AWS Storage Blog
Autodesk adopts Amazon S3 to save 75% on storage and modernize backup and recovery
Autodesk is a leader in design and software for the architecture, engineering, construction, media and entertainment, and manufacturing industries. If you’ve ever driven a high-performance car, admired a towering skyscraper, used a smartphone, or watched a great film, chances are that you’ve experienced the work of millions of Autodesk customers.
Autodesk has been an AWS Partner Network Advanced Technology Partner for over 6 years, enabling many customers to leverage the benefits of cloud computing technology to design, engineer, and build products.
In this blog post, we cover Autodesk’s journey to the cloud and the Amazon S3 storage classes and features Autodesk uses to save both time and money. This includes a step-by-step overview of Autodesk’s data ingestion pipeline, from the data sources to cloud storage, and an explanation of how Autodesk recovers backup copies of their data. We also review Amazon S3 storage classes, including S3 Standard-Infrequent Access, and S3 Glacier Deep Archive, in addition to S3 features: S3 Batch Operations, S3 Replication, S3 Replication Time Control, S3 Lifecycle Management, S3 Inventory, and S3 Select.
Going all-in on the cloud
In 2018, Autodesk set a long-term goal to divest from data centers and embrace the cloud for its scalability, flexibility, reliability, and security to support its new subscription business model. Removing large upfront capital expenses was especially important in this transition. As part of the overall initiative to move to AWS, Autodesk had 5+ petabytes (PB) of backup data stored in those data centers, consuming expensive storage capacity. This data was comprised of Oracle, VMware, NAS, and SQL Server backups. Moving to AWS brought a dual benefit of both cost savings and reduced operational overhead. In its on-premises storage environment, Autodesk had aging hardware with expensive maintenance overhead, had to manage multiple vendors, constant capacity issues, and was faced with an expensive hardware refresh.
Autodesk decided to use Amazon S3 because of the low cost, consumption-based pricing, high durability, and availability. Autodesk also was drawn to cost savings by using S3 Lifecycle to create policies to transition long-term storage to Amazon S3 Glacier Deep Archive. With AWS, and specifically Amazon S3, Autodesk no longer had to worry about infrastructure maintenance, refresh cycles, or capacity restraints. Ultimately, Autodesk reduced storage costs by up to 75% due to S3’s consumption-based pricing and cost effective-storage classes. Autodesk also leverages Amazon S3 management features to automate data replications, recoveries, and other tasks.
Deciding to move to AWS
Autodesk started with an initiative called “Archive & Digitize Storage” to:
- Discover, analyze, and assess existing vendors.
- Carry out data deletion with the motto of 3Rs (below).
- Migrate PB of data by leveraging AWS Storage as both primary and secondary target storage.
- Set up virtualized agents in data centers by transforming from legacy data center storage and rack compute infrastructure.
Here is the 3Rs motto:
- Revisit the backup policy
- Collaborated with business and legal teams.
- Revise the retention times
- Made changes to our data retention strategy for backups to reduce cost and minimize operational overhead.
- Remove the data that’s no longer required
- Deleted ~2 PB of data.
Refer to this post to learn about how Autodesk swiftly and effortlessly migrated over 700 terabytes (TB) of historical archive data from their on-premises storage system to Amazon S3.
AWS infrastructure provided the scale and flexibility needed to perform this transformation. The Autodesk team estimated it could save around 80% of their operational costs in addition to recurring refresh costs. The storage capacity and automated nature of AWS services allowed the engineering team to focus on digital strategy instead of ongoing administration and maintenance of legacy data center infrastructure. AWS services greatly increased operational agility and supported both short-term and long-term data retentions. By using S3 Replication Time Control (S3 RTC), Autodesk’s disaster recover (DR) recovery point objective (RPO) for mission critical workloads was reduced from 24 hours to 15 minutes. In addition, using S3 Batch Operations and S3 Select, critical data recovery times improved from 48 hours to 5 hours.
Modernized enterprise backup architecture
As part of Autodesk’s migration to AWS, we knew that we could do more than a simple lift and shift of our current capabilities. We saw an opportunity to save more money and time by re-thinking our existing architecture and leveraging the latest Amazon S3 innovations. For this particular post, we detail Autodesk’s process for recovering data from Amazon S3 and restoring it to on-premises on the rare occasions our backups are needed. Previously, this was a manual and time-consuming process as we needed to identify, locate, and validate the files before restoring the backup copy. Using Amazon S3 however, and specifically a managed solution like S3 Batch Operations, this process became much easier, lower-cost, and more performant.
First, here’s a diagram showing our end to end data workflow, from data sources all the way to S3 Glacier Deep Archive for long-term retention:
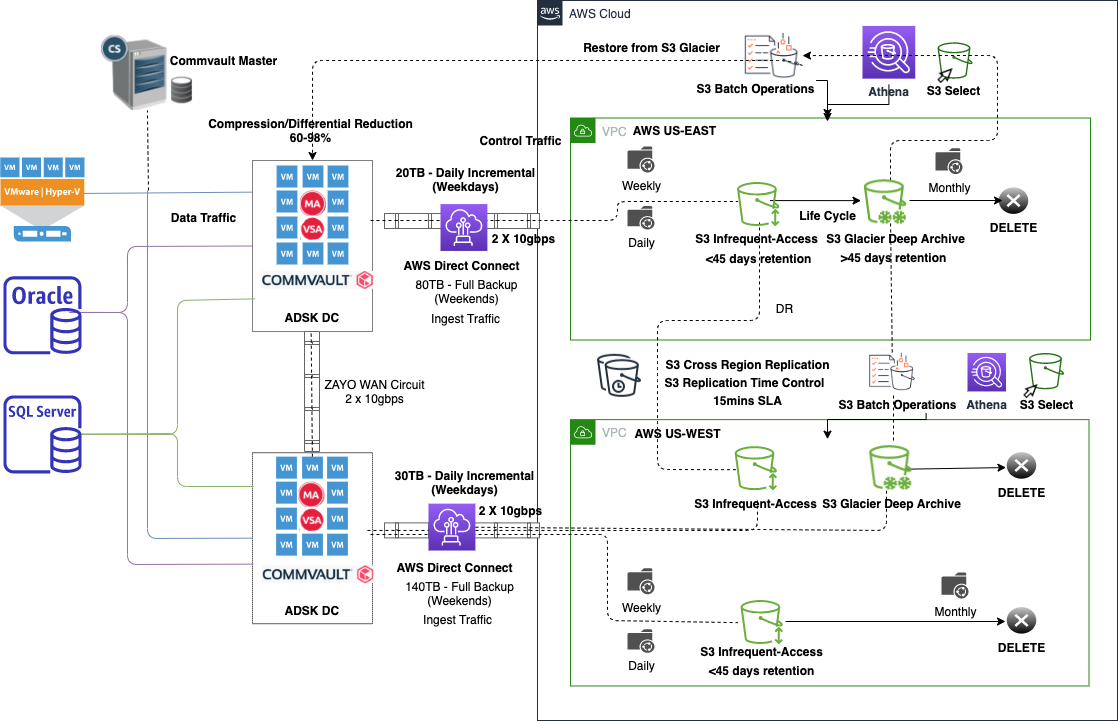
Our journey starts where we have over a petabyte of new data generated each week through Commvault Backup software, responsible for protecting our mission critical VM, database, and NAS workloads. The data generated is directly uploaded to Amazon S3 using AWS Direct Connect to the US West (Oregon) Region or US East (Northern Virginia) Region respectively. This data is compressed using Commvault Software and is written directly to the Amazon S3 Standard-Infrequent Access (S3 Standard-IA) storage class on a daily basis for incremental backups, in addition to weekly for full backups. S3 Standard-IA is for data that is accessed less frequently, but requires rapid access when needed. S3 Standard-IA offered us the high durability, high throughput, and low latency of S3 Standard, with a low per GB storage price and per GB retrieval fee. This combination of low cost and high performance makes S3 Standard-IA ideal for long-term storage, backups, and as a data store for DR files. Autodesk decided to use S3 Standard-IA directly for these data backups based on an analysis of our access patterns. As less than 10% of this data is read regularly, it made sense for us to achieve the savings of S3 Standard-IA right away rather than transitioning the data from S3 Standard later. Typically, when your objects are accessed once per month or less on average, S3 Standard-IA is a cost-effective choice.
Once the data lands in Amazon S3, Autodesk uses Amazon S3 Replication to automatically replicate the data to its counterpart bucket in the US East (Northern Virginia) Region or US West (Oregon) Region. We love that S3 Replication is fully automated and requires no additional effort on our part after the initial setup. Additionally, S3 RTC provides an SLA-backed replication time of 15 minutes or less with metrics and events to monitor its performance. Activating S3 RTC was simply a no-brainer for us because of the importance of this data and the need to have a second copy redundantly stored as soon as possible. With our setup, the ability to restore data from either AWS Region to any of our local data centers is key to meeting our internal benchmarks for reliability and redundancy in the event of a DR scenario. Turning on S3 RTC allowed us to reduce our effective RPO to 15 minutes for these backups once written to S3, a vast improvement over our prior 24-hour on-premises setup.
S3 Standard-IA provides cost effective storage for our backup data and then we transition data to S3 Glacier Deep Archive for longer term retention. S3 Glacier Deep Archive is Amazon S3’s lowest-cost storage class and supports long-term retention for data that may be accessed once or twice in a year. With a price point that is less than 1/10th the price of S3 Standard-IA, S3 Glacier Deep Archive gives us an incredibly low cost for storing our coldest backup data. Autodesk set up S3 Lifecycle policies that moves data to S3 Glacier Deep Archive based on the data properties. Some of the data is moved shortly after 30 days, and other data remains in S3 Standard-IA longer so that Autodesk’s backup software can manage the retention of aged copies. In the next section, we talk through the process Autodesk built out to identify and restore data from S3 Glacier Deep Archive, a key reason why Autodesk has been able to leverage it so extensively.
Restoring data at scale with S3 Batch Operations
With our data backups securely and reliably stored in Amazon S3, much of the work is already done. However, there are always cases that arise where backups must be recovered and brought back to our data centers. These reasons include accidental data deletions, data corruptions, data validations for compliance reasons, etc. Before having our backup data in AWS, this process involved storing the data in tapes and offsite tape vaults, where the access to our data was manual and difficult. Now, with our data stored in S3 Standard-IA and S3 Glacier Deep Archive storage classes, the whole process is much simpler.
When data backups are needed within approximately the first month of moving to Amazon S3, Autodesk can read the data directly from S3 using its Commvault software. As S3 Standard-IA offers read latency on the order of milliseconds, this occurs rapidly. We estimate that about 10% of Autodesk’s backups are restored from S3 Standard-IA.
However, when backup data must be accessed after several months, the data is first restored from S3 Glacier Deep Archive before reading it from our on-premises systems. As these backups can be comprised of thousands or millions of files each, we needed a scalable solution to initiate restoring this data, with the goal of removing manual steps and operational load wherever possible. To do so, we are leveraging S3 Batch Operations, S3 Inventory, and S3 Select. Together, these radically simplify the work of discovering, filtering, and restoring objects stored in S3 Glacier Deep Archive.
First, we maintain an S3 Inventory report of our bucket to ensure we have the latest list of objects in our bucket. Next, when a restore is needed, we use S3 Select to scan the S3 Inventory data files to find all the objects stored in our bucket that match the Commvault media ID/Barcode we are looking for. The following is an example of an S3 Select query that searches through an S3 Inventory file to find all the media objects that are required to restore data.
select s._1, s._2 from s3object s where s._2 like ‘%V_4308217%’ OR s._2 like ‘%V_4320539%’
Once we have the list of objects associated with a particular backup we must restore, we compile that list and save it to Amazon S3 as a manifest file for our S3 Batch Operations job. S3 Batch Operations is a managed solution that removes the need for us to manage and monitor thousands, millions, or billions of API calls. It offers a number of different operation types, including Amazon S3 Glacier restore, manages retries automatically, displays progress, and delivers a report showing the status of all operations. Once we have our manifest file prepared, it is simple to create the S3 Batch Operations job to restore all the applicable objects. At that point, we simply monitor the job’s progress. Once all the objects are restored, the last step is for our data center to retrieve the data from AWS. S3 Inventory, S3 Select, and S3 Batch Operations are simple to use, can be run through the AWS Management Console, and can manage work at the scale of millions or billions of objects. By using these features, we are saving approximately 40+ hours of time for each restore. S3 Select and S3 Batch Operations were critical in helping us make the case for moving these backups to AWS, as the time savings and convenience are hard to match.
Benefits of moving to AWS
Here are just a few of the benefits we wanted to highlight from our move to AWS:
- Environment stability
- High availability and durability with Amazon S3 storage.
- Minimal operational overhead with managed services and automation.
- Amazon S3 Replication and S3 Replication Time Control helped to reduce our DR SLA from 24 hours to 15 minutes.
- Cost savings and avoidance
- Transformed Capex to Opex cost model with consumption-based pricing.
- Avoided recurring operational expenses and subsequent operational overhead in data centers.
- Avoided recurring tech refresh investments every cycle.
- Divestment and footprint reduction.
- Decommissioned four storage vendors
- Reclaimed nine physical racks of data center footprint.
- Corporate sustainability
- Eliminated 468,000KwH of power consumption every year.
- Thereby avoided Co2 emissions of 500,000 lbs every year.
Conclusion
In this post, we reviewed Autodesk’s backup and recovery workflow leveraging Amazon S3 and Amazon S3 Glacier. We covered a step-by-step overview of their data ingestion pipeline from origination to cloud storage and an explanation of how Autodesk recovers backup copies of their data. Amazon S3 storage classes and features included in this blog post were S3 Standard – Infrequent Access, S3 Glacier Deep Archive, S3 Batch Operations, S3 Replication, S3 Replication Time Control, S3 Lifecycle Management, S3 Inventory, and S3 Select.
Thanks for reading this blog post. If you have any comments or questions, feel free to share them in the comment section.