Amazon Supply Chain and Logistics
AWS Stock Depletion Engine to prevent waste of perishable products
Inventory management for perishable products is a challenge for many industries, such as food manufacturing, grocery wholesale and retail, and pharmaceuticals. For example, excess stock levels of dairy products, meats, fruits, vegetables, medicines, and even beer, to name a few, are all subject to expiration, “best before” dates, or important milestones in product lifecycle (e.g., a certain percentage of product lifetime) after which they do not sell through the usual channels with standard margins and are either sold using discounted channels or simply discarded from retail or storage shelves. Some other products, e.g. electronics, face similar issues from the product obsolescence and depreciation standpoints.
The obvious consequence of expired products is so-called “product shrink,” i.e., eventual liquidation or destruction. This may not only represent underachieved revenue, but also incremental costs for product destruction and material recycling. McKinsey & Company estimates typical product loss as 2–3% of grocers’ revenue and 5–15% in ready-to-eat revenues, which significantly deteriorates profits.
An additional implication of product waste is a negative impact on the sustainability metrics and upkeep of corporate citizenship responsibilities toward society. Common causes for product waste and write-offs include overestimating demand for more specific products, long lead times, not selling products in time, or seasonal, promotional, and special edition products that quickly become outdated once the customer loses interest. Product understocking, on the other hand, means missing out on existing customer demand, jeopardizing current market share, and not capitalizing on market opportunities. Hence, determining target inventory levels requires a trade-off between having too much inventory, with a risk of destroying some products, or having too little inventory and missing out on revenue.
This blog post provides an overview of Stock Depletion Engine based on mathematical optimization and machine learning (ML). Stock Depletion Engine is a solution that identifies products under expiration risk and provides inventory depletion recommendations to prevent product expiration.
Analytics-driven solution to prevent product waste
Typically, businesses have a number of different levers to pull for proactive inventory depletion. The most common decisions include price markdowns, marketing campaigns, inventory reallocation to higher demand or faster velocity locations, secondary packaging replacement (e.g., repackaging promo corrugate to standard packaging or the other way around), and returns to vendor.
However, in our experience, capturing these decisions and their resulting efficiency in a single standardized repository is not commonplace because of the complex nature of these decisions and the need for detailed outcome tracking. This is especially challenging if these decisions sit in different organizations, e.g., marketing and sales, logistics, and manufacturing.
The solution in this post focuses on two objectives: (1) implement an optimization-based version of the Stock Depletion Engine to start depleting inventory proactively and capture data on depletion efficiency; (2) when sufficient data becomes available, enrich Stock Depletion Engine with ML implementation of a multiclass, multilabel classification solution.
Optimization-based Stock Depletion Engine and Decision Efficiency Data
An optimization-based implementation starts with the existing demand forecasts, if they are of acceptable quality. If this is not the case, it is worth improving forecasting accuracy first and we previously demonstrated how forecasting alone can reduce product waste by 37% and costs by 22% for a retail customer.
The demand forecasts are recalculated (Function 1 on the diagram) to identify products under higher risk based on recent actual demand and recent product depletion quantities. If depletion has been significantly lower than initially forecasted, we adjust the demand for these products towards more realistic outflow numbers in the near future. The adjustment also needs to consider significant events in the near future, e.g. holiday periods for which recent demand and depletion observations may not apply.
In the next step, we compare the current product inventory levels vs. course-corrected demand until the product expiration date to assess if certain products face risks of not selling before they expire, i.e., stock surplus (Function 2 on the diagram). Similarly, we assess if the current stock level is likely not enough to cover short-term demand (e.g., using 98 percent probability forecast), i.e., a potential stock out. This becomes an input for a mathematical optimization solution that chooses the best decision for stocks under expiration risk (Function 3 on the diagram). This considers business constraints such as product relocation to a different sale destination, product repackaging into higher-demand products, or a combination of both. Naturally, these decisions have operational costs attached to them. Hence, the objective of the optimization solution is to minimize losses and maximize overall revenue simultaneously, i.e., maximizing the net present value (NPV) of the product.
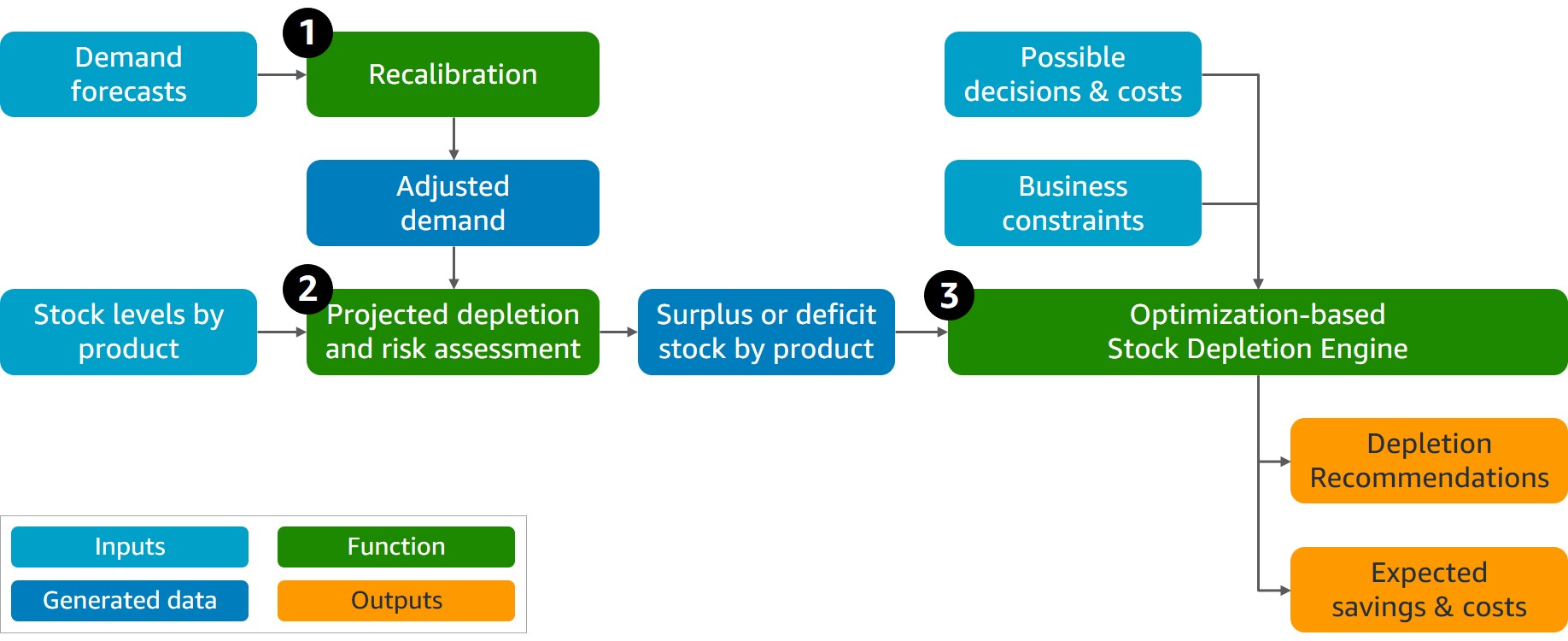
We tested our optimization-based Stock Depletion Engine using a sample of perishable beverages. We validated that our solution is capable of accurate risk estimations for potential product waste based on current stock and demand forecasts using first-in first-out (FIFO) depletion logic. In terms of depletion recommendation quality, 90 percent of recommendations were valid, with the remainder resulting from data quality. The business users complimented these as something they may not think about, or they simply may not have enough time for such holistic analysis of numerous items under risk and a wide range of possible mitigations. In terms of potential business benefits, extrapolating pilot outcomes to the whole business returns a six-digit monetary loss avoidance, which addresses up to 60 percent of the current business losses attributed to product expiration. On top of that, up to 30 percent of losses can be targeted by improving forecasting quality and inventory placement by expanding our solution to include these areas and make end-to-end planning and depletion decisions.
Machine learning addition
The optimization-based implementation includes a list of recommended decisions ranked by weighting loss minimization and revenue maximization. However, the top-ranked decision may not be the most efficient one as it does not consider business complexities and the likelihood of this decision succeeding. The ML addition to Stock Depletion Engine provides the probability of a decision’s efficiency, complementing the optimization solution and selecting the recommendation with the highest rate of success to avoid product expiration. A multi-class, multi-label ML classification solution predicts the probability of optimization-proposed decisions and provides the decision-maker with additional decision “tips and hints” derived from past experiences. The model performance depends on the available dataset, but greater than 1,000 historical decisions with known decision efficiency are needed for proper ML training.
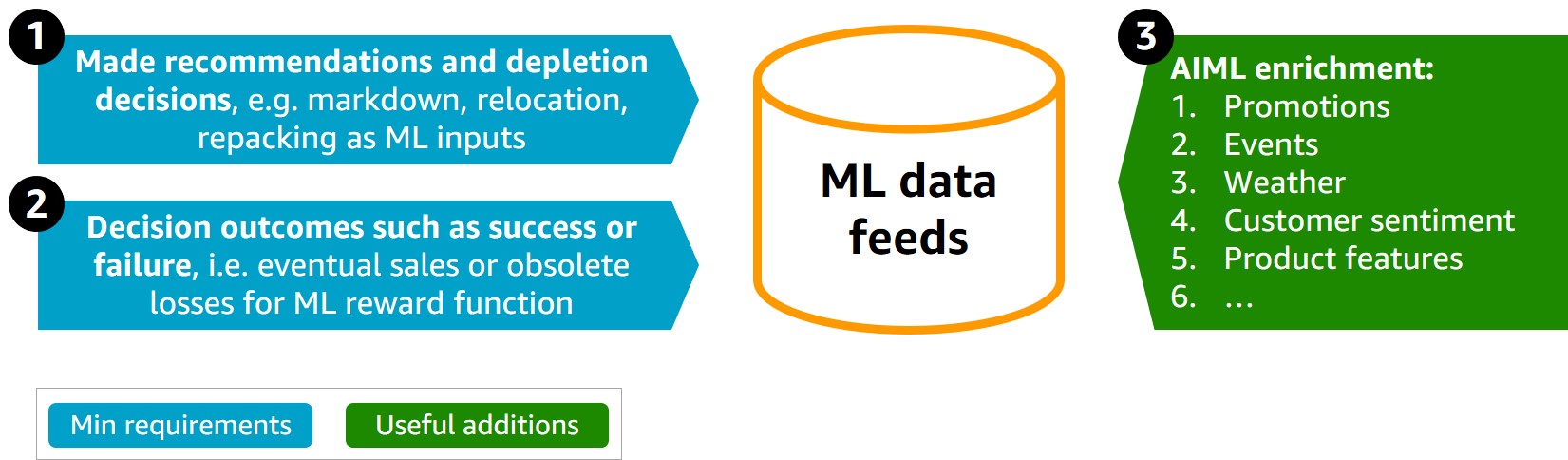
The benefits of an ML addition for product waste minimization include: (1) finding patterns for decision “success” and “failure” in large amounts of data, which is useful for future inventory decisions under similar circumstances; (2) ease of adding new datasets that improve quality of predictions, e.g., promotional events, weather, or customer sentiment; (3) the solution scales easily when the complexity of the decisions or constraints increase; and (4) ML provides decision recommendations for new products in the catalog, which may not yet have historical data. Amazon SageMaker is a fully managed ML service that best corresponds to the requirements of this solution. With SageMaker, data scientists and developers can quickly and easily build and train ML models and then directly deploy them into a production-ready hosted environment to start proactive inventory depletion.
Additional benefit of bringing ML into this solution is that it can also be used to optimize product pricing when markdowns is one of the production depletion levers. Previously we have shown how ML optimizes pricing and revenue for housing units and mobile data and similar approaches are applicable to perishable products.
Operational architecture
The following diagram outlines the high-level architecture recommended to operationalize Stock Depletion Engine using math optimization.
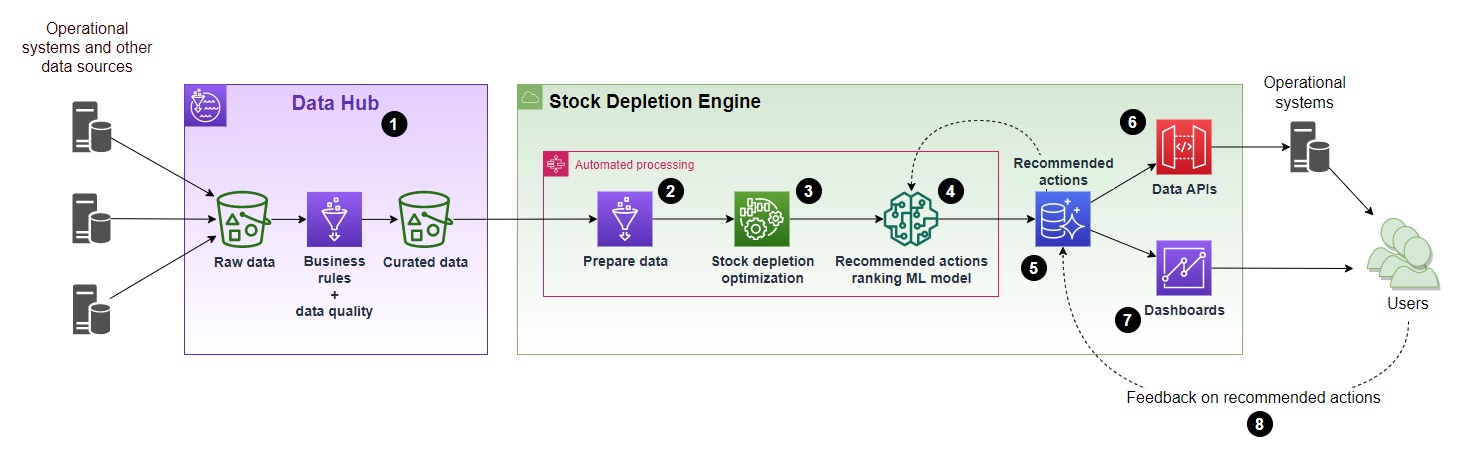
- The data required as an input into the Stock Depletion Engine needs to be collected from the operational and other systems and made available for the Stock Depletion Engine. In a large enterprise, this is typically implemented through a data-sharing platform such as a data lake, data mesh, lake house, or some other similar approach. A data mesh on AWS can be implemented using managed and serverless services such as AWS Glue, AWS Lake Formation, Amazon Athena, and Amazon Redshift Spectrum. For the Stock Depletion Engine, the following data is required as a starting point:
- current stock levels by product and batch, including their expiration dates;
- current demand, e.g., confirmed future orders and 12–14 past weeks (in case of expected seasonal variations and event-driven peaks and troughs, recent demand may be less relevant and such variations need to be properly represented in the forecast below);
- forecast of future demand, e.g., until product expiration or its important lifecycle milestone;
- a set of all possible action types to deplete inventory, e.g., price markdowns, product reallocation to alternative points of sale, product repacking or relabeling, etc., and costs associated with these decisions
- business rules and constraints, e.g., site capacities, oldest inventory depletes first, or minimum quantity for product relocation.
- Data from the operational systems and other sources is transformed into the format required by the optimization process. This includes integrating source datasets and additional feature engineering to provide all variables needed by the optimization algorithm.
- The main solution component, which is an optimization algorithm implementation.
- Ranking of the recommended actions using a ML model trained based on feedback provided by the business users on previous recommendations via the feedback loop (#8). It allows prioritization of operational recommendations, hence maximizing the probability of success of the optimization suggestions.
- Recommended actions and business user feedback are stored in a database. Amazon Aurora Serverless is a fit-for-purpose service to use here because it does not require any maintenance, is cost-efficient, and provides an easy-to-use backend for both data APIs and user dashboards.
- Data APIs enable integration with the operational systems, so the recommended actions can be provided to business users through applications they use as part of their day-to-day activities. The APIs also allow the capture of feedback on the recommendations from the users. The APIs are typically implemented using another highly scalable serverless service, AWS Lambda, and make them available for systems integration via Amazon API Gateway.
- The recommendations can also be provided to the business users via a bespoke dashboard together with summary KPIs and trends to measure the effectiveness of the optimization and adoption by the operations teams over time.
- Feedback on the recommended actions from the business users is captured through the operational systems and stored in the solution database. It serves as a continuous improvement loop where users provide their opinions using their business experience. For example, whether proposed recommendations will work or not in the current circumstances and why.
Implementation considerations
Implementation of a solution based on this architecture requires a combination of skills across data and application architecture, data engineering, operational research, machine learning, and data visualization. A critical success factor is close collaboration between SMEs from sales, planning, and operations with IT and data professionals implementing the solution. Depending on the number and complexity of the operational systems and the maturity of data management and data governance within the organization, a two-pizza team could implement such a solution within 3–6 months.
The largest risk to success of implementation is the availability and quality of the data. We recommend investing time at the beginning of the project to identify required data sources, profile data to assess its quality, and make informed decisions about data sourcing and preparation as well as the optimization algorithm based on the available data.
Another important aspect to consider is the ability of the operational teams to act on the optimization suggestions as part of their day-to-day activities. Involve them in the project from the beginning and decide together how best to enable them, e.g., by integrating the recommendations into the systems used by the operations teams, including providing feedback on the recommendations together with a reason why it may not be possible to act on a recommendation. This will inform the Stock Depletion Engine ranking ML model to prioritize actions most favorable from the operational point of view. Finally, the ultimate objective of the implementation needs to be a fully automated Stock Depletion Engine, which would allow in-stock managers to only manage this process by exception and focus on more value-added activities.
When planning implementation, consider how to scope the initial pilot in terms of product and geographical coverage and how to scale it after initial implementation. A best practice is to limit the initial scope to a set of products and locations. Such scope is likely to provide meaningful business benefits but is small enough to implement the end-to-end solution from both technical and operational viewpoints as soon as practically possible. This allows the team to learn by using the initial implementation in day-to-day operations of the company and by applying these learnings to refine the solution as part of scaling it out to include additional product lines and locations.
AWS technology enables such iterative solution building with purpose-built services, which natively support agile project practices and modular solution architecture. This allows implementation teams to quickly experiment, build, test, deploy, and incrementally evolve the solution over time, providing business benefits with each iteration. For example, AWS Sagemaker supports and helps structure machine learning experiments.
The architecture described in this section is flexible to include complementary use cases. For example, if a sales forecast is not readily available or not reliable, an additional component can be included in the solution to calculate or adjust the forecast based on historic data collected. For example, using AWS solutions to improve forecasting accuracy using ML. The revised forecast can then be used by the Stock Depletion Engine or for any other purposes.
Conclusion
Managing perishable inventory is a not straightforward task, especially with volatile customer demand, the need to constantly “reinvent” products with special editions and campaigns, and constantly growing retail assortments. In this post, we proposed a two-phased approach to develop Stock Depletion Engine using mathematical optimization and ML. Depending on the available data, the solution allows a kick-off of proactive depletion decisions and monitoring of their efficiency going forward. Our solution is applicable to various products and industries, e.g., food manufacturing, retail operations, and pharma distribution, allowing businesses to minimize avoidable product waste and related financial losses. If you wish to explore how AWS could support your implementation of Stock Depletion Engine, then please reach out to your account manager to set up a discovery workshop with the AWS Supply Chain, Transportation, and Logistics business unit.