AWS Startups Blog
BlackBuck builds future-ready Digital Freight Marketplace using AWS
by Rahul Aggarwal, Director of Engineering at BlackBuck, and Venkatramana Ameth Achar, Solutions Architect at AWS

BlackBuck, India’s largest trucking platform, is a digital freight marketplace for shippers and truckers to conveniently discover each other, providing services such as FASTag (an electronic toll collection system), fuel cards, GPS devices, and insurance, among others, to efficiently manage their fleet. BlackBuck’s business and users have grown rapidly from a few thousand users on the platform to more than 1,000,000 users. With the goal of becoming the world’s largest technology-driven trucking platform, maintaining a data-driven approach, as well as strategic product improvements, put Blackbuck well on its way.
Use Cases
BlackBuck started as a freight marketplace and later expanded into managed services, a shift that brought new sources and formats of data. Data stakeholders include:
- Sales: Our sales team identifies potential demand and supply clusters from various data patterns in clickstreams, order booking search, location data spatial clusters, goods types, and truck types.
- Operations: Geofence alerts provide data for Turn Around Time (TAT) analysis of different stages in operations workflows, like order fulfillment to improve user experience.
- Finance and Pricing: Decisions on dynamic pricing and bid pricing for the freight marketplace are based on historical pricing data, analysis of user activities, liquidity based on real-time clickstream data, and transactions data.
Revolutionizing Architecture with Microservices
BlackBuck’s technology stack has evolved from a monolithic architecture to 100+ microservices and platform components to meet performance, scalability, cost, and feature needs. Each microservice can have different technology choices and nuances around data storage and retrieval, hence it became increasingly complex to build data-centric applications. BlackBuck needed to build a platform that would enable it to quickly build and deploy data heavy and machine learning (ML)-based applications.
The former architecture used a self-managed Presto cluster with read replicas of databases from different applications. However, this structure was difficult to scale, requiring costly additional Presto nodes or upsizing read replicas. It also lacked support for streaming use cases, third-party data ingestion capabilities, or governance around schema upgrades. Changes would also need to be made to support cost attribution and data science use cases, such as feature generation, model training, and orchestration.
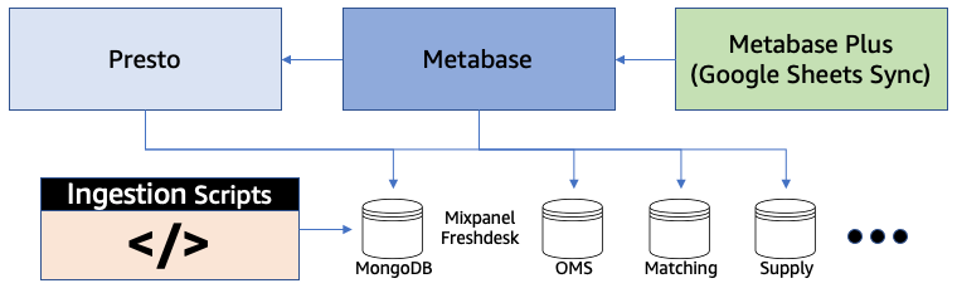
New Data Platform architecture
BlackBuck set out to build the new platform with clear design considerations in mind: supporting ease of data ingestion and with strict governance, an open data lake with fact generation and high query performance, real-time stream processing, and avoiding any cost surprises.
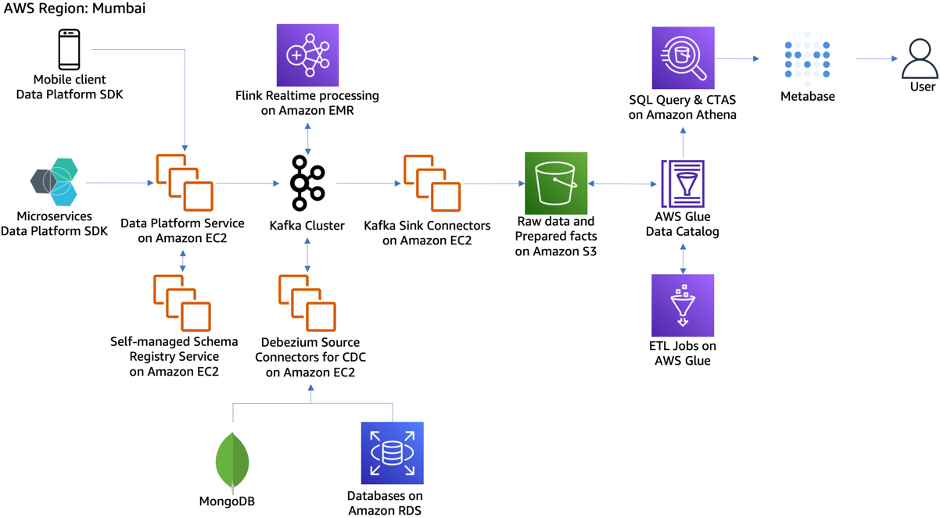
- Data ingestion with ease and with strict governance:
- Data Platform API Server and Schema Registry: Incoming data schemas are registered in self-managed Schema Registry Service before ingesting data into Kafka. Schema Registry also maintains schema versions to ensure changes are backward compatible. Validity of each data record is checked using the schema id present in the record, invalid data record is rejected to maintain data sanity. Rate limiting per schema was put in place to ensure optimal usage of storage capacity, especially when users with large data sets were onboarded onto the new platform.
- Data Platform SDKs: SDKs were built for backend microservices and mobile apps to send transactional logs and custom events into the platform. The SDKs handled batching, and provided data delivery guarantees against infrastructure failures.
- Change Data Capture (CDC) using Debezium: Kafka cluster with Debezium connectors are used to get new data from Amazon RDS and MongoDB into Kafka. In case of schema changes in Kafka, a AWS Glue Crawler would be triggered to update AWS Glue Data Catalog.
- Open data lake, fact generation, and high query performance: Parquet was selected as the best fit for its data storage format. For the query engine, Amazon Athena was a winner from a management and cost perspective. AWS Glue jobs merge small files in a single partition to further improve query performance. Creating a Table from Query Results (CTAS) queries are scheduled to generate reusable facts. CTAS creates a new table populated with the results of a SELECT query.
- Real-time stream processing: With the data streaming through Kafka in real time, real-time stream processing use cases were easy to solve. For example, we used windowing functions in Apache Flink on Amazon EMR to solve a use case where we need to send custom notifications to users based search patterns. Data at rest in the data lake is also used in the Flink jobs when needed.
- Cost controls and data security: Amazon Athena with Parquet data on Amazon S3 provided up to 10x performance improvement over our former setup. However, cost became a concern, as users stopped optimizing queries because they were getting results quickly. Also, at times, users needed to query a huge data set on a non-partitioned key. Different Athena workgroups were created for different teams to attribute query costs to respective use cases. Athena workgroups was configured to cancel queries breaching thresholds, alert on daily limit breaches, and restrict user access to specific data.
The next step was to build a data science platform that enabled the data science team to explore the data from different sources, and quickly build, train, and deploy models into production.
Data Science Platform Architecture
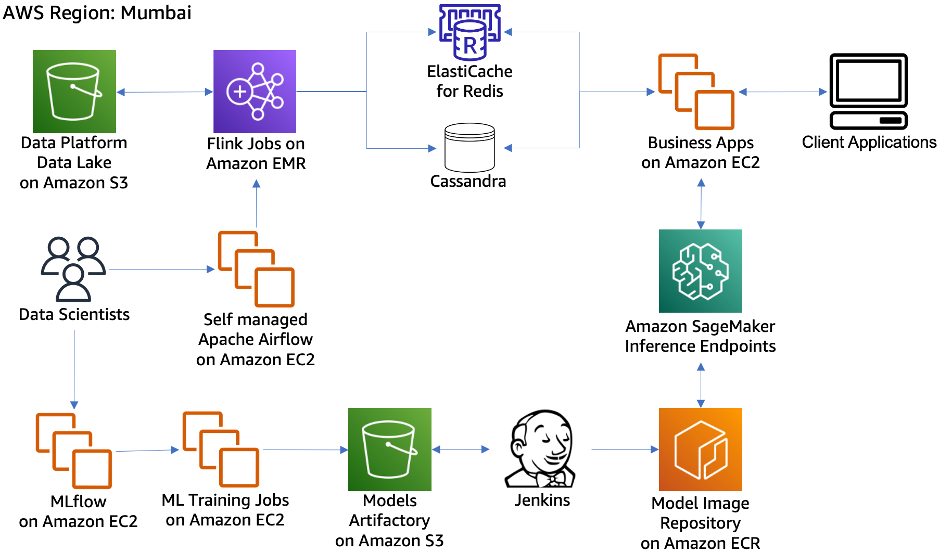
- Feature generation, feature store and model training: Flink on Amazon EMR is used for real-time feature generation. The Data Science team uses self-managed Apache Airflow on Amazon EC2 to schedule queries on Amazon EMR. The features generated are stored in Cassandra, and are cached in Amazon ElastiCache for Redis with a TTL for reuse.
- Model Build: We needed a model development environment which supports a variety of ML libraries to assist with deploying models and provide freedom to build models using language and libraries of the team’s choice. After evaluating their options, the team landed on MLflow on EC2 for its end-to-end lifecycle management.
- Model Deployment, Wrapper Service, and Experimentation: Amazon S3 was used as a model repository. When a model is promoted to production for inference, a CI/CD pipeline creates a Docker image and registers it into Amazon Elastic Container Registry, and then deploys it as an API endpoint on Amazon SageMaker. Amazon SageMaker supports high performance machine learning inference. A wrapper service was used to abstract client applications from feature sets and models used. The wrapper service internally takes cares of looking up the features from the feature store and use the relevant model on SageMaker. This also enabled A/B experiments on different models for the same business use case.
- Monitoring: All the model inferences and key performance metrics are pushed to the Data Platform for further analysis and alerting. The results of A/B experiments are analyzed by joining these key metrics with actual transactions on the platform and understanding each model’s performance.
BlackBuck’s Supply App
With the Data Science Platform established, fleet owner could now search for loads using Supply App.
 |
 |
| Search Dialog Interface | Search Results Interface |
The major source of data to figure out relevancy for a user are the click streams from the users’ activity on the app, location data from FASTag swipes and GPS devices, bookmarked favorite routes by the users, and the transactions done by the user on the platform. Learning to Rank (LTR) supervised ML model is used to solve ranking problems. For LTR, we use a Discounted Cumulative Gain (DCG) based cost function, which is a measure of ranking quality, measures the usefulness, or gain of a load on its position in the result list. The result is further refined based on user’s historical and real-time activity. When a user searches for loads or opens the find loads sections, an API call is made to Amazon SageMaker. The inference from SageMaker is used to show ranked loads on the app.
Conclusion
The new scalable data platform and data science platform gives BlackBuck a unified view of all our data and makes it easier for us to build and deploy analytical, reporting, and ML use cases. As a result of this implementation:
- We achieved over 90% compression over raw data using Parquet columnar storage Data lake on Amazon S3, reducing storage costs.
- We saw 10x performance improvement query performance compared to existing setup in most of our queries.
- We reduced overall costs by 50% compared to when all queries ran on raw data.
- Quick experiments with multiple models on SageMaker helped the Data Science team with A/B testing of models without the need for application changes.
Looking ahead, real-time querying, building and training models at scale, and rich visualizations and dashboards will continue to help BlackBuck use open-source technologies to take data and delight our customers.
 |
Rahul enjoys working closely with Business and Product to solve their key problems using technology. He spends most of his time designing new systems and likes to evaluate and adopt new technologies while paying close attention to low-level details, scalability, performance, operational efficiency and cost. Outside of work, he spends his time playing online games and listening to different genres of music. |
 |
Ameth is a Solutions Architect at AWS. In his 20+ years of work experience he has helped customers achieve their business objectives using his skills in systems integration, prototyping, process automation, architecting solutions on cloud and data centers, as well as team management. He has served customers in ecommerce, semiconductor, finance, education, telecom, aggregators, logistics, media, gaming, security, and electric vehicles domains. On a personal front, he continues to improve his knowledge on renewable energy, music, and digital photography. |