AWS Storage Blog
How Qubole optimizes cost and performance by managing shuffle data
Ad hoc analytics, data exploration, data engineering, and machine learning (ML) workloads are often run at a massive scale and require significant computing power, which can be costly. Amazon EC2 Spot Instances, which enable you to use unused Amazon EC2 computing capacity in the AWS Cloud, offer up to 90% in savings over On-Demand Instances. With their incredible savings potential, EC2 Spot Instances are effective for many workloads. However, EC2 Spot Instances (spare capacity) can go away as demand for Amazon EC2 increases, so data that is being processed may be left stranded. That data may need to be “shuffled” to other Amazon EC2 instances to continue processing. Providing a mechanism to offload and eventually access this data in a high-performance shared file system helps reduce costs and improve performance.
In this post, we cover how Qubole solved many of the common challenges associated with managing shuffle data by using Amazon FSx for Lustre (FSx for Lustre). Qubole is a simple, open, and secure data lake platform for machine learning, streaming, and ad hoc analytics built on AWS Cloud infrastructure. By using FSx for Lustre, Qubole reduced re-computation costs, improved performance, and reduced overall job completion time.
Overview
An APN Advanced Technology Partner, Qubole enables large and small customers to leverage the benefits of cloud computing, such as elasticity, scale, and cost. Qubole facilitates this by managing customer workloads and automating data pipelines for machine learning, data engineering, ad hoc analytics, and streaming analytics.
Customers leveraging Qubole’s open data dake platform configure big data analytics workloads via a workbench setup, which in turn deploys jobs on the customer’s Amazon Virtual Private Cloud (Amazon VPC). The platform environment includes features such as automated cluster lifecycle management, workload-aware autoscaling, and intelligent spot management on AWS. The platform supports multiple engines such as Spark, Hive and Presto with high-quality debugging and user experience. Qubole’s open data lake platform running on the AWS Cloud, with the preceding characteristics, is depicted in the following diagram (Figure 1):
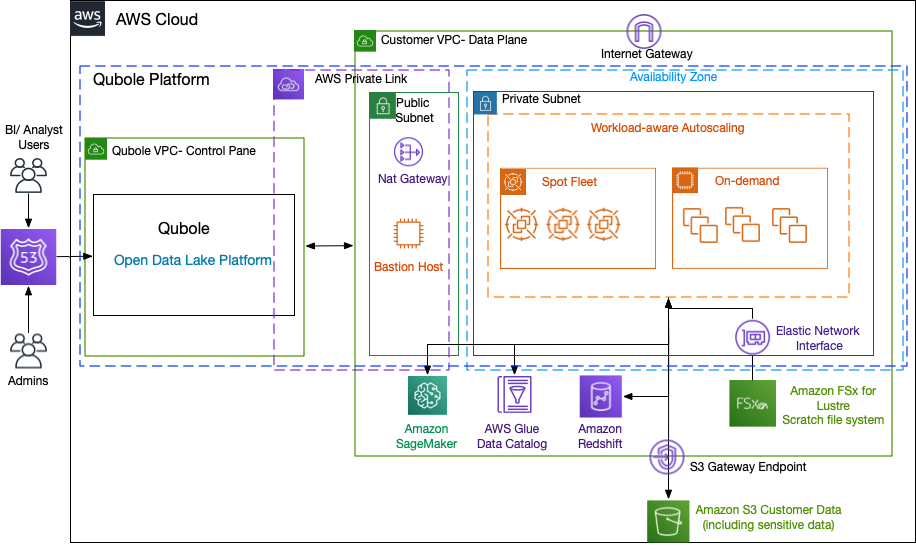
Figure 1: Qubole open data lake platform on AWS Cloud
Challenges of using local storage for shuffle data
Ad hoc, machine learning, and data engineering workloads on distributed processing engines generate “state,” or intermediate data known as “shuffle data” as a part of the Directed Acyclic Graph (DAG). Local disks or block storage such as Amazon EBS can persist this temporary output required by subsequent tasks for further processing. This phenomenon of storing temporary data in ephemeral storage or EBS volumes creates a tight coupling of shuffle data with compute (EC2). This tight coupling results in the following issues:
- Time-consuming re-computation: When an EC2 Spot Instance interruption occurs, it leads to shuffle data unavailability causing stage re-computation in a workload. This results in slower execution and additional cost
- Inefficient spend: Qubole’s workload-aware autoscaling downscales EC2 instances by shutting down nodes whenever they are no longer required thereby saving cost. In some scenarios, instances that store shuffle data are prevented from termination resulting in an inefficient spend.
Stateless machines powered by Qubole and FSx for Lustre
To best deal with shuffle data, Qubole now integrates with FSx for Lustre. In addition to its workload-aware autoscaling benefits, FSx for Lustre enables the platform to decouple the ‘state’ from the ‘machine’ and provides a place to store the shuffle data.
FSx for Lustre is a high-performance parallel file system that provides sub millisecond latencies, up to hundreds of gigabytes per second of throughput, and millions of IOPS. FSx for Lustre enables users to define striping. Striping can be configured across multiple objects storage targets (OSTs) to spread read and write requests across those OSTs, thereby increasing aggregate throughput and IOPS. Along with striping, next-generation high network bandwidth EC2 instance and optimal sizing of an FSx for Lustre file system, enabled Qubole to achieve similar performance to local disks. Qubole also noticed the following benefits by offloading shuffle data to FSx for Lustre:
1. Cost reduction
- Aggressive downscaling: Amazon EC2 instances that generate shuffle data are known as producer nodes. The data generated by these nodes is written to FSx for Lustre instead of local disk. EC2 instances that consume this data, would read the shuffle data directly from FSx for Lustre. Once the tasks on these nodes are completed, nodes can be terminated. Qubole’s aggressive downscaling terminates these EC2 instances immediately thereby providing cost savings.
- Higher storage utilization due to statistical multiplexing: Customers also save on Amazon EBS costs by leveraging FSx for Lustre as a shared storage. For example, consider if the maximum expected shuffle data per EC2 instance was 200 GB, and the cluster was running with 100 such instances. That would require 20 TB of EBS storage (200 GB per node x 100 nodes). However, not all the tasks on all the nodes would write 200 GB at the same time, as they might in different stages of an analytics workload. With FSx for Lustre, only a fraction of that 20-TB storage is required for the entire cluster, resulting in improved storage utilization lower costs.
2. Spot interruption tolerance: As previously mentioned, shuffle data generated by an earlier stage of the DAG would be required in the later stage of the DAG. Storing the shuffle data in a shared file system such as FSx for Lustre avoids shuffle data re-computation when the node is interrupted and recalled. This decoupling makes the data available to later stages of the DAG, irrespective of Spot Instance interruption, thereby eliminating expensive and time-consuming re-computation.
In the next section, let’s look at how the tests were performed to reach the preceding conclusions:
Testing
To understand the impact of Amazon EC2 Spot Instance interruption and the benefits of FSx for Lustre integration, Qubole conducted a series of experiments. These experiments simulated the worst- and best-case scenarios with EC2 Spot Instance interruption.
Experiment setup
These are the specifications for the workload used in the experiment:
Qubole version: R59
TCP-DS scale: 1000
Hive version: 2.3.6
Tez version: 0.8.4
FSx for Lustre file system: 1.2 TB
Workload profile
Qubole conducted these experiments using the industry-standard benchmark TPC-DS query20.sql. This command reads data from three different tables and processes them across mapper and reducer stages. The command is broken into a total of 7 stages (Map 1–3 and Reducer 1–4) as shown in the query plan in Figure 2, and total time taken for query completion (without Spot Instance interruption) is 8 minutes.

Figure: 2 Query plan for TPC-DS query20.sql
Without FSx for Lustre
To understand the impact on the query execution time and cost, Qubole terminated compute instance #1 right before stage 7 execution began, as shown in Figure 3. This stimulated an Amazon EC2 Spot Instance interruption scenario. This instance (instance #1) stores output data from each of the stages 1–6. As a result, recomputation of the entire job is required to generate the data that is needed by stage 7 as shown in Figure 3. This takes an additional 16 minutes.

Figure 3: Each of the instances store a part of the output from all of the stages
With FSx for Lustre
At Qubole, FSx for Lustre is used as a shared file system, and the shuffle data is backed up. As a result, when Spot Instance interruption occurs, stage 7 checks for output data from stage 6 and if not available, directly reads from FSx for Lustre as shown in Figure 4. This process eliminates the need to recompute the data. This saves about 16 minutes of execution time, and only takes an additional (and negligible) 500 milliseconds to fall back and fetch output data from FSx for Lustre.

Figure 4: Reading shuffle data from FSx for Lustre
Results
Avoiding re-computation processes reduces the time taken for query completion, which in turn results in cost avoidance. Observations from multiple tests yielded similar results of 3x performance gains and 68% cost avoidance as shown in the following Figure 5.

Figure 5: Comparison of performance improvements
Summary
Qubole’s customers on AWS can now leverage Amazon FSx for Lustre and Qubole’s open data lake platform together to reduce their compute cost and minimize shuffle data re-computation. They do not have to pay to maintain idle EC2 instances or underutilized EBS volumes, and do not have to worry about shuffle data re-computation due to Spot Instance interruption. Instead, Qubole now uses FSx for Lustre to store and process shuffle data using its parallel, high-performance file system, avoiding up to 68% in cost and improving performance by 3x. These benefits derived from using FSx for Lustre enable Qubole and AWS customers to budget and save (time and money) more effectively – further facilitating innovation and improvement of the customer experience.
Thanks for reading this blog post and learning more about how APN Partner Qubole uses Amazon FSx for Lustre to improve its compute performance and save costs. If you have any questions or comments, please don’t hesitate to leave them in the comment section.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.