AWS Storage Blog
Considering four different replication options for data in Amazon S3
UPDATE (2/10/2022): Amazon S3 Batch Replication, which is not covered in this blog post, launched on 2/8/2022, allowing you to replicate existing S3 objects and synchronize your S3 buckets. See the S3 User Guide for additional details.
UPDATE (5/1/2023): Updated the comparison table to reflect the latest capabilities of the mechanisms covered in the table.
NOTE (1/17/2025): Amazon S3 Batch Operations can copy all object versions, current and non-current, but will only copy the latest version if no ID is specified.
As your business grows and accumulates more data over time, you may need to replicate data from one system to another, perhaps because of company security regulations or compliance requirements, or even to improve data accessibility. When replicating data, you will want a secure, cost effective, and efficient method of migrating your dataset to it’s new storage location. Depending on your situation and requirements, like whether metadata should be retained or whether large files should be replicated, some options for replication may be more effective than others. Determining which replication option to use based on your requirements and the data you are trying to replicate is a critical first step toward successful replication.
With AWS, customers can perform large-scale replication jobs with a few clicks via the AWS Management Console or AWS Command Line Interface (AWS CLI). There are a few options for replicating data catering to customers with different needs.
In this blog post, we assess replication options through the lens of a fictional customer scenario in which the customer considers four different options: AWS DataSync, S3 Replication, S3 Batch Operations Copy, and the S3 CopyObject API. Through this assessment, we break down the advantages and limitations of each option, giving you the insight you need to make your replication decisions and carry out a successful replication that can help you meet your requirements.
Customer scenario
For the purposes of this blog post, consider a fictional example dealing with an entity known as the Bank of Siri (BOS). BOS is a multinational independent investment bank and financial services company. After 5 years, BOS discontinued one of its services, leaving 900 Petabytes of unused and legacy data in S3 Standard. This bucket contained 3 billion objects, and due to company security regulations, the data cannot be deleted, but can only be moved within the same AWS Region. BOS wants to migrate the data to a cheaper storage class to take advantage of its lower pricing benefits.
Capability comparison table
The capability comparison table gives a summary of Amazon S3 mechanisms discussed in this blog in terms of key capabilities.
- + = Supports capability
- – = Unsupported capability
- KMS = Key management service
- (SSE-S3) = Server-side encryption with Amazon S3-managed keys
- (SSE-C) = Server-side encryption with customer-provided encryption keys
- (SSE-KMS) = Server-side encryption with AWS KMS
| Capabilities | AWS DataSync | S3 Batch Operations Copy | S3 CopyObject API | S3 Replication |
| Modify destination object ownership and permission (ACLs) | – | + | + | + |
| Copy user metadata on destination object (metadata varies) | + | + | + | + |
| Copy objects > 5 GB | + | – | – | + |
| Preserve the last-modified system metadata property from the source object | – | – | – | + |
| Copy tags from source bucket | + | + | + | + |
| Specify S3 storage class for destination object | + | + | + | + |
| Copy latest version or all versions | Latest | Latest |
Latest by default Prior via a-amz-copy-source |
All by default Use manifest to select versions |
| Source object encryption support | SSE-S3/SSE-KMS | SSE-S3/SSE-KMS | SSE-S3/SSE – KMS/SSE-C | SSE–S3/SSE- KMS |
| Destination objects encryption support | SSE-S3/SSE-KMS | SSE-S3/SSE-KMS | SSE-S3/SSE-KMS/ SSE-C | SSE–S3/SSE-KMS |
Note: AWS DataSync preserves source file system metadata during replication. When a source file system is replicated to Amazon S3, that metadata is stored in S3 user-metadata. If that data is replicated back to a file system later, that user-metadata is used to set the target file system’s metadata. DataSync does not preserve the S3 system metadata last modified when replicating from S3 to S3.
AWS DataSync: Moving data between AWS storage services
Our first method is AWS DataSync. AWS DataSync is a migration service that makes it easy for you to automate moving data from on-premise storage to AWS storage services including Amazon Simple Storage Service (Amazon S3) buckets, Amazon Elastic File System (Amazon EFS) file systems, Amazon FSx for Windows File Server file systems, and Amazon FSx for Lustre file systems. DataSync migrates object data greater than 5 GB by breaking the object into smaller parts and then migrating the object to the destination as a single unit.

Figure 1: How AWS DataSync works between AWS Storage services
Benefits/Advantages
- Fully managed service: DataSync is a managed services so that you don’t have to maintain the underlying hardware or infrastructure.
- Metadata preservation: DataSync keeps the integrity of your file system metadata and your permissions when data is copied between storage systems. This is beneficial for applications dependent on such metadata.
- Monitoring and auditing: DataSync provides you the ability to view migration progress as well as data about a past migration using Amazon CloudWatch.
- Security: Data consistency between your source and destination is encrypted in transit.
- Efficient and Fast: DataSync uses multi-threaded architecture to ensure a quick migration between on premises and AWS connections.
Limitations
- Task limit: The maximum number of tasks you can create in an account is 100 per AWS Region. Quota can be increased.
- Objects per task: DataSync allows you to transfer 50 million objects per task. For tasks that transfer more than 20 million files, make sure you allocate a minimum of 64 GB of RAM.
- AWS storage services transferring: The maximum number of files per task between AWS storage services is 25 million. Quota can be increased.
- Encryption: Objects encrypted with AWS server-side encryption with customer-provided encryption keys (SSE-C) will not be transferred.
S3 Replication
Our second method is Amazon S3 Replication. Amazon S3 Replication automatically and asynchronously duplicates objects and their respective metadata and tags from a source bucket to one or more destination buckets. S3 Replication requires versioning to be enabled on both the source and destination buckets. You can replicate objects to destination buckets in the same or different accounts, within or across Regions. S3 Replication is the only method that preserves the last-modified system metadata property from the source object to the destination object. In relationship to our use case, BOS will use this method to replicate all 900 Petabytes of data into a more cost effective S3 storage class such as glacier deep archive. Below are the advantages of using S3 Replicate to solve BOS challenge.
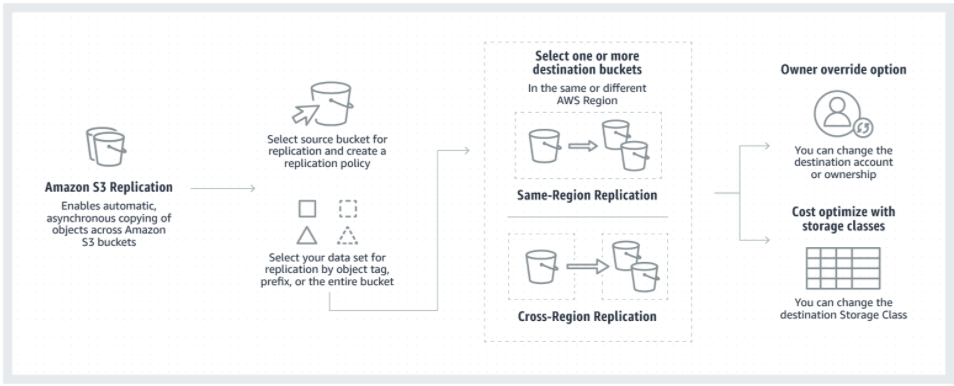
Figure 2: How Amazon S3 Replication works
Benefits/Advantages
- Retain metadata: Use replication to make copies of your objects that retain all metadata, such as the original object creation time and version ID.
- Keep objects stored over multiple AWS Regions: You can set multiple destination buckets across different AWS Regions to ensure geographic differences in where your data is kept. This could be useful in meeting certain compliance requirements.
- Minimize latency: If you are operating in two different Regions, you can minimize latency in accessing objects by maintaining object copies in AWS Regions that are geographically closer to your user.
- Maintain object copies under different ownership: Regardless of who owns the source object, you can tell Amazon S3 to change replica ownership to the AWS account that owns the destination bucket.
- Increase operational efficiency: If you have compute clusters in two different AWS Regions that analyze the same set of objects, you might choose to maintain object copies in those Regions.
Limitations
- Mark replication: When replicating from a different Amazon Web Services account delete markers added to the source bucket are not replicated.
- Recursive replication: Objects that existed before you added the replication configuration to the bucket are not replicated. In other words, Amazon S3 doesn’t replicate objects retroactively.
- Limited replication: If you configure replication where bucket A is the source and bucket B is the destination, and add another replication configuration where bucket B is the source and bucket C is the destination, objects in bucket B that are replicas of objects in bucket A are not replicated to bucket C.
- Unsupported SSE-C: Objects created with server-side encryption using customer-provided encryption keys (SSE-C) will not be replicated.
- S3 Glacier storage classes: Objects that are stored in S3 Glacier or S3 Glacier Deep Archive storage class will not be replicated.
Now, let’s add a unique twist to this use case. BOS wants to re-commission the service and need only the current versioning of the objects moved to another bucket for active usage. S3 Replication replicates the entire bucket including previous object versions not just the current version so this method won’t best fit the use case. Let’s take a look at S3 Batch Operations and how it can help use solve this challenge.
Amazon S3 Batch Operations Copy
Our third method is Amazon S3 Batch Operations. BOS can use Amazon S3 Batch Operations to asynchronously copy up to billions of objects and exabytes of data between buckets in the same or different accounts, within or across Regions, based on a manifest file such as an S3 Inventory report. The manifest file allows precise, granular control over which objects to copy. S3 Batch Operations supports all CopyObject API capabilities listed except for Server side-encryption with customer provided keys (SSE-C), making it a powerful and versatile tool that can scale to billions of objects. S3 Batch Operations tracks progress, sends notifications, and stores a detailed completion report of all actions, providing a fully managed, auditable, and serverless experience.

Figure 3. How Amazon S3 Batch Operations Copy works
Benefits/Advantages
- Bucket object listing: With the Inventory report, can configure to generate all objects in a bucket or focus on a prefix-delimited subset.
- Improve performance through multiple jobs: For the best performance, breaking the batch operation into multiple jobs is recommended as each job provides 900 TPS (transfer per second).
- Bulk object encryption: While tools and scripts exist to encrypt objects for you, each requires some development work to be set up. S3 Batch Operations automates the work for you and provides a straightforward way to encrypt objects in your bucket.
- Cross account data transferring: In S3 Batch Operations the customers can submit as many jobs as they like. These jobs can be defined by the type of operations such as Copy, Restore, and Replace Tag. When performing these jobs, a bucket on another account can be part of the destination.
Limitations
- Metadata preservation: When performing an S3 batch job Get API call, the requested data does not include all the source object’s metadata. Therefore, if the application is dependent on the metadata, this can be an issue as new metadata is generated.
- Unsupported KMS Encrypted: S3 Batch Operations does not support CSV manifest files that are AWS key management service encrypted.
- Inventory report time flexibility: Inventory report containing all objects in the buckets takes up to 48 hours to generate regardless of the size of the bucket.
- Static inventory report: Once the report is generated, modification to the report is not dynamically possible. In order to make modification, you will need to either manually modify the report, or run SQL queries, upload the new report, and run a new batch Job.
- Lambda: S3 Batch Operations currently supports only up to 1000 concurrent Lambda functions regardless of the Lambda concurrency limit set by the customer.
- Object limit size: S3 Batch Operations only supports objects less than 5 GB in sizes. For objects greater than 5 GBs, multipart uploaded is required.
Let’s add the last twist to the use case. After generating and carefully examining the S3 inventory report, BOS discovered that some objects are greater than 5 GB. S3 Batch Operations has an object size limitation of 5 GB. Therefore, some objects will fail to migrate. Let’s look at our next method.
S3 CopyObject API and s3api copy-object command
The last method we discuss is the AWS CLI s3api copy-object command. The S3apicopy-object command provides a CLI wrapper for the CopyObject API, with the same options and limitations, for use on the command line or in shell scripts. The Amazon S3 CopyObject API offers the greatest degree of control over the destination object properties.
Benefits/Advantages
- Tags modification: Allows you to set new tags and values on destination objects.
- Object locking: Configure object locking on destination objects.
- Encryption: Specify whether to use an S3 Bucket Key for SSE-KMS encryption.
Limitations
- Bucket policy: The bucket policies have to be less than 20 kilobytes.
- Maximum object size: The Max size is 5 GB per object.
- Max HTTP PUT request size: The Max size is 5 GB.
Your applications can call the S3 CopyObject API via any of the AWS language-specific SDKs or directly as a REST API call to copy objects within or between buckets in the same or different accounts, within or across regions.
Conclusion
We discussed how AWS helped solve a unique business challenge by comparing and explaining the capabilities and limitations of 4 data transfer/replication methods. AWS provides several ways to replicate datasets in Amazon S3, supporting a wide variety of features and services such AWS DataSync, S3 Replication, Amazon S3 Batch Operations and S3 CopyObject API. DataSync is an online data migration service that accelerates, automates, and simplifies copying large amounts of data to and from AWS Storage services. Amazon S3 Replication automatically and asynchronously duplicates objects and their respective metadata and tags from a source bucket to one or more destination buckets. S3 Batch Operations is an S3 data management feature within Amazon S3 and is a managed solution that gives the ability to perform actions like copying and tagging objects at scale in the AWS Management Console or with a single API request. Lastly, Amazon S3 CopyObject API allows you to replicate an object that is already stored in S3 via CLI while providing the ability to modify tags and lock destination objects.
Thanks for reading this blog post on the different methods to replicate data in Amazon S3. If you have any comments or questions, leave them in the comments section.