The Internet of Things on AWS – Official Blog
Using AWS IoT for Predictive Maintenance
The blog post references AWS IoT Analytics, which is no longer available to new customers and will end support on December 15, 2025. For implementation guidance and alternatives, see the service migration support section at the end of this article.
The interest in machine learning for industrial and manufacturing use cases on the edge is growing. Manufacturers need to know when a machine is about to fail so they can better plan for maintenance. For example, as a manufacturer, you might have a machine that is sensitive to various temperature, velocity, or pressure changes. When these changes occur, they might indicate a failure.
Prediction, sometimes referred to as inference, requires machine-learning (ML) models based on large amounts of data for each component of the system. The model is based on a specified algorithm that represents the relationships between the values in the training data. You use these ML models to evaluate new data from the manufacturing system in near real-time. A predicted failure exists when the evaluation of the new data with the ML model indicates there is a statistical match with a piece of equipment in the system.
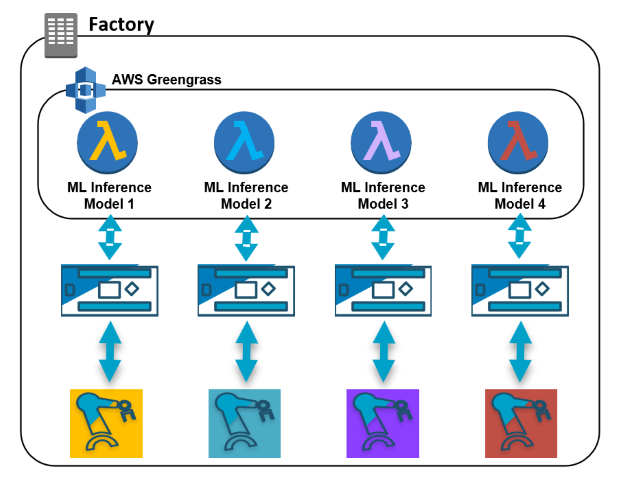
Typically, an ML model is built for each type of machine or sub-process using its unique data and features. This leads to an expansive set of ML models that represents each of the critical machines in the manufacturing process and different types of predictions desired. Although the ML model supports inference of new data sent to the AWS Cloud, you can also perform the inference on premises, where latency is much lower. This results in a more real-time evaluation of the data. Performing local inference also saves costs related to the transfer of what could be massive amounts of data to the cloud.
The AWS services used to build and train ML models for automated deployment to the edge make the process highly scalable and easy to do. You collect data from the machines or infrastructure that you want to make predictions on and build ML models using AWS services in the cloud. Then you transfer the ML models back to the on-premises location where they are used with a simple AWS Lambda function to evaluate new data sent to a local server running AWS Greengrass.
AWS Greengrass lets you run local compute, messaging, ML inference, and more. It includes a lightweight IoT broker that you run on your own hardware close to the connected equipment. The broker communicates securely with many IoT devices and is a gateway to AWS IoT Core where selected data can be further processed. AWS Greengrass can also execute AWS Lambda functions to process or evaluate data locally without an ongoing need to connect to the cloud.
Building ML models
You need to build and train ML models before you start maintenance predictions. A high-level ML process to build and train models applies to most use cases and is relatively easy to implement with AWS IoT.
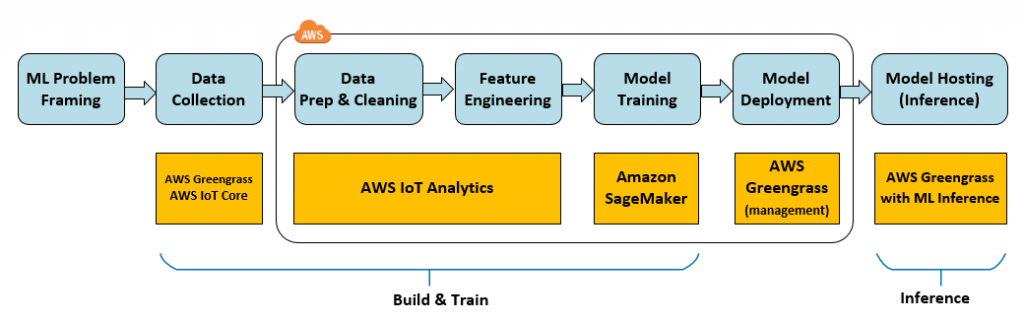
Start by collecting supporting data for the ML problem that you are trying to solve and temporarily send it to AWS IoT Core. This data should be from the machine or system associated with each ML model. A dedicated AWS Direct Connect connection between the on-premises location of the machines and AWS IoT Core supports high-volume data rates. Depending on the volume of data you are sending to the cloud, you might need to stagger the data collection for your machines (that is, work in batches).
Alternatively, an AWS Snowball appliance can transfer large amounts of data to your private AWS account using a secure hardened storage device you ship with a package delivery service. The data is transferred from AWS Snowball to Amazon S3 buckets you designate in your account.
AWS IoT Analytics supports the efficient storage of data and pipeline processing to enrich and filter the data for later use in ML model building. It also supports feature engineering in the pipeline processing with custom AWS Lambda functions that you can write to derive new attributes to help classify the data. You can visualize the results of the pipeline processing in AWS IoT Analytics using Amazon QuickSight to validate any transformations or filters you apply.
Amazon SageMaker supports direct integration with AWS IoT Analytics as a data source. Jupyter Notebook templates are provided to get you started quickly in building and training the ML model. For predictive maintenance use cases, linear regression and classification are the two most common algorithms you can use. There are many other algorithms to consider for time-series data prediction and you can try different ones and measure the effectiveness of each in your process. Also consider that AWS Greengrass ML Inference supports Apache MXNet, TensorFlow and Chainer pre-built packages that make deployment easier. Either of these ML frameworks simplify the deployment process to AWS Greengrass, but you can use others with additional setup. For example, you could use the popular Python library scikit-learn to analyze data.
Cost-optimized
Many users like the elasticity of the AWS Cloud combined with its pay-for-what-you-use pricing structure. When ML models are built and trained or later retrained, large amounts of raw data are sent to AWS IoT Core. In addition, you need large amounts of compute to speed the processing along using Amazon SageMaker. When the ML models are complete, you can archive the raw data to a lower cost storage service with Amazon Glacier or delete it. The compute resources allocated for the training are also released and costs decrease.

Deploying ML models to the edge
Running predictions locally requires the real-time machine data, ML model, and local compute resources to perform the inference. AWS Greengrass supports deploying ML models built with Amazon SageMaker to the edge. An AWS Lambda function performs the inference. Identical machines can receive the same deployment package that contains the ML model and inference Lambda function. This creates a low-latency solution. There is no dependency on AWS IoT Core to evaluate real-time data and send alerts or commands to infrastructure to shut down, if required.
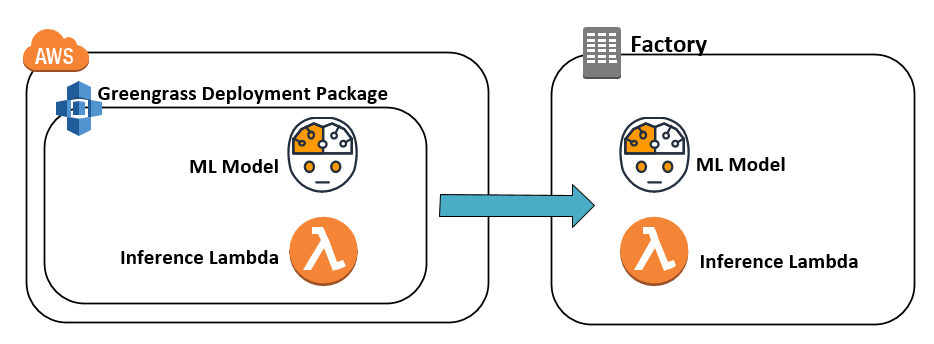
Running local predictions
The AWS Lambda function linked to the ML model as part of the AWS Greengrass deployment configuration performs predictions in real time. The AWS Greengrass message broker routes selected data published on a designated MQTT topic to the AWS Lambda function to perform the inference. When an inference returns a high probability of a match, then multiple actions can be executed in the AWS Lambda function. For example, a shutdown command can be sent to a machine or, using either local or cloud messaging services, an alert can be sent to an operations team.
For each ML model, you need to determine the threshold for inference confidence that equates to a predicted failure condition. For example, if an inference for a machine you are monitoring indicates with high confidence (let’s say a level of 90%), then you would take appropriate action. However, if the confidence level is 30%, then you might decide not to act on that result. You can use using AWS IoT Core to publish inference results on a dedicated logging and reporting topic.

Another consideration for running inference locally is ensuring you have a large enough server or multiple servers to support the amount of compute required. Factors that influence hardware sizing include:
- Number of machines being monitored (for example, is it 1 or 100 machines?)
- Amount of data sent from each machine (for example, is it 50,000 bytes or 1,000 bytes?)
- The rate at which data is sent from each machine (for example, is it once a minute or every 10 milliseconds?)
- How CPU-intensive is the ML model when performing inference and what are the memory requirements? (Some models require more system resources and might benefit from GPUs, for example.)
- What other processing is occurring on the host and are any processes resource-intensive?
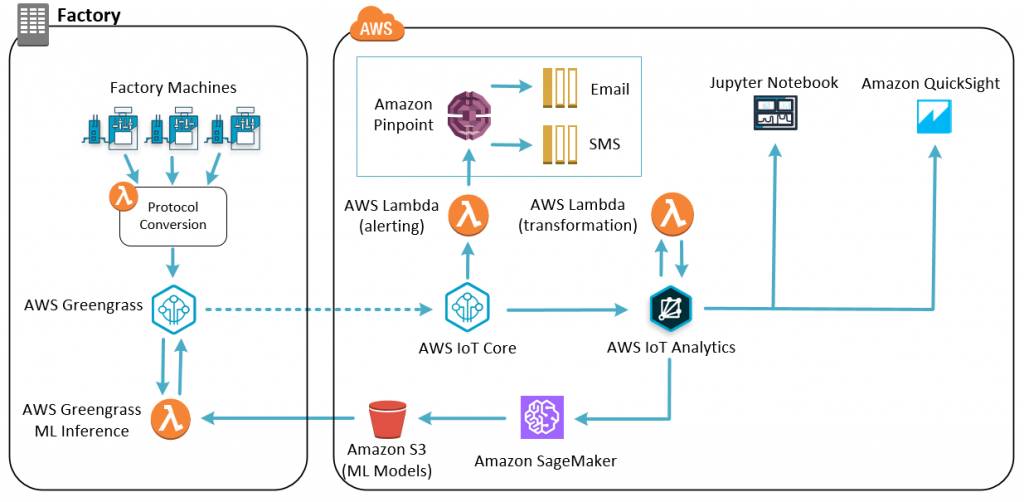
System architecture
The end-to-end architecture includes:
- The collection of data to build and train a model.
- The deployment of models back to the factory.
- The evaluation of data to perform local inference.
AWS Greengrass supports accessing local resources and AWS IoT Core to help keep your manufacturing process up and running.
Testimonial: Environment Monitoring Solutions sees 500% ROI by using AWS IoT
Environmental Monitoring Solutions specializes in solutions that help petrol retailers gather and analyze data on the performance of their petrol stations. By using AWS IoT to detect fuel leaks early to minimize environmental impact, the company received a 500% ROI. AWS IoT made it possible to connect sensors in the underground tanks and pumps of each petrol station and collect all data at 30-second intervals. The data is aggregated on cloud-computing infrastructure and displayed on a web-enabled interface in near-real time.
According to Russell Dupuy, the company’s founder and managing director, “With our AWS IoT–enabled Fuelsuite solution, customers manage their petrol stations proactively rather than reactively… to dramatically improve efficiencies and detect fuel leaks early to minimize environmental impacts.”
See for yourself. Get started today using AWS IoT for predictive maintenance.
Learn More:
- Industrial Internet of Things: https://aws.amazon.com/iot/solutions/industrial-iot/
- AWS IoT: https://aws.amazon.com/iot/
- AWS IoT Analytics User Guide: https://docs.aws.amazon.com/iotanalytics/latest/userguide/welcome.html
- Amazon Sagemaker – Getting Started Developer Guide: https://docs.aws.amazon.com/sagemaker/latest/dg/gs.html
- ML model building: https://aws.amazon.com/blogs/machine-learning/predict-march-madness-using-amazon-sagemaker/
Service Migration Support : Need Help with Service Migrations?
- Professional Consultation Options:
- Technical Support: Create a case through the AWS Support Center
- Community Support: Ask experts on the AWS re:Post IoT Community
- Partner Assistance: Find certified consultants via AWS IoT Competency Partners
- Self-Service Migration Resources:
- AWS IoT Analytics migration guide