPUs in a single instance, but with a few changes in the script.
Tower method
The tower method here is almost the same as in multi-CPU training. You need to scale the batch size according to the number of GPUs in use.
TensorFlow MirroredStrategy
The default sub-strategy of MirroredStrategy is NcclAllReduce. You need to scale the batch size according to the number of GPUs in use. See the following code:
Accelerate training on multiple instances
Scaling out is always an option to improve training speed. More and more data scientists choose this as a default option in regards to distributed training. In this section, we discuss strategies for distributed training with multiple hosts.
Multiple CPUs with multiple instances
There are four main methods for using multiple CPUs with multiple instances when enabling distributed training:
-
- Parameter server without manually setting operators’ parallelism on CPU devices
- Parameter server with manually setting operators’ parallelism on CPU devices
- Parameter server with tower (setting CPU devices manually, and set
allow_soft_placement=True in tf.ConfigProto) - Horovod
When using a parameter server in the tf.estimator API, the path of checkpoint must be a sharable path such as Amazon S3 or the local path of Amazon Elastic File Service (Amazon EFS) mapping to the container. For a parameter server in tf.keras, the checkpoint path can be set to the local path. For Horovod, the checkpoint path can be set to a local path of the training instance.
When using a parameter server and the tf.estimator API with the checkpoint path to Amazon S3, if the model is quite large, you might encounter an error of the primary is stuck at saving checkpoint to S3. You can use SageMaker built-in container TensorFlow 1.15 or TensorFlow 1.15.2 or use Amazon EFS as the checkpoint path of the share.
When using a parameter server for multiple hosts, the parameter load on each parameter server process may be unbalanced (especially when there are relatively large embedding table variables), which could cause errors. You could check the file size of each the shard’s checkpoint in Amazon S3 to determine whether the parameters on the parameter server are balanced, because each parameter server corresponds to a shard of the checkpoint file. To avoid such issues, you can use the partitioner function to try to make the parameters of each parameter server evenly distributed:
Single GPU with multiple instances
SageMaker training jobs support instances that only have one GPU, like the ml.p3.xlarge, ml.g4dn, and ml.g5 series. There are two main methods used in this scenario: parameter servers and Horovod.
The built-in parameter server distributed training method of SageMaker is to start a parameter server process and a worker process for each training instance (each parameter server is only responsible for part of the model parameters), so the default is multi-machine single-GPU training. The SageMaker built-in parameter server distributed training is an asynchronous gradient update method. To reduce the impact of asynchronous updates on training convergence, it’s recommended to reduce the learning rate. If you want to use all the GPUs on the instance, you need to use a combination of parameter servers and the tower method.
For Horovod, just set processes_per_host=1 in the distribution parameter of the SageMaker Python Estimator API.
Multiple GPUs with multiple instances
For parameter servers and the tower method, the code changes are basically the same as the tower method for a single instance with multiple GPUs, and there is no need to manually set the GPU devices.
For Horovod, set processes_per_host in the distribution parameter to the number of GPUs of each training instance. If you use Pipe mode, the number of workers per instance needs to match the number of channels.
Data pipelines
In addition to the infrastructure we have discussed, there is another important thing to consider: the data pipeline. A data pipeline refers to how you load data and transform data before it feeds into neural networks. CPU is used to prepare data, whereas GPU is used to calculate the data from CPU. Because GPU is an expensive resource, more GPU idle time is inefficient; a good data pipeline in your training job could improve GPU and CPU utilization.
When you’re trying to optimize your TensorFlow data input pipeline, consider the API order used in TensorFlow datasets, the training data size (a lot of small files or several large files), batch size, and so on.
Let’s look at the interaction between GPU and CPU during training. The following figures compare interactions with and without a pipeline.

A better pipeline could reduce GPU idle time. Consider the following tips:
- Use simple function logic in extracting features and labels
- Prefetch samples to memory
- Reduce unnecessary disk I/O and networking I/O
- Cache the processed features and labels in memory
- Reduce the number of replication times between CPU and GPU
- Have different workers deal with different parts of the training dataset
- Reduce the times of calling the TensorFlow dataset API
TensorFlow provides a transform API related to dataset formats, and the order of the transformation API in TensorFlow affects training speed a lot. The best order of calling the TensorFlow dataset API needs to be tested. The following are some basic principles:
- Use a vectorized map. This means call the TensorFlow dataset batch API first, then the dataset map API. The custom parsing function provided in the map function, such as
decode_tfrecordin the sample code, parses a mini batch of data. On the contrary, map first and then batch is a scalar map, and the custom parser function processes just one sample. - Use the TensorFlow dataset cache API to cache features and labels. Put the TensorFlow dataset cache API before the TensorFlow dataset repeat API, otherwise RAM utilization increases linearly epoch by epoch. If the dataset is as large as RAM, don’t use the TensorFlow dataset cache API. If you need to use the TensorFlow dataset cache API and shuffle API, consider use the following order: create TensorFlow dataset object -> cache API -> shuffle API -> batch API -> map API -> repeat API -> prefetch API.
- Use the
tfrecorddataset format more than LibSVM format. - File mode or Pipe mode depends on your dataset format and amount of files. The
tfrecorddatasetAPI can setnum_parallel_readsto read multiple files in parallel and setbuffer_sizeto optimize data’s reading, whereas thepipemodedatasetAPI doesn’t have such settings. Pipe mode is more suitable for situations where a single file is large and the total number of files is small. We recommend using a SageMaker processing job to do the preprocessing work, such as joining multiple files to a bigger file according to labels, using a sampling method to make the dataset more balanced, and shuffling the balanced dataset.
See the following code sample:
For training on CPU instances, setting parallelism of intra op, inter op, and the environment variable of MKL-DNN is a good starting point.
Automatic mixed precision training
The last thing we discuss is automatic mixed precision training, which can accelerate speed and result in model performance. As of this writing, Nvidia V100 GPU (P3 instance) and A100 (P4dn instance) support Tensor core. You can enable mixed precision training in TensorFlow when using those types of instances. Starting from version 1.14, TensorFlow has supported automatic mixed precision training. You can use the following statement to wrap your original optimizer:
If the model is small and utilization of GPU is low, there’s no advantage of automatic mixed precision training. If the model is large, automatic mixed precision training can accelerate training speed.
Conclusion
When you start your deep learning model training in SageMaker, consider the following tips to achieve a faster training speed:
- Try the multi-CPU, single-instance method or single-GPU, single-instance method first. If CPU/GPU utilization is very high (for example more than 90%), move to the next step.
- Try more CPUs in single host or more GPUs in single host. If utilization is near the maximum utilization of CPUs or GPUs, move to the next step.
- Try multiple CPUs or multiple GPUs with multiple hosts.
- You need to modify codes when using parameter servers or Horovod. The code modification isn’t the same for the TensorFlow session-based API,
tf.estimatorAPI, andtf.kerasAPI. A parameter server or Horovod may show different training speeds in different training cases and tasks, so try both methods if you have the time and budget to determine the best one.
Keep in mind the following advice:
- Check utilization before scaling, optimize your data pipeline, and make CPU and GPU overlap in the timeline.
- First scale up, then scale out.
- If you can’t increate your GPU utilization after all the methods, try CPU. There are many cases (especially for the clickthrough rate ranking model) where the total training time of CPU instance training is shorter and more cost-effective than GPU instance training.
We also have a code sample in the GitHub repo, where we show two samples of DeepFM distributed training on SageMaker. One is a TensorFlow parameter server on CPU instances, the other one is Horovod on GPU instances.
About the Authors
 Yuhui Liang is a Sr. Machine Learning Solutions Architect. He’s focused on the promotion and application of machine learning, and deeply involved in many customers’ machine learning projects. He has a rich experience in deep learning distributed training, recommendation systems, and computational advertising.
Yuhui Liang is a Sr. Machine Learning Solutions Architect. He’s focused on the promotion and application of machine learning, and deeply involved in many customers’ machine learning projects. He has a rich experience in deep learning distributed training, recommendation systems, and computational advertising.
 Shishuai Wang is a Sr. Machine Learning Solutions Architect. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world.
Shishuai Wang is a Sr. Machine Learning Solutions Architect. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys watching movies and traveling around the world.