AWS Startups Blog
Combining DynamoDB and Amazon OpenSearch Service with Lambda
September 8th, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Guest post by Michael Garski, Director of Platform Engineering @ Fender Digital

Guest post by Michael Garski, Director of Platform Engineering @ Fender Digital
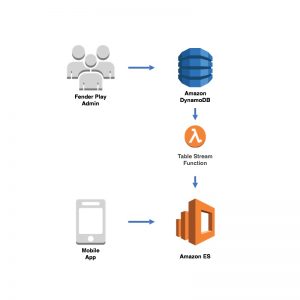
At Fender Digital, we started working with Lambda in mid-2016 and fully embraced it for all new services starting in January 2017. Along with the move to Lambda, we wanted to move away from using an RDBMS unless we truly needed a relational data store and it turns out we didn’t for most of our use cases. DynamoDB was a good option for a data store with usage-based costs; however, it lacked support for full-text queries. Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) provided the search functionality we required, but we were not comfortable using it as our primary data store. With neither option meeting our needs, our engineering team came up with an approach that used both DynamoDB and Amazon OpenSearch Service, keeping the cluster up to date with the table by employing a Lambda function that was invoked by the DynamoDB Stream events on the table. In this way, we could see when an item needed to be added to, removed from, or updated in the cluster based on the data in the stream event.
This combination of DynamoDB and Amazon OpenSearch Service is perfectly suited to our Fender Play lesson content to support full-text queries of song titles that we have instructional content for. When lesson content is created by the Fender Play admins, it is written to DynamoDB, triggering a stream event with the new item which inserts it into the Amazon OpenSearch Service cluster allowing users to then query for the lesson content they are looking for.
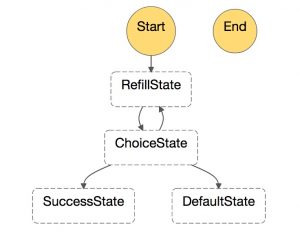
 Our reason for not using Amazon OpenSearch Service as our primary data store was that outside of cluster snapshots, we would not have a disaster recovery solution from a source of truth. Each of our Lambda-based services that use Amazon OpenSearch Service also have a Lambda function that can refill an index by performing a DynamoDB table scan. With a large table, the refill will certainly exceed the five-minute time limit on Lambda invocation, so we use AWS Step Functions for the refill process. When the Step Function is invoked, it calls the refill function with an empty JSON document as the input. During the invocation, the scan process in the refill function keeps track of the time and after four minutes the scan is halted, any remaining items are flushed to the cluster, and the last evaluated key in the scan is returned to the state machine. The state machine enters a choice state where it inspects the return value of the refill function. If the return value includes a last evaluated key, the state machine invokes the refill function with that last evaluated key to continue the scan from where it left off. In this way, the refill function will continue to be invoked as long as the last evaluated key is returned to the state machine. When the refill function completes the scan, it returns an empty JSON document to the state machine which signals that the cluster refill has completed.
Our reason for not using Amazon OpenSearch Service as our primary data store was that outside of cluster snapshots, we would not have a disaster recovery solution from a source of truth. Each of our Lambda-based services that use Amazon OpenSearch Service also have a Lambda function that can refill an index by performing a DynamoDB table scan. With a large table, the refill will certainly exceed the five-minute time limit on Lambda invocation, so we use AWS Step Functions for the refill process. When the Step Function is invoked, it calls the refill function with an empty JSON document as the input. During the invocation, the scan process in the refill function keeps track of the time and after four minutes the scan is halted, any remaining items are flushed to the cluster, and the last evaluated key in the scan is returned to the state machine. The state machine enters a choice state where it inspects the return value of the refill function. If the return value includes a last evaluated key, the state machine invokes the refill function with that last evaluated key to continue the scan from where it left off. In this way, the refill function will continue to be invoked as long as the last evaluated key is returned to the state machine. When the refill function completes the scan, it returns an empty JSON document to the state machine which signals that the cluster refill has completed.
This year, we have ambitious goals as we continue to expand our use of Lambda. We will be migrating our EC2-based services to Lambda, setting them up in multiple regions to provide faster responses to users based on their location and improve application resiliency should a region become unavailable. We will be using the geolocation routing features of Route 53 to direct API traffic to a specific region depending on where the user is located. Our services will be deployed to multiple regions in an active-active configuration with near real-time data replication between regions. Our initial plan was to implement our own cross-region DynamoDB table replication via table streams. However, with the announcement of global tables at re:Invent 2017, cross region table synchronization is now a feature of DynamoDB. Each region that we deploy our application into will have its own DynamoDB tables and Amazon OpenSearch Service cluster, with the cluster kept in sync with the tables through Lambda functions invoked by the table streams when items in the table are modified. In this way, we can ensure the Amazon OpenSearch Service clusters in all regions are kept up to date in near real-time to ensure the user experience is not compromised should one of the supported regions experience a service interruption.