Artificial Intelligence
Train Neural Machine Translation Models with Sockeye
Have you ever wondered how you can use machine learning (ML) for translation? With our new framework, Sockeye, you can model machine translation (MT) and other sequence-to-sequence tasks. Sockeye, which is built on Apache MXNet, does most of the heavy lifting for building, training, and running state-of-the-art sequence-to-sequence models.
In natural language processing (NLP), many tasks revolve around solving sequence prediction problems. For example, in MT, the task is predicting a sequence of translated words, given a sequence of input words. Models that perform this kind of task are often called sequence-to-sequence models. Lately, deep neural networks (DNNs) have significantly advanced the performance of these models. Sockeye provides both a state-of-the-art implementation of neural machine translation (NMT) models and a platform to conduct NMT research.
Sockeye is built on Apache MXNet, a fast and scalable deep learning library. The Sockeye codebase leverages unique features from MXNet. For example, it mixes declarative and imperative programming styles through the symbolic and imperative MXNet APIs. It also uses data parallelism to train models on multiple GPUs.
In this post, we provide an overview of NMT, and then show how to use Sockeye to train a minimal NMT model with attention.
How sequence-to-sequence models with attention work
To understand what’s going on under the hood in Sockeye, let’s take a look at the neural network architecture that many academic groups and industry commonly use.
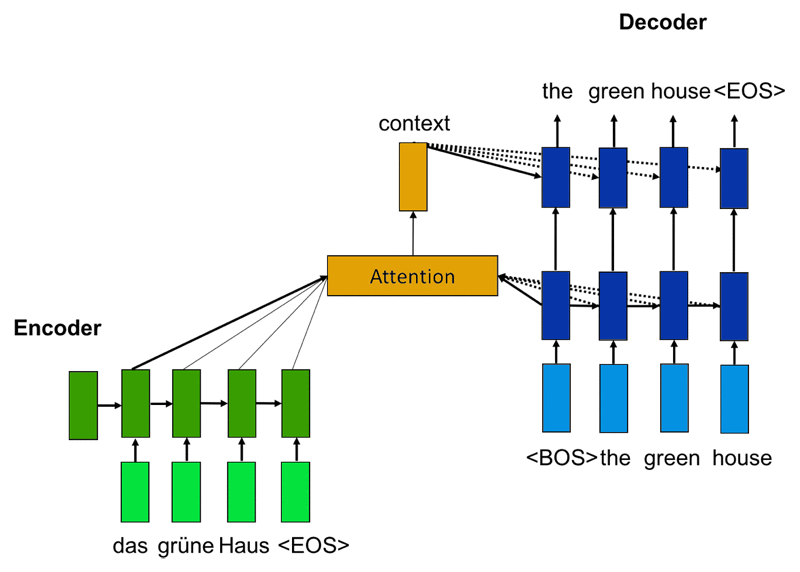
The network has three major components: the encoder, the decoder, and the attention mechanism. The encoder reads the source sentence one word at a time until the end of sentence (<EOS>) and produces a hidden representation of the sentence. The encoder is often implemented as a recurrent neural network (RNN), such as a long short-term memory (LSTM) network.
The decoder, which is also implemented as an RNN, produces the target sentence one word at a time, starting with a beginning-of-sentence symbol (<BOS>). It has access to the source sentence through an attention mechanism that generated a context vector. Using the attention mechanism, the decoder can decide which words are most relevant for generating the next target word. This way, the decoder has access to the entire input sentence at all times.
The next word that the network generates becomes an input to the decoder. The decoder produces the subsequent word based on the generated word and its hidden representation. The network continues generating words until it produces a special end-of-sentence symbol, <EOS>.
Sockeye: Sequence-to-sequence modeling for MT with MXNet
Sockeye implements state-of-the-art sequence-to-sequence models in MXNet. It also provides appropriate default values for all of the hyperparameters for sequence-to-sequence models. For optimization, you don’t need to worry about stopping criteria, metric tracking, or weight initialization. You can simply run the provided training command line interface (CLI).
You can easily change the basic model architecture, including the following elements:
- The RNN cell type (LSTM or GRU) and hidden state size
- The number of RNN layers
- The size of source and target sequence embeddings
- The type of attention mechanism applied over the source encoding
Sockeye also supports more advanced features, such as:
- Beam search inference
- Easy ensembling of multiple models
- Residual connections between RNN layers (Wu et al., 2016)
- Lexical biasing of output layer predictions (Arthur et al., 2016)
- Modeling coverage (Tu et al., 2016)
- Context gating (Tu et al., 2017)
- Cross-entropy label smoothing (e.g., Pereyra et al., 2017)
- Layer normalization (Ba et al, 2016)
For training, Sockeye gives you full control over important optimization parameters. For example, you can set the optimizer types, learning rate, momentum, weight decay, and early-stopping conditions. Sockeye tracks multiple metrics (including MT-specific metrics, like BLEU) on the training and validation data.
We plan to continuously extend the Sockeye feature set to provide researchers a platform for experimenting with new ideas for NMT.
Training a minimal model and using it for translation
Now, let’s train our first NMT model. We expect that the following commands are run on the shell of any Unix like operating system like Linux or Mac OS X.
Get the dataset
First, acquire a parallel corpus. A parallel corpus is a list of sentences and their translations. Sockeye expects all input data to be tokens delimited with whitespace. Before feeding data into Sockeye, always run a tokenizer that separates words and punctuation. For this post, you download the tokenized training and development data from the 2017 news translation task of the Conference on Machine Translation (WMT).
To download German and English parallel sentences from news articles, use the following shell commands:
Here we only use the first 1,000,000 sentences for training. In practice, you would train a model on a much larger dataset.
To track quality metrics on unseen sentences during training, download a validation set:
You now have the train.de and train.en files, which contain the parallel training sentences, and the newstest2016.tc.de and newstest2016.tc.en files, which contain the unseen validation sentences. It is important to evaluate the model on sentences that have not been seen during training, in order to correctly estimate how well it will perform on new sentences the model has not seen before.
Install Sockeye
Because the models are computationally expensive, we generally recommend running Sockeye on a GPU. That said, you can run it on a computer without a GPU. If you want to run Sockeye on the CPU, install it with the following command:
Note:
When running Sockeye on the CPU, be sure to add --use-cpu to all commands. Otherwise, Sockeye will try to run on a GPU and fail.
If you have a GPU available, install Sockeye for CUDA 8.0 with the following command:
To install it for CUDA 7.5, use this command:
Train the model
Now you’re all set to train your first German-to-English NMT model. Start training by running the following command:
This trains a model with an embedding size of 128 and 512 hidden units. During training, Sockeye regularly prints validation metrics.
Training with a single K80 GPU on a p2 instance takes about 13 hours. After training has finished, you can find all artifacts, such as the model parameters, in the directory called model.
Translate
After training the model, you can begin translation by feeding in tokenized sentences:
This translates to “the green house.” Try translating some more difficult sentences. Be sure to feed in tokenized sentences, where the punctuation marks are separated from all words by whitespaces. Notice that when the model doesn’t know a word, it represents it with the <unk> token.
You can also visualize the attention network. For this, you need to install matplotlib as an additional dependency, if you haven’t already:
To create a file called align_1.png that visualizes the attention network, set the output-type to align_plot:
The output should look similar to this:
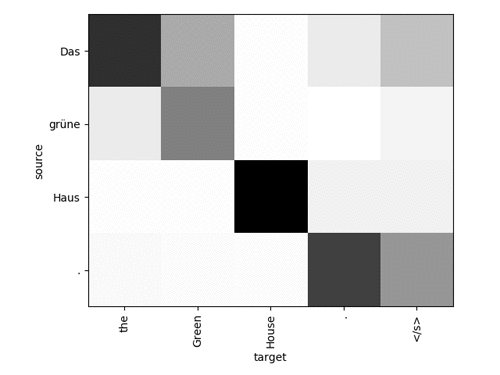
For each word in the target, you see which word in the source that the network paid attention to. The attention doesn’t necessarily need to make sense for the model to produce high-quality translations. For a more complicated sentence, it looks something like this:
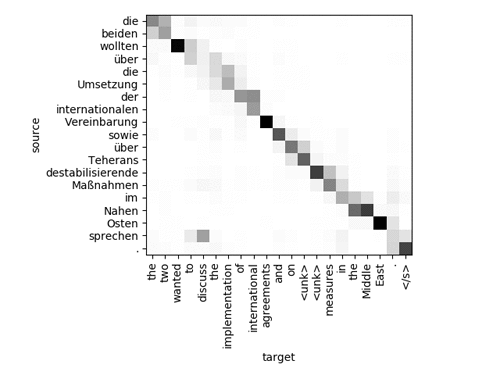
You can see that the model figured out that the word “sprechen” corresponds to “discuss” in English, despite being in a very different position in the sentence. You can also see that the network didn’t know some words and represented them as <unk> tokens.
Summary
In this post, you learned about sequence-to-sequence models for NMT. You also learned how to use Sockeye, a sequence-to-sequence framework based on MXNet, to train and run a minimal NMT model.
If you have questions or suggestions, leave a comment. If you run into any issues with Sockeye, let us know through our issue tracker on GitHub.
Additional Reading
Advance your skills even further. Learn how to deploy deep learning models on Amazon ECS.

About the Authors
Felix Hieber and Tobias Domhan are Machine Learning Scientists at Amazon in Berlin. They work on Machine Translation and Natural Language Processing to provide customers worldwide with content in their own language.

