AWS Public Sector Blog
Q&A with Planet OS: Learn about the OpenNEX Climate Data Access Tool
Planet OS announced their OpenNEX Climate Data Access Tool, which allows users to generate custom datasets from the NASA Earth Exchange GDDP and DCP-30 data. With this launch, Planet OS is helping the NASA Earth Exchange team make these valuable climate datasets accessible to the masses, and taking a big step closer to their long-term vision of changing the way data-driven decisions are made.
We had a few questions for the Planet OS team about the project, how they use AWS, and how they plan to continue their innovation. Check out the Q&A below:
What is the OpenNEX project?
Open NASA Earth Exchange (OpenNEX) is a public-private partnership launched in 2014 to promote the discovery, access, and analysis of NASA Earth Exchange data in support of climate assessment. The OpenNEX project builds upon the work done by NASA Earth Exchange by providing open access to a variety of large-scale data products produced by NEX, as well as complementary tools and resources to encourage engagement with the data.
Why is the OpenNEX Climate Data Access Tool needed?
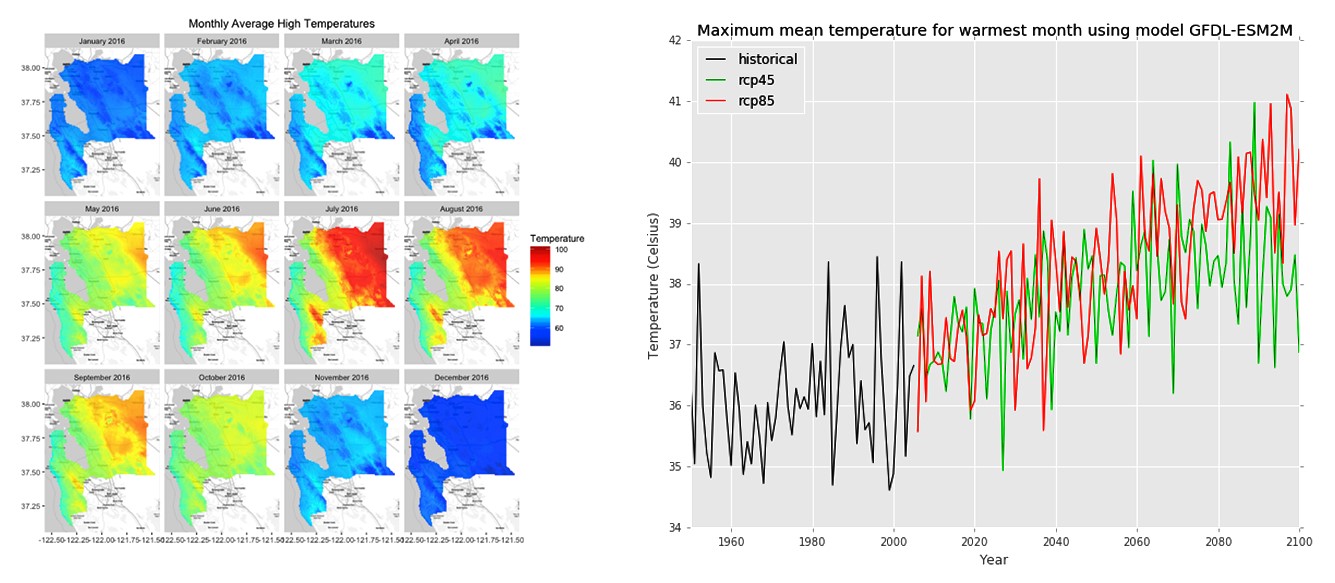
As a part of the OpenNEX project, two downscaled climate projection datasets produced by NEX, Downscaled Climate Projections (NEX-DCP30) and Global Daily Downscaled Projections (NEX-GDDP), were openly published on Amazon Simple Storage Service (Amazon S3) and remain freely accessible there. These downscaled and bias-corrected datasets provide a better representation of regional climate patterns and are useful for determining climate impacts to crop productivity, flood risk, energy demand, and human health. With such a wide range of real-world applications, this climate data is important not only to scientists and researchers, but also to non-technical stakeholders who are responsible for developing response plans, public policy, and climate-related legislation. The OpenNEX Climate Data Access Tool was designed to enable quick, easy access to non-technical users, while also providing more efficient access to tech-savvy domain experts.
How has OpenNEX data being available on Amazon S3 made development easier?
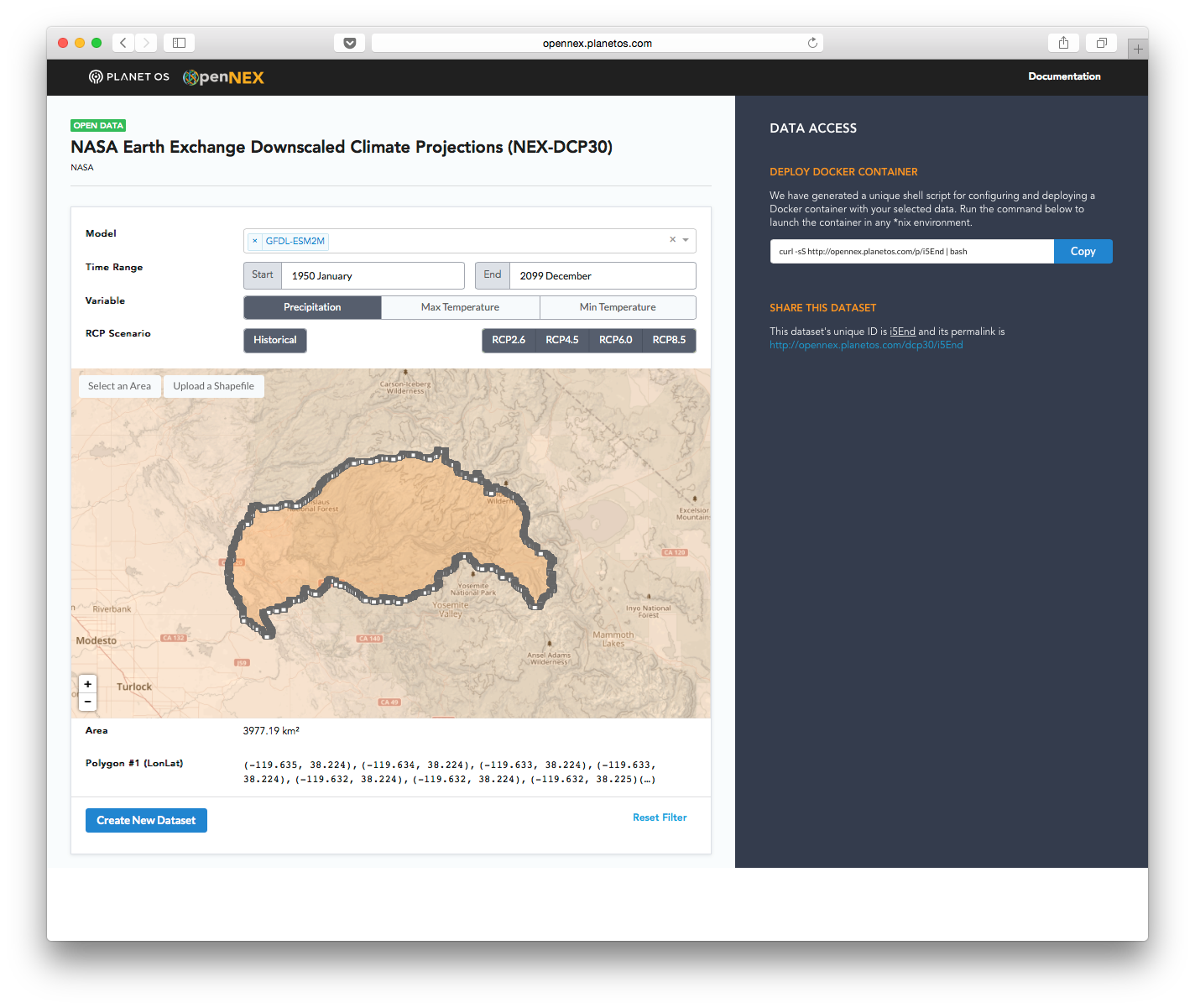
Having the data available in Amazon S3 enabled us to develop a self-serve tool that lets users do their own data transformation wherever they want to do it. If they run their transformations in Amazon Elastic Compute Cloud (Amazon EC2), it’s blindingly fast, but they can also run transformations on their own servers or on a laptop using Docker. To enhance performance and enable efficient spatial subsetting, we have taken the data stored in Amazon S3 and cut it into tiles, which allows our tool to download the requested data much more quickly.
This is just a preliminary release of the tool, what do you expect to add in the future?
In this release of the tool, the key features include:
- Create Custom Datasets – Create a custom dataset by selecting the time, region, parameter, climate model and scenario that matches your needs. Spatial and temporal slicing enables you to download data only within your area and time of interest.
- Deploy via Docker – Run the provided bash script to deploy a Docker container that will acquire and serve the data you selected. This container can be run on a local machine or deployed to a remote EC2 instance.
CSV or NetCDF Format – Download your data in NetCDF or CSV format. The availability of a CSV option means data can be loaded directly into applications without NetCDF support, such as Excel. - Reproducible – Deploy your container to an EC2 instance and expose the access endpoint to allow others direct access to your custom dataset. You can also share the unique dataset permalink with colleagues, who can launch their own containers to replicate your dataset.
In the future, we hope to integrate these climate datasets with our public Datahub to provide fully programmatic access to the data via our APIs. We’d also like to expand the scope of available data products by partnering with other government agencies and data publishers who are interested in improving their data accessibility.
These climate datasets are very large, how did you approach making them easier to understand and access?
We built a web front end that presents the data as a single dataset and lets users interactively select the subset they want. The system generates a simple URL that’s a link to a data structure describing that selection. The user pulls from this URL to launch a container that does the transformation on a node of their own.
One of the key elements of this model is that users never see the divisions between files or any data that’s out of the specified bounds. As a result, the user of the data just pulls the transformed data and performs the analysis they want on it directly, without needing to merge or filter. The data can be delivered in CSV format so that even tools like Excel can access it directly, or in the richer NetCDF format which allows for high-speed loading and analytics.
How do you expect others to build on top of the OpenNEX Climate Data Access Tool?
We’d love to see people explore the potential impacts of climate change in their local communities and begin to share their own custom datasets with one another. We’ve published a number of examples in our documentation to help people get started and highlight what’s possible.
We also encourage users to reach out with their own examples and use cases, or suggestions for improvements and future features at feedback@planetos.com. For those wanting to learn more, we recommend reviewing the online documentation and joining our free webinar on September 21 where Tom Faulhaber and Dr. Sangram Ganguly will demonstrate how to use the OpenNEX data tool.
Thank you to the Planet OS team for answering our questions and we look forward to future iterations of the tool!