AWS Storage Blog
How TMAP Mobility transferred 2.4 PB of Hadoop data using AWS DataSync
Launched in 2002, TMAP Mobility is Korea’s leading mobility platform, with 20 million registered users and 14 million monthly active users. TMAP provides navigation services based on a wide range of real-time traffic information and data. Previously, the Data Intelligence group at TMAP Mobility operated a mobility-data platform based on a Hadoop Distributed File System (HDFS) in their data center to provide analytics services to other departments that require processed data. After learning about Amazon EMR, TMAP Mobility was impressed by how easy it was to manage Hadoop systems on AWS, so they decided to migrate data to AWS.
In this blog post, we explain how TMAP Mobility migrated on-premises Hadoop data to Amazon S3 using AWS DataSync, allowing them to easily manage data movement and transfers for timely in-cloud processing.
Customer challenge
TMAP Mobility needed to transfer 2.4 PB of on-premises Cloudera HDFS to Amazon S3 in 2 months to launch their data lake project, which was running on their existing mobility data platform. The new data lake project would leverage real-time and batch processing with an AWS managed services–based analytics pipeline.
Members of the Data Intelligence group consisted of data and machine learning engineers, and they needed to find a migration way that they could independently configure and manage in order to meet the tight deadline of the project launch while not disrupting the existing service or causing downtime to the Hadoop cluster during the migration.
In addition, they needed to perform the initial copy and incremental changes so as not to disrupt service or cause any downtime during their migration.
Solution overview
Before the data migration, TMAP had to choose a migration method that considered the pros and cons of both online and offline migration. After choosing a migration method, the customer configured AWS DataSync and performed the migration. It took only about 2 months, performed by two developers who did not have much experience with AWS DataSync.
- Choosing a migration method
- Configuring AWS DataSync
- Create Location
- Create task
- Transfer incremental data
- Creating external table schema

Figure 1: HDFS migration architecture with AWS DataSync
1. Choosing a migration method
TMAP Mobility was storing about 7.2 PB data on HDFS, including three replication copies, but the team didn’t know which was the fastest and easiest option to choose for the transfer. AWS provides multiple data transfer and migration options, with AWS DataSync and the AWS Snow Family being the best for large data migrations. AWS DataSync is ideal for online data transfers, and AWS Snowball Edge is ideal for offline data transfers. To choose between AWS DataSync or AWS Snowball Edge for data transfer, the user should consider the amount of data to be transferred and the network bandwidth available for the data transfer. The table below provides estimated transfer times for different use cases for large file (>10 MB) transfers, and the recommended service for each use case.

Figure 2: Migration method of AWS
In TMAP’s case, they already had 10 Gbps AWS Direct Connect, and they were not used to working with physical devices since most team members were developers focusing on service planning and application development. At first, they considered open-source migration tools such as DistCp and HDFS-FUSE, which are commonly used to transfer data to Amazon S3. However, while DistCP or HDFS-FUSE support single-thread transfer or need to develop a customized script, DataSync uses a parallel, multithreaded architecture to accelerate data transfer. So, they ultimately chose AWS DataSync as their migration method. With DataSync, TMAP Mobility was able to easily migrate their data to the cloud without handling any physical device or tweaking any configuration. The entire migration process followed the well-written guide on the AWS Storage Blog, Using AWS DataSync to move data from Hadoop to Amazon S3.
2. Configuring AWS DataSync
TMAP started off by installing a DataSync agent. The DataSync agent supports installation on VMware ESXi Hypervisor, Microsoft Hyper-V Hypervisor, Linux Kernel-based Virtual Machine (KVM), and Amazon Elastic Compute Cloud (Amazon EC2) instance. As TMAP’s data center was VMware infrastructure, they deployed two DataSync agents on ESXi Hypervisor. Among two agents, only one agent and one task were used to transfer, while another agent was ready as a backup. Agent spec was 16 VCPU, 32GB RAM, and 80 GB disk. For larger transfers of over 20 million files, a 64 GB agent is required. For more detailed VM specifications, you can refer to the agent requirement document.
After installing the agent, an activating agent was needed. In order to activate the agent and secure the connection between an agent and the DataSync service, several network ports should be opened by the firewall. Since TMAP Mobility’s Hadoop network was inside the on-premises firewall, TMAP opened the outbound traffic (TCP ports 1024–1064) from the DataSync agent to the VPC endpoint. They also had to open the TCP 443 port for the entire subnet where the VPC endpoint is located because dynamic IP is assigned to ENI for data transmission of DataSync. For more detailed network requirements, you can refer to the network requirement document.

Figure 3: AWS DataSync Network Requirements
Create location
After creating an agent, configuring DataSync Task was needed. The first step was to set a location for HDFS as the source location and Amazon S3 as the destination location. Location in DataSync is a storage system or service that DataSync reads from or writes to. In order for the agent to access HDFS, Hadoop NameNode’s RPC port should be opened; its default port is 8020. Another configuration for HDFS was to set the authentication type. DataSync supports two types of authentication: simple authentication and Kerberos authentication. TMAP used simple authentication, which is to use username-based authentication. Block size was set at 128 MB following the default value, and the replication factor was set to 3 because on-premises HDFS was 3-way replication architecture.

Figure 4: Source location for HDFS of DataSync task
Amazon S3 was the destination location, and it was easy to configure. Just setting the bucket and path was enough, but one notable thing was to use Intelligent-Tiering as the Amazon S3 storage class to store data cost efficiently.
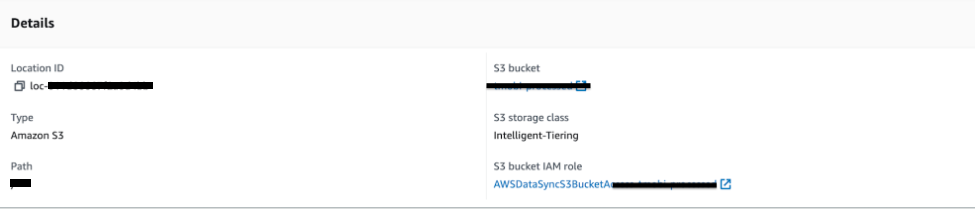
Figure 5: Destination location for Amazon S3 of AWS DataSync task
Create task
As mentioned earlier, HDFS data size was 7.2 PB, including three replications, but origin data size, without replication, was 2.4 PB. So, the necessary transferring data was 2.4PB. When executing their task, the result showed full performance, consuming all 10 Gbps of their bandwidth. However, at full performance, the migration disrupted the production workload, so TMAP had to control the network traffic and limit the usage by data transfer. Fortunately, DataSync provides bandwidth control options, which TMAP used to configure a bandwidth limit for DataSync tasks. TMAP fixed their bandwidth limit to 400 MiB/s for single task, resulting in a total use of 400 MiB/s out of 10 Gbps, preventing from consuming whole bandwidth. Additionally, TMAP set a 4 Gbps bandwidth limit on the VMWare host to ensure bandwidth throttling.

Figure 6: Bandwidth limit of DataSync Task
Transfer incremental data
Migration time took 2 months, so TMAP should adopt a full and incremental migration strategy to transfer data that was stored during ongoing migration. For incremental data migration, include and exclude filters were used appropriately to reduce transfer times.
In the case of giving DataSync the full path and running incremental migration every time, it would take too much preparation time for the data transfer and verification of 2.4 PB.
Fortunately, most of the large data was stored in a hierarchical structure of the /yyyy/mm/dd format in Hadoop, and only the most recent data could be copied with the filter option in the Filtering data transferred by AWS DataSync section in the documentation. As there were many paths to be copied, TMAP created a DataSync execution script using start_task_execution of boto3’s DataSync API to run the migration task easily.

Figure 7: Include patterns of DataSync task
3. Creating external table schema
After the migration was completed successfully, TMAP created an external table schema with Hive because the original schema on HDFS was also created and managed by Hive. Even though EMR is able to create schemas automatically when processing data, it was better to create a schema manually when the data size is huge, such as PB-size data.
java -jar /usr/share/aws/emr/command-runner/lib/command-runner.jar hive-script --run-hive-script --args -f s3://BUCKET/USERDATA/DATABASE.TABLE
alter table DATABASE.TABLE add if not exists partition(p_year='2020',p_reqdate='20200609',p_reqtime='11') LOCATION 's3://BUCKET/USERDATA/p_year=2020/p_reqdate=20200609/p_reqtime=11' ;
alter table DATABASE.TABLE add if not exists partition(p_year='2019',p_reqdate='20190808',p_reqtime='20') LOCATION 's3:// BUCKET/USERDATA/p_year=2019/p_reqdate=20190808/p_reqtime=20' ;
alter table DATABASE.TABLE add if not exists partition(p_year='2020',p_reqdate='20201012',p_reqtime='04') LOCATION 's3:// BUCKET/USERDATA/p_year=2020/p_reqdate=20201012/p_reqtime=04' ;
alter table DATABASE.TABLE add if not exists partition(p_year='2019',p_reqdate='20190923',p_reqtime='08') LOCATION 's3:// BUCKET/USERDATA/p_year=2019/p_reqdate=20190923/p_reqtime=08' ;
alter table DATABASE.TABLE add if not exists partition(p_year='2019',p_reqdate='20190715',p_reqtime='04') LOCATION 's3:// BUCKET/USERDATA/p_year=2019/p_reqdate=20190715/p_reqtime=04' ;
alter table DATABASE.TABLE add if not exists partition(p_year='2019',p_reqdate='20190601',p_reqtime='15') LOCATION 's3:// BUCKET/USERDATA/p_year=2019/p_reqdate=20190601/p_reqtime=15' ;Figure 8: Creating table schema with Hive
When schema creation is completed, Glue can show a structured table with an Amazon S3 data source. For a more detailed configuration of sharing the metastore between Glue and Hive, refer to the Amazon EMR Documentation.
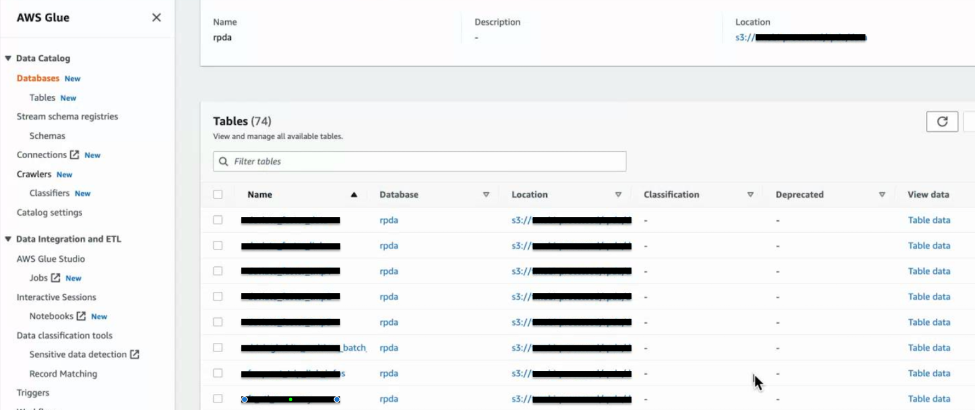
Figure 9: Tables in AWS Glue
Conclusion
In this post, we covered how TMAP Mobility Co., Ltd. used AWS DataSync to accomplish a cost effective, secure, and fast online petabyte-scale data transfer. With AWS DataSync, TMAP Mobility was made easily with native features around monitoring, encryption, data integrity validation, and native support for HDFS.
AWS DataSync enabled TMAP Mobility Co., Ltd. to meet their timeline for migrating their data into an Amazon S3 data lake, helping them support their mobile application with five million daily active users (DAU). TMAP used the data transferred to Amazon S3 with other AWS services, including Amazon EMR and Amazon Athena, among others, to provide data consumers with the ability to easily search data whenever they want and quickly analyze newly accumulated data through scaling of computing power.
| “With AWS DataSync, TMAP Mobility Co., Ltd. was quickly and reliably able to transfer PB scale Cloudera HDFS data within 2 months. AWS DataSync’s native support for HDFS helped us meet our tight project launching schedule.”
– Eun Hee Kim, Data Intelligence Group Leader, TMAP Mobility Co., Ltd. |