AWS Public Sector Blog
Unlocking data governance for multiple accounts with Amazon DataZone

In this post, we discuss how Amazon Web Services (AWS) can help you successfully set up an Amazon DataZone domain, aggregate data from multiple sources into a single centralized environment, and perform analytics on that data. Additionally, this post provides a sample architecture as well as a walkthrough on how to set up that architecture. Ultimately, this post serves as a valuable resource if you’re seeking to optimize your data management processes and derive actionable insights to drive business growth.
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. Businesses face tough challenges in achieving data governance, like compliance, security, scalability and management overhead. Developing solutions in-house can be complex and resource-intensive. Amazon DataZone offers an out-of-the-box solution, making data governance simpler while saving time and resources. This empowers engineers, data scientists, product managers, analysts, and business users with simplified access to data across the organization. By facilitating seamless data discovery, utilization, and collaboration, Amazon DataZone empowers stakeholders to unlock valuable data-driven insights with ease.
Solution overview: Associating multiple AWS accounts to publish and consume data from Amazon DataZone
Most real-world workloads involve managing data from multiple sources, which can become complex very quickly without a way of cataloging the data. With Amazon DataZone, you can automate the data discovery and catalog all existing and new data into a centralized account. Amazon DataZone enables you to distribute the ownership of data, creating a data mesh.
The sample solution presented in this post uses Amazon DataZone to achieve data governance. It enables data producers to retain ownership of their data while making it discoverable to other members of their organization, allowing them to subscribe, and perform analytics on multiple sources of data. The solution also uses AWS Lake Formation to centrally manage and scale fine-grained data access permissions in conjunction with Amazon DataZone. The outlined solution covers how accounts can be associated to the same Amazon DataZone domain, how data is published to the domain, and how to subscribe and perform queries on that data. It shows how Amazon DataZone enhances accessibility, empowering you across engineering, data science, product management, analysis, and business sectors.
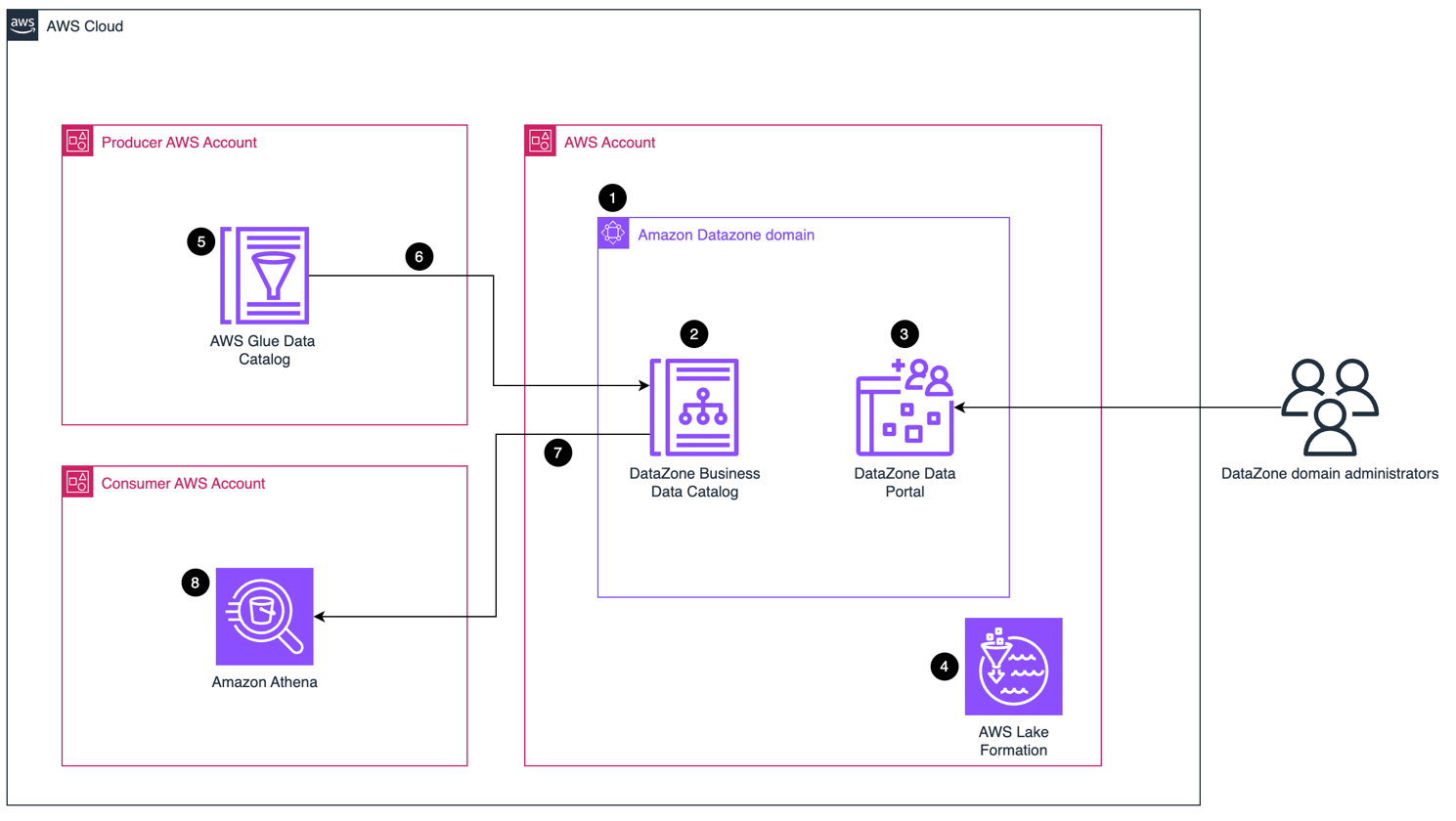
Figure 1. Architecture diagram of the example solution described in this post. Major components are Amazon DataZone, Amazon Athena, and Lake Formation.
Figure 1 illustrates the following:
- Amazon DataZone domain. You can use Amazon DataZone domains to organize your data assets, users, and their projects.
- The Amazon DataZone business data catalog. This allows you to organize data throughout your organization with relevant business context, making it easy for everyone to locate and comprehend data.
- The Amazon DataZone data portal. This is a browser-based web application used by the domain administrators where you can go to catalog, discover, govern, share, and analyze data in a self-service fashion.
- Lake Formation is used to set fine-grained permissions.
- AWS Glue Data Catalog with metadata in the producer account.
- The data from the Glue Data Catalog is published and visible in the business data catalog.
- The consumer account subscribes to data in the business data catalog.
- The data is queried using Amazon Athena.
If you are looking to dive deeper in the Amazon DataZone concepts introduced here, visit the Amazon DataZone Terminology and Concepts page.
Prerequisites
To create the sample solution, you need:
- Access to at three AWS accounts – one for data producer, one for data consumer, and one for the data hub.
- Sample data available in one account’s Glue Data Catalog. For more information on AWS Glue crawlers, visit Introducing AWS Glue crawlers using AWS Lake Formation permission management
- The correct permissions to use Amazon DataZone
Setting up Amazon DataZone
In the data hub account, create a new Amazon DataZone domain. Then, set up two projects under the domain: one for a data producer and one for a data consumer. You can follow Amazon DataZone Now Generally Available – Collaborate on Data Projects across Organizational Boundaries to get started.
Associating other AWS accounts
For data producers to make their data discoverable, and for consumers to subscribe to that data, it’s necessary for the accounts where the data reside in to be associated with the Amazon DataZone domain.
After creating your domain using the AWS console, select it.

Figure 2: Screenshot of the Amazon DataZone domains tabs, where you can view all of your existing domains, their status, creation date, and delete or create domains.
Under your domain and Associated accounts, choose Request association:

Figure 3: Screenshot of the Amazon DataZone associated account view, showing accounts, status, date added, and option to disassociate or request association of accounts.
This prompts you to enter an account ID. Enter the ID of the account that you want to associate. To retrieve the account ID, use the top right button in that account, as shown in Figure 4.
Figure 4. Screenshot showing where to find the account ID of the account to which you want to request an association.
Once the association request has been sent, log in to the account you have requested an association with and make sure it’s in the same Region as the Amazon DataZone domain. You should be able to see the association request in the Amazon DataZone console under Associated domains, as shown in Figure 5.

Figure 5. Screenshot of the associated domains view after receiving a request to associate. You can choose to reject the association or review the request.
Choose Review request. You are prompted to enable blueprints. The blueprint for creating an environment decides which tools and services, for example AWS Glue, project members can use while working with Amazon DataZone catalog. It is a plan that sets the rules for what tools are available for handling data in the catalog. Enable the Data Lake blueprint and leave the rest as default.
Making data discoverable
Before you make your existing data discoverable on the Amazon DataZone domain, configuration on Lake Formation is needed:
- In the Producer account, navigate to the Lake Formation Console.
- Under Administration and Data Lake locations, choose Register Location.
- For the Amazon S3 path, choose Browse and select the bucket URL that contains your data.

Figure 6: Screenshot that shows the list of buckets from step 3 and the option to select a bucket.
- Choose the Lake Formation permission mode and register the location.
- Still in the Lake Formation console, under Permissions, choose Data Lake Permissions.
- Look for any permissions that apply to the AWS Glue database and table where your data resides, where the principal is IAMAllowedPrincipal and revoke them.
Now that this is set up, log in to the Amazon DataZone portal in the main account, and under the Producer project, select environments, and then Create environment profile. An environment profile is a template used to create an environment, which is a collection of zero or more configured resources on which a given set of IAM principals can operate. Instead of creating the same environment with the same configuration multiple times, you can use a profile to make it easier. In our scenario, environment profiles are used to define and tell Amazon DataZone which account is associated with that environment. Without profiles, Amazon DataZone uses the account where the domain is hosted in by default.
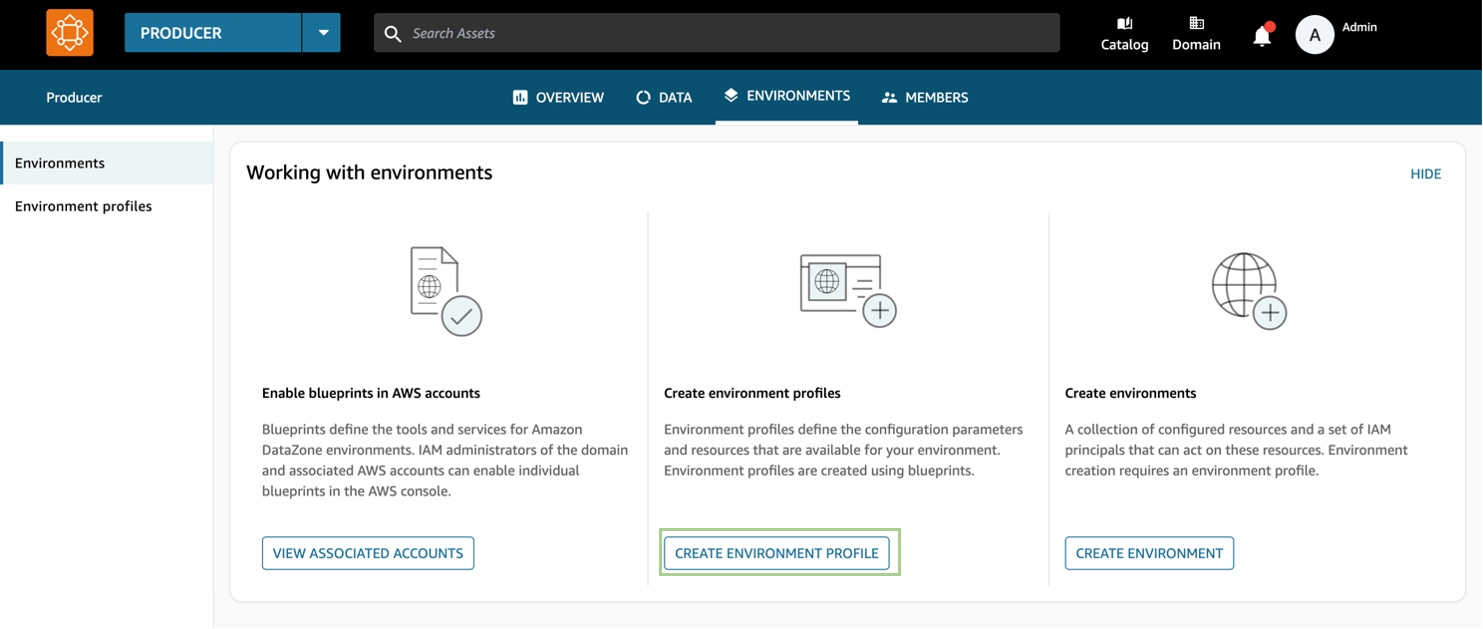
Figure 7: Screenshot of the Amazon DataZone portal section on environments, where users can create an environment profile.
In the creation wizard, give a name to the profile, assign an owner and select the DefaultDataLake blueprint. This unlocks a new visual where you can select the correct AWS account, as well as the AWS Region. Leave the default settings in place and your environment profile should be created.
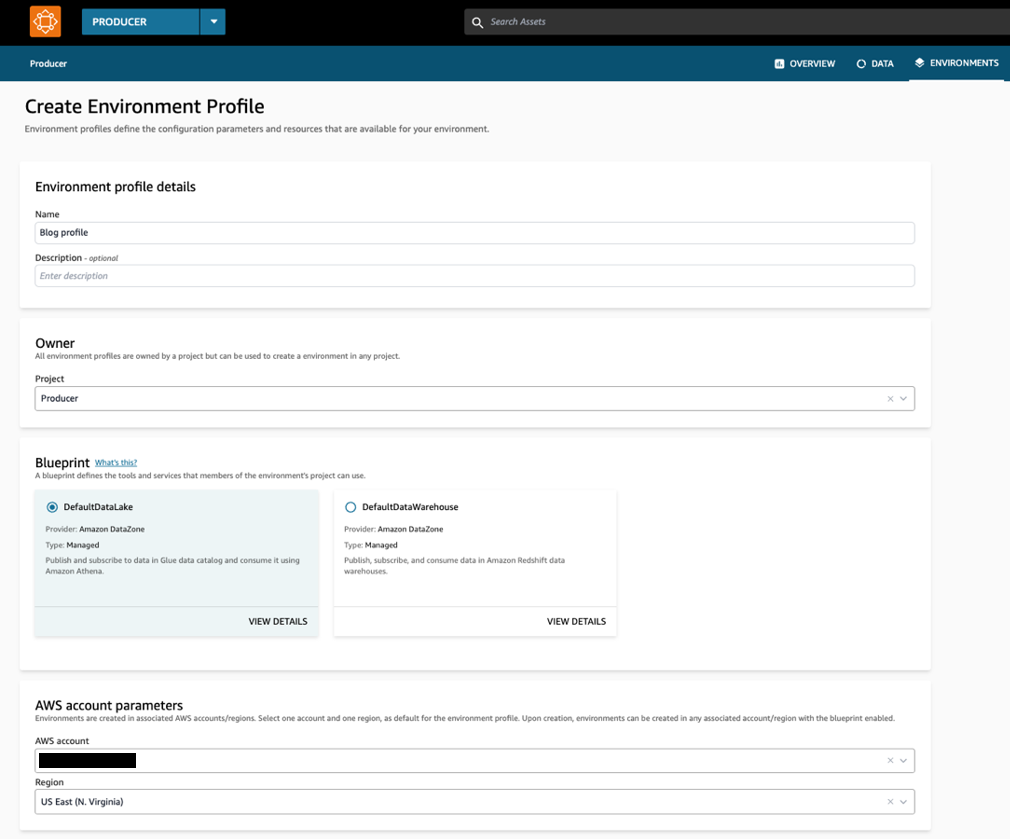
Figure 8: Screenshot of the environment profile creation wizard in the Amazon DataZone Data Portal, which contains profile details, blueprint information, and AWS account parameters.
Now, going back to the Amazon DataZone project, you can create an environment and select the newly-created environment profile. Once again, you can follow the environment creation steps in the post linked earlier, but make sure to select the profile that you just created.
Once your environment is created, you can see under Data sources that a default data source has been created automatically. However, here, we want to use existing data from your data producer account.
Still under data sources, select Create Data Source in the top right of the page. In this final step, we ask Amazon DataZone to find your existing data and add it as a data source. In the wizard, give a name to the data source and select AWS Glue as the source type.
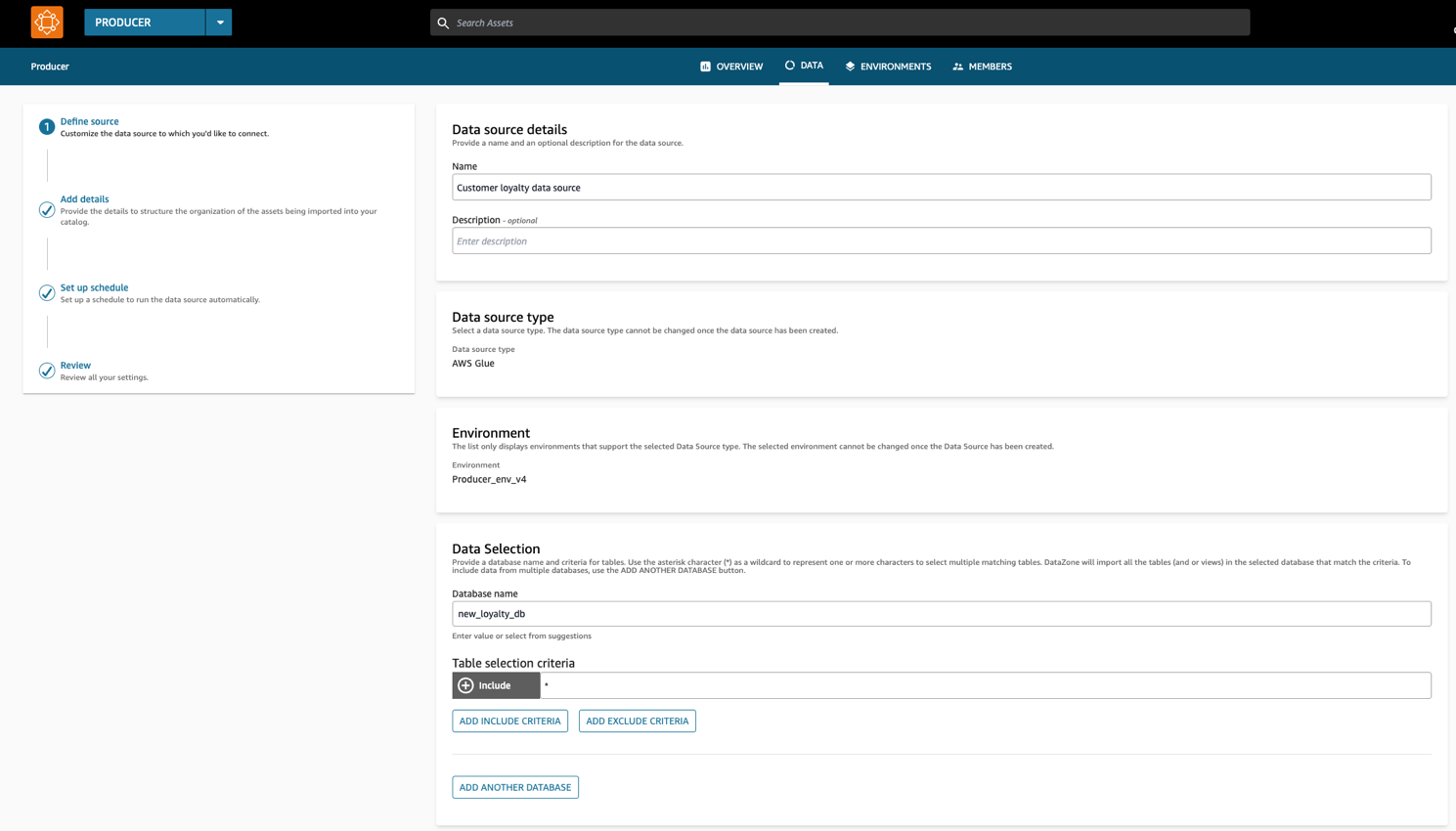
Figure 9: Screenshot of the Create Data Source wizard on the Amazon DataZone Data Portal, which contains data source details, data source type, environment, and data selection.
Note that the database name field needs to be the same as the one present on your producer account’s Glue Data Catalog. Continue to the next steps and leave everything as default. On the Set-up schedule stage, select Run on demand. Review your settings and create your data source.
Once the data source has been created, choose Run on the top right. When you create and run an AWS Glue data source, you add assets from the source AWS Glue database to your Amazon DataZone project’s inventory. Now, choose the dataset to explore the data.
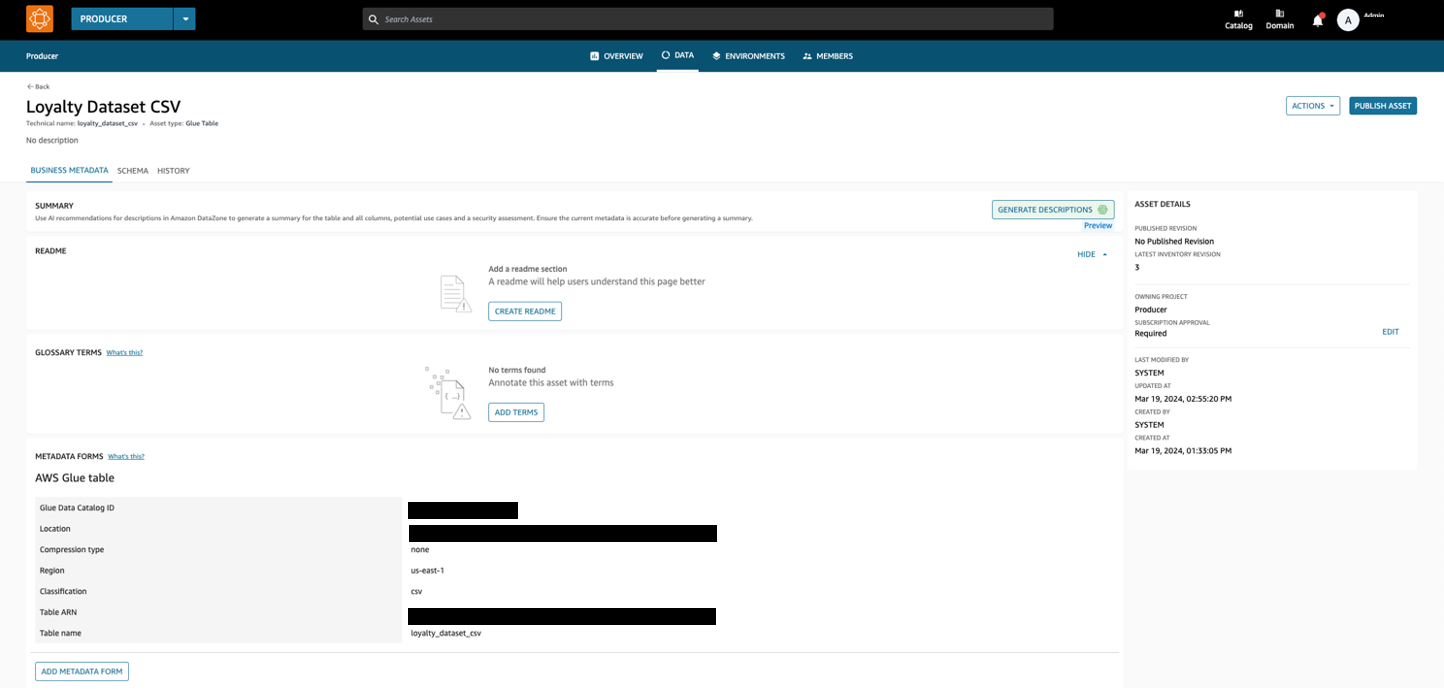
Figure 10: Screenshot of the Loyalty Dataset visible on the Amazon DataZone Data Portal and ready for publication.
You can select the schema tab to view the data schema. If everything was set up correctly, you should be able to see your dataset. This page is incredibly handy as it compiles all the key information about a dataset. When another project wants to subscribe to the data, they can quickly grasp what it includes before diving into analysis.
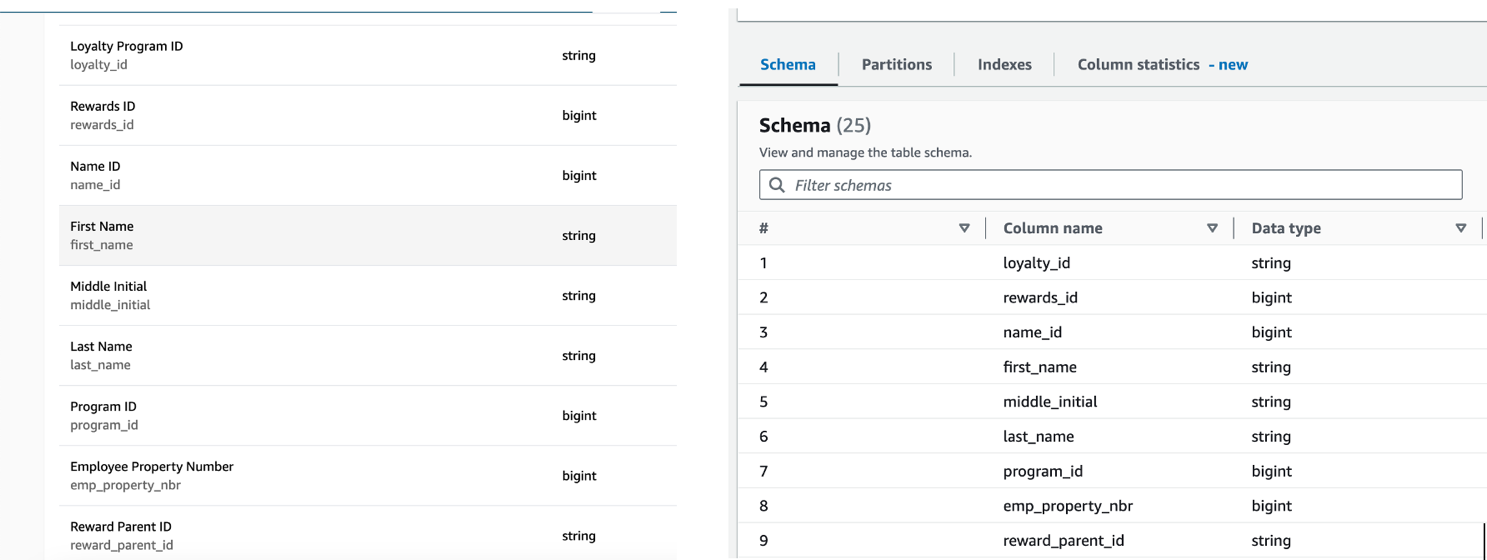
Figure 11: Side-by-side view of the dataset’s schema. On the left, the view from the Amazon DataZone portal. On the right, from the producer account’s AWS Glue console. This shows that the data has been maintained across the two accounts.
What you have done so far showcases how simple it is to make data discoverable using Amazon DataZone. While this is done only on one account, it can be repeated for other accounts associated with the Amazon DataZone account. Amazon DataZone makes it simple for you to share your existing data across your organization even when that data resides in different accounts. This is all done without the need to request permissions for every account and their data. Now, publish the data using the top right button on your page to make it available for subscription.
Subscribing and consuming the data
When data is published by a project, it’s visible in the Amazon DataZone business data catalog and for every member of the Amazon DataZone domain to see. Publishing data enables members of your organization to view all the data that is available and shared in one unified place. In addition, other projects can subscribe to the data.
To grant access to the data for the Consumer account, you need to follow the same steps outlined in the Making data discoverable section for this new account. If you haven’t done so already, request an association with the Consumer account, then create a new environment with a new profile in the Consumer project.
To subscribe to the data, search through assets using the search bar for the dataset you are looking for and request a subscription.

Figure 12: Screenshot of the subscription process in Amazon DataZone. 1. Using the search bar, search the dataset you are looking to subscribe to. 2. Choose subscribe to request a subscription. 3. The subscription notification appears at the top of the page, under the bell icon.
After a few seconds, a subscription notification appears and you can accept or reject the subscription request. Once the subscription is approved, it appears under the requester’s project’s subscribed assets, though the subscription approval is still the data owner’s responsibility. The data may be published to the organization, but the producers retain ownership of the data.
Once data is subscribed to, Amazon DataZone provides the project members with the ability to query the data using Athena. This is because the project is configured with the DefaultDataLake blueprint, which allows project members to interact with Athena.

Figure 13. Screenshot of the view from the consumer project after subscribing to the data.
To query the data, make sure that you go back to the Consumer project. Choosing Query Data takes you to the Athena console. On the left panel, choose the database that ends with sub_db. You can query across all of your subscriptions. This shows the power of Amazon DataZone, because you can now derive insights across multiple datasets in your organization by subscribing to the data.
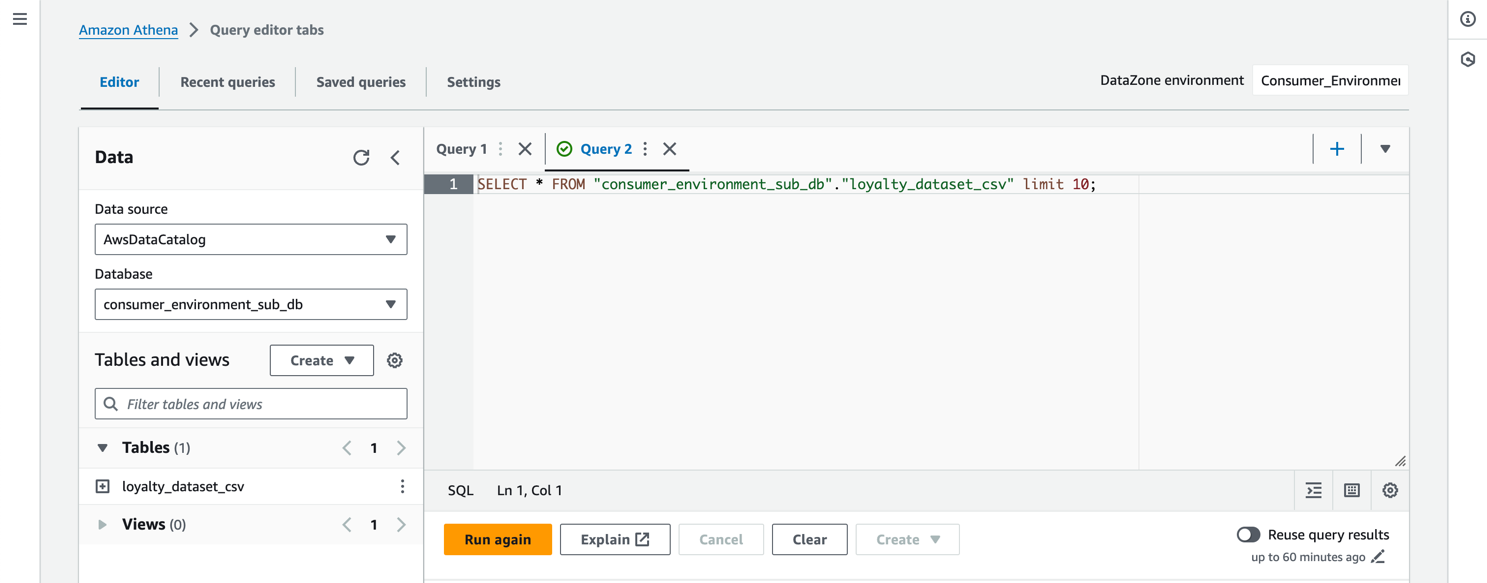
Figure 14: Screenshot showing the querying of data with the Athena console. You can view the tables you are subscribed to and perform queries.
The subscribed data can also be accessed in the consumer account’s Glue Data Catalog. This means the data can be used just as any other AWS Glue database in your account. For instance, you could try creating visualizations with Athena as a data source for Amazon QuickSight. To learn more about this, visit the Amazon QuickSight user guide.
Summary and conclusion
This blog covered how to achieve data governance with Amazon DataZone, more specifically, when data resides in different accounts. By delving into the capabilities of AWS and Amazon DataZone, it offers a comprehensive guide on establishing a centralized data environment. In today’s data-driven environment, effective data governance is crucial. The capability to gather, analyze, and manage data from diverse sources while maintaining ownership is a key competitive edge.
To learn more or get started, refer to Data Governance with AWS, Amazon DataZone features and Amazon DataZone on the AWS Console.