AWS Big Data Blog
ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks.
Part 1 of this multi-post series discusses design best practices for building scalable ETL (extract, transform, load) and ELT (extract, load, transform) data processing pipelines using both primary and short-lived Amazon Redshift clusters. You also learn about related use cases for some key Amazon Redshift features such as Amazon Redshift Spectrum, Concurrency Scaling, and recent support for data lake export.
Part 2 of this series, ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 2, shows a step-by-step walkthrough to get started using Amazon Redshift for your ETL and ELT use cases.
ETL and ELT
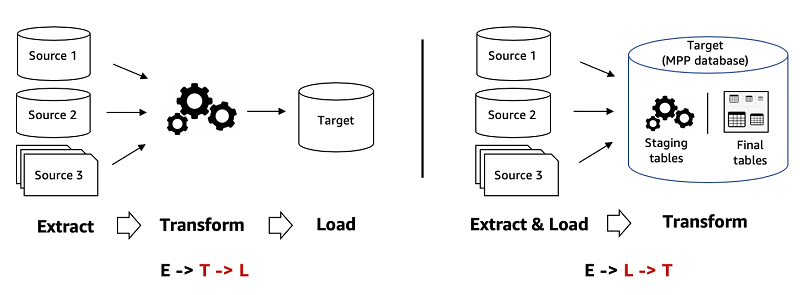
There are two common design patterns when moving data from source systems to a data warehouse. The primary difference between the two patterns is the point in the data-processing pipeline at which transformations happen. This also determines the set of tools used to ingest and transform the data, along with the underlying data structures, queries, and optimization engines used to analyze the data. The first pattern is ETL, which transforms the data before it is loaded into the data warehouse. The second pattern is ELT, which loads the data into the data warehouse and uses the familiar SQL semantics and power of the Massively Parallel Processing (MPP) architecture to perform the transformations within the data warehouse.
In the following diagram, the first represents ETL, in which data transformation is performed outside of the data warehouse with tools such as Apache Spark or Apache Hive on Amazon EMR or AWS Glue. This pattern allows you to select your preferred tools for data transformations. The second diagram is ELT, in which the data transformation engine is built into the data warehouse for relational and SQL workloads. This pattern is powerful because it uses the highly optimized and scalable data storage and compute power of MPP architecture.
Redshift Spectrum
Amazon Redshift is a fully managed data warehouse service on AWS. It uses a distributed, MPP, and shared nothing architecture. Redshift Spectrum is a native feature of Amazon Redshift that enables you to run the familiar SQL of Amazon Redshift with the BI application and SQL client tools you currently use against all your data stored in open file formats in your data lake (Amazon S3).
A common pattern you may follow is to run queries that span both the frequently accessed hot data stored locally in Amazon Redshift and the warm or cold data stored cost-effectively in Amazon S3, using views with no schema binding for external tables. This enables you to independently scale your compute resources and storage across your cluster and S3 for various use cases.
Redshift Spectrum supports a variety of structured and unstructured file formats such as Apache Parquet, Avro, CSV, ORC, JSON to name a few. Because the data stored in S3 is in open file formats, the same data can serve as your single source of truth and other services such as Amazon Athena, Amazon EMR, and Amazon SageMaker can access it directly from your S3 data lake.
For more information, see Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required.
Concurrency Scaling
Using Concurrency Scaling, Amazon Redshift automatically and elastically scales query processing power to provide consistently fast performance for hundreds of concurrent queries. Concurrency Scaling resources are added to your Amazon Redshift cluster transparently in seconds, as concurrency increases, to serve sudden spikes in concurrent requests with fast performance without wait time. When the workload demand subsides, Amazon Redshift automatically shuts down Concurrency Scaling resources to save you cost.
The following diagram shows how the Concurrency Scaling works at a high-level:
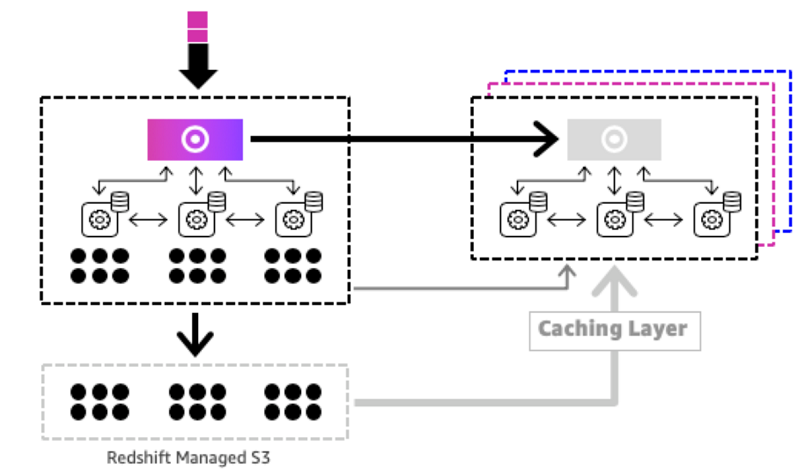
For more information, see New – Concurrency Scaling for Amazon Redshift – Peak Performance at All Times.
Data lake export
Amazon Redshift now supports unloading the result of a query to your data lake on S3 in Apache Parquet, an efficient open columnar storage format for analytics. The Parquet format is up to two times faster to unload and consumes up to six times less storage in S3, compared to text formats. You can also specify one or more partition columns, so that unloaded data is automatically partitioned into folders in your S3 bucket to improve query performance and lower the cost for downstream consumption of the unloaded data. For example, you can choose to unload your marketing data and partition it by year, month, and day columns. This enables your queries to take advantage of partition pruning and skip scanning of non-relevant partitions when filtered by the partitioned columns, thereby improving query performance and lowering cost. For more information, see UNLOAD.
Use cases
You may be using Amazon Redshift either partially or fully as part of your data management and data integration needs. You likely transitioned from an ETL to an ELT approach with the advent of MPP databases due to your workload being primarily relational, familiar SQL syntax, and the massive scalability of MPP architecture.
This section presents common use cases for ELT and ETL for designing data processing pipelines using Amazon Redshift.
ELT
Consider a batch data processing workload that requires standard SQL joins and aggregations on a modest amount of relational and structured data. You selected initially a Hadoop-based solution to accomplish your SQL needs. However, over time, as data continued to grow, your system didn’t scale well. You now find it difficult to meet your required performance SLA goals and often refer to ever-increasing hardware and maintenance costs. Relational MPP databases bring an advantage in terms of performance and cost, and lowers the technical barriers to process data by using familiar SQL.
Amazon Redshift has significant benefits based on its massively scalable and fully managed compute underneath to process structured and semi-structured data directly from your data lake in S3.
The following diagram shows how Redshift Spectrum allows you to simplify and accelerate your data processing pipeline from a four-step to a one-step process with the CTAS (Create Table As) command.

The preceding architecture enables seamless interoperability between your Amazon Redshift data warehouse solution and your existing data lake solution on S3 hosting other Enterprise datasets such as ERP, finance, and third-party for a variety of data integration use cases.
The following diagram shows the seamless interoperability between your Amazon Redshift and your data lake on S3:

When you use an ELT pattern, you can also use your existing ELT-optimized SQL workload while migrating from your on-premises data warehouse to Amazon Redshift. This eliminates the need to rewrite relational and complex SQL workloads into a new compute framework from scratch. With Amazon Redshift, you can load, transform, and enrich your data efficiently using familiar SQL with advanced and robust SQL support, simplicity, and seamless integration with your existing SQL tools. You also need the monitoring capabilities provided by Amazon Redshift for your clusters.
Warner Bros. Interactive Entertainment is a premier worldwide publisher, developer, licensor, and distributor of entertainment content for the interactive space across all platforms, including console, handheld, mobile, and PC-based gaming for both internal and third-party game titles. “We utilize many AWS and third party analytics tools, and we are pleased to see Amazon Redshift continue to embrace the same varied data transform patterns that we already do with our own solution,” said Kurt Larson, Technical Director of Analytics Marketing Operations, Warner Bros. Analytics. “We’ve harnessed Amazon Redshift’s ability to query open data formats across our data lake with Redshift Spectrum since 2017, and now with the new Redshift Data Lake Export feature, we can conveniently write data back to our data lake. This all happens with consistently fast performance, even at our highest query loads. We look forward to leveraging the synergy of an integrated big data stack to drive more data sharing across Amazon Redshift clusters, and derive more value at a lower cost for all our games.”
ETL
You have a requirement to unload a subset of the data from Amazon Redshift back to your data lake (S3) in an open and analytics-optimized columnar file format (Parquet). You then want to query the unloaded datasets from the data lake using Redshift Spectrum and other AWS services such as Athena for ad hoc and on-demand analysis, AWS Glue and Amazon EMR for ETL, and Amazon SageMaker for machine learning.
You have a requirement to share a single version of a set of curated metrics (computed in Amazon Redshift) across multiple business processes from the data lake. You can use ELT in Amazon Redshift to compute these metrics and then use the unload operation with optimized file format and partitioning to unload the computed metrics in the data lake.
You also have a requirement to pre-aggregate a set of commonly requested metrics from your end-users on a large dataset stored in the data lake (S3) cold storage using familiar SQL and unload the aggregated metrics in your data lake for downstream consumption. In other words, consider a batch workload that requires standard SQL joins and aggregations on a fairly large volume of relational and structured cold data stored in S3 for a short duration of time. You can use the power of Redshift Spectrum by spinning up one or many short-lived Amazon Redshift clusters that can perform the required SQL transformations on the data stored in S3, unload the transformed results back to S3 in an optimized file format, and terminate the unneeded Amazon Redshift clusters at the end of the processing. This way, you only pay for the duration in which your Amazon Redshift clusters serve your workloads.
As shown in the following diagram, once the transformed results are unloaded in S3, you then query the unloaded data from your data lake either using Redshift Spectrum if you have an existing Amazon Redshift cluster, Athena with its pay-per-use and serverless ad hoc and on-demand query model, AWS Glue and Amazon EMR for performing ETL operations on the unloaded data and data integration with your other datasets (such as ERP, finance, and third-party data) stored in your data lake, and Amazon SageMaker for machine learning.

You can also scale the unloading operation by using the Concurrency Scaling feature of Amazon Redshift. This provides a scalable and serverless option to bulk export data in an open and analytics-optimized file format using familiar SQL.
Best practices
The following recommended practices can help you to optimize your ELT and ETL workload using Amazon Redshift.
Analyze requirements to decide ELT versus ETL
MPP architecture of Amazon Redshift and its Spectrum feature is efficient and designed for high-volume relational and SQL-based ELT workload (joins, aggregations) at a massive scale. A common practice to design an efficient ELT solution using Amazon Redshift is to spend sufficient time to analyze the following:
- Type of data from source systems (structured, semi-structured, and unstructured)
- Nature of the transformations required (usually encompassing cleansing, enrichment, harmonization, transformations, and aggregations)
- Row-by-row, cursor-based processing needs versus batch SQL
- Performance SLA and scalability requirements considering the data volume growth over time
- Cost of the solution
This helps to assess if the workload is relational and suitable for SQL at MPP scale.
Key considerations for ELT
For ETL and ELT both, it is important to build a good physical data model for better performance for all tables, including staging tables with proper data types and distribution methods. A dimensional data model (star schema) with fewer joins works best for MPP architecture including ELT-based SQL workloads. Consider using a TEMPORARY table for intermediate staging tables as feasible for the ELT process for better write performance, because temporary tables only write a single copy.
A common rule of thumb for ELT workloads is to avoid row-by-row, cursor-based processing (a commonly overlooked finding for stored procedures). This is sub-optimal because such processing needs to happen on the leader node of an MPP database like Amazon Redshift. Instead, the recommendation for such a workload is to look for an alternative distributed processing programming framework, such as Apache Spark.
Several hundreds to thousands of single record inserts, updates, and deletes for highly transactional needs are not efficient using MPP architecture. Instead, stage those records for either a bulk UPDATE or DELETE/INSERT on the table as a batch operation.
With the external table capability of Redshift Spectrum, you can optimize your transformation logic using a single SQL as opposed to loading data first in Amazon Redshift local storage for staging tables and then doing the transformations on those staging tables.
Key considerations for data lake export
When you unload data from Amazon Redshift to your data lake in S3, pay attention to data skew or processing skew in your Amazon Redshift tables. The UNLOAD command uses the parallelism of the slices in your cluster. Hence, if there is a data skew at rest or processing skew at runtime, unloaded files on S3 may have different file sizes, which impacts your UNLOAD command response time and query response time downstream for the unloaded data in your data lake.
To maximize query performance, Amazon Redshift attempts to create Parquet files that contain equally sized 32 MB row groups. The MAXFILESIZE value that you specify is automatically rounded down to the nearest multiple of 32 MB. For example, if you specify MAXFILESIZE 200 MB, then each Parquet file unloaded is approximately 192 MB (32 MB row group x 6 = 192 MB). To decide on the optimal file size for better performance for downstream consumption of the unloaded data, it depends on the tool of choice you make. When Redshift Spectrum is your tool of choice for querying the unloaded Parquet data, the 32 MB row group and 6.2 GB default file size provide good performance. In addition, Redshift Spectrum might split the processing of large files into multiple requests for Parquet files to speed up performance. Similarly, if your tool of choice is Amazon Athena or other Hadoop applications, the optimal file size could be different based on the degree of parallelism for your query patterns and the data volume. Irrespective of the tool of choice, we also recommend that you avoid too many small KB-sized files. Similarly, for S3 partitioning, a common practice is to have the number of partitions per table on S3 to be up to several hundreds. You can do so by choosing low cardinality partitioning columns such as year, quarter, month, and day as part of the UNLOAD command.
To get the best throughput and performance under concurrency for multiple UNLOAD commands running in parallel, create a separate queue for unload queries with Concurrency Scaling turned on. This lets Amazon Redshift burst additional Concurrency Scaling clusters as required.
Key considerations for Redshift Spectrum for ELT
To get the best performance from Redshift Spectrum, pay attention to the maximum pushdown operations possible, such as S3 scan, projection, filtering, and aggregation, in your query plans for a performance boost. This is because you want to utilize the powerful infrastructure underneath that supports Redshift Spectrum. Using predicate pushdown also avoids consuming resources in the Amazon Redshift cluster.
In addition, avoid complex operations like DISTINCT or ORDER BY on more than one column and replace them with GROUP BY as applicable. Amazon Redshift can push down a single column DISTINCT as a GROUP BY to the Spectrum compute layer with a query rewrite capability underneath, whereas multi-column DISTINCT or ORDER BY operations need to happen inside Amazon Redshift cluster.
Amazon Redshift optimizer can use external table statistics to generate more optimal execution plans. Without statistics, an execution plan is generated based on heuristics with the assumption that the S3 table is relatively large. It is recommended to set the table statistics (numRows) manually for S3 external tables.
For more information on Amazon Redshift Spectrum best practices, see Twelve Best Practices for Amazon Redshift Spectrum and How to enable cross-account Amazon Redshift COPY and Redshift Spectrum query for AWS KMS–encrypted data in Amazon S3.
Summary
This post discussed the common use cases and design best practices for building ELT and ETL data processing pipelines for data lake architecture using few key features of Amazon Redshift: Spectrum, Concurrency Scaling, and the recently released support for data lake export with partitioning.
Part 2 of this series, ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 2, shows you how to get started with a step-by-step walkthrough of a few simple examples using AWS sample datasets.
As always, AWS welcomes feedback. Please submit thoughts or questions in the comments.
About the Authors
 Asim Kumar Sasmal is a senior data architect – IoT in the Global Specialty Practice of AWS Professional Services. He helps AWS customers around the globe to design and build data driven solutions by providing expert technical consulting, best practices guidance, and implementation services on AWS platform. He is passionate about working backwards from customer ask, help them to think big, and dive deep to solve real business problems by leveraging the power of AWS platform.
Asim Kumar Sasmal is a senior data architect – IoT in the Global Specialty Practice of AWS Professional Services. He helps AWS customers around the globe to design and build data driven solutions by providing expert technical consulting, best practices guidance, and implementation services on AWS platform. He is passionate about working backwards from customer ask, help them to think big, and dive deep to solve real business problems by leveraging the power of AWS platform.
 Maor Kleider is a principal product manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
Maor Kleider is a principal product manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.