Amazon Web Services ブログ
Category: General

【開催報告】JAPAN BUILD TOKYO 建設DX展への出展お知らせ −2025/12/19Update-
2025 年 12 月 10 日からの 3 日間、JAPAN BUILD TOKYO ー建築・土木・不動産の先端技術展ー「建設 DX 展」にてソリューション展示を行います。
昨年に引き続いて出展し、今年はさらに規模を拡大。4 つのテーマで生成 AI を活用した業務改革の具体例をご紹介します。
・物理世界とデジタルをつなぐ AI ロボット
・遠隔臨場×デジタル技能継承
・設計図書の AI レビュー
・エージェンティック AI 時代の BIM 活用
実際に動くデモンストレーションをご覧いただきながら、みなさまの現場が抱える課題や DX の取り組みについてお話しできることを楽しみにしています!
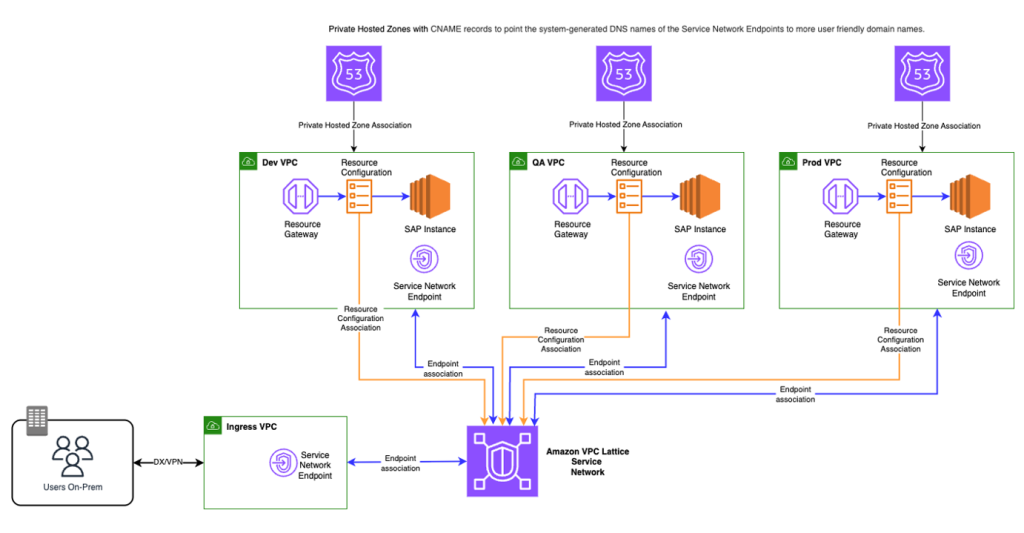
Amazon VPC Latticeによる堅牢なSAPランドスケープ分離の実現
このブログでは、AWS PrivateLinkとAmazon VPC Latticeが、ネットワーク管理を簡素化し、運用の複雑さを軽減しながら、組織が堅牢なSAPランドスケープ分離を実現する方法を探ります。

SAP証明書管理のオーバーヘッドをAWS Certificate Managerで削減
多くのSAP管理者やセキュリティ専門家にとって、証明書の管理は、すでに要求の厳しい環境において、さらに複雑なタスクのように思えるかもしれません。ここでAWS Certificate Manager(ACM)が役立ちます。AWS Certificate Managerは、パブリックおよびプライベートSSL/TLS証明書のプロビジョニング、管理、デプロイに使用されるサービスです。これらの証明書を使用して、SAPワークロードなど、EC2インスタンス上で実行されているような証明書を必要とする任意のコンピューティングワークロードでトラフィックを終端できます。
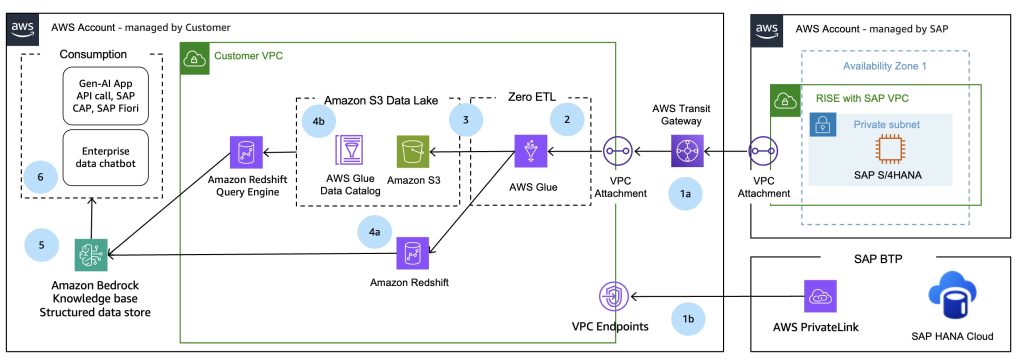
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

日産自動車、AWS と連携し SDV 実現に向けたソフトウェア開発を加速
日産自動車は、SDV 開発の3つの目標(「迅速かつ継続的な価値提供」「必要な安全性と性能の確保」「EV、HEV からガソリン車まですべての顧客への SDV 提供」)実現に向け、AWS 上に「Nissan Scalable Open Software Platform」を構築した。
その特徴は、1)CI プロセスの自動化による開発効率の向上、2)グローバルな開発環境の統一、3)次世代コンテナ管理によるプラットフォームの革新、などです。
今後は、AI 技術の活用によりさらなる進化を目指します。
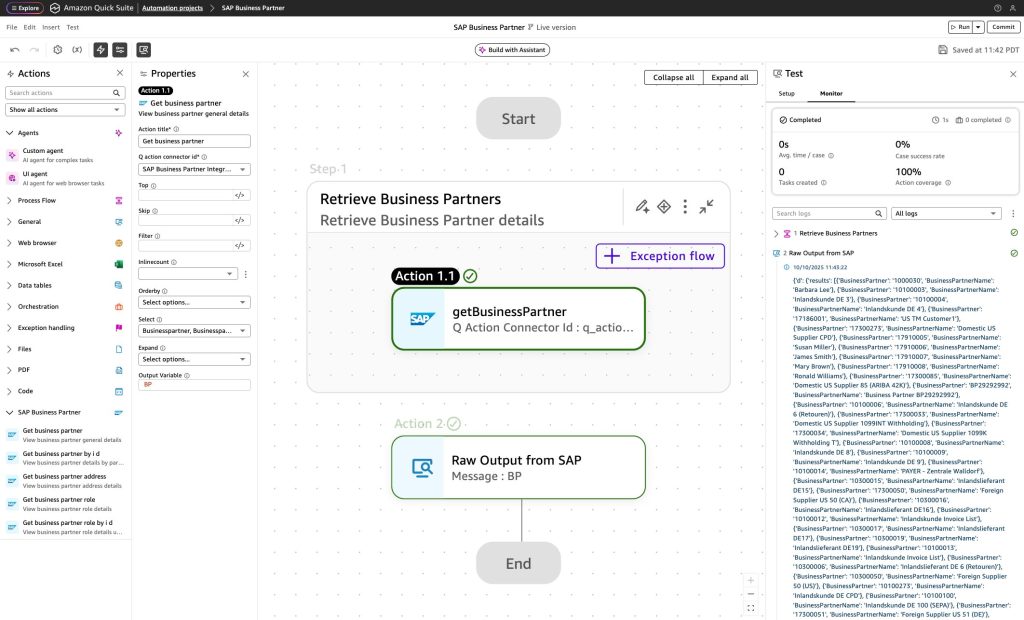
Amazon Quick AutomateでAI駆動のSAP自動化をシームレスに構築
このブログでは、Quick Suite内で利用可能なSAP用の組み込みコネクタと、お客様がAmazon Quick Automateを使用してこれらのコネクタを活用し、ビジネスオペレーションを合理化する強力な自動化を構築する方法について説明します。Quick Automateは、企業が大規模で回復力のある自動化を構築、展開、維持できるようにするQuick Suiteの機能です。AWS Action Connectors for SAPは、お客様がライブSAPデータに対してリアルタイムの読み取り操作を実行できるようにし、Quick AutomateがSAP S/4HANAなどのSAP ERPシステムとシームレスに対話できるようにします。
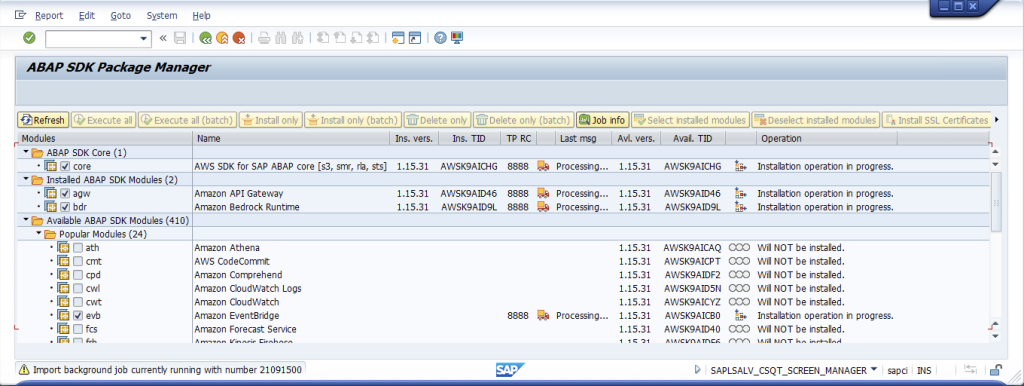
AWS SDK for SAP ABAPをプラグアンドプレイでご体験ください
AWS SDK for SAP ABAP(以下「ABAP SDK」)は、SAP ABAPベースのソフトウェアおよびシステムとAWSサービスとの統合を容易にするために、2023年半ばに初めてリリースされました。他のAWS SDKと同様に、ABAP SDKは一連のモジュールとして提供され、開発プロジェクトにインポートすることで、標準化され、安全でスケーラブルな方法でAWSサービスAPIにアクセスできます。SAP ABAP開発者およびSAP BASIS管理者がより迅速に作業を開始できるようにするため、本ブログでは、ABAP SDK用のグラフィカルインストーラー(以下「ABAP SDKインストーラー」)を紹介します。

AWSとパートナーソリューションによるセキュアなデータメッシュの構築
このブログでは、AWS ネイティブの分析サービスとサードパーティエンジンを同時に活用することを目的としたデータメッシュアーキテクチャを実装するための 3 つの重要な要件を探ります:(1)クロスカタログメタデータフェデレーション、(2)クロスアカウント&クロスエンジンでの認証と認可、(3)分散ポリシーの反映
AWS をデータプロデューサーとコンシューマーの両方として実用的な実装パターンを検討し、Databricks や Snowflake などのパートナーとの統合アプローチを代表例として紹介します。
これらのパターンは、組織が企業全体のガバナンスを維持しながら、データメッシュの中核原則をサポートする柔軟で安全かつスケーラブルなデータアーキテクチャをどのように構築するかを示しています。

AWS CloudTrail データイベントの集約とインサイト機能の発表
AWS CloudTrail は、AWS アカウントの API 呼び出しとイベントを記録し、ガバナンス、コンプライアンス、運用上のトラブルシューティングのための監査証跡を提供します。お客様は CloudTrail でデータイベントを有効にすることで、リソースレベルの操作に対するより深い可視性を得ることもできます。本日、データイベントの監視と対応方法を変革する AWS CloudTrail の強力な新機能を 2 つご紹介できることを嬉しく思います:CloudTrail データイベント用のイベント集約と Insights です。

週刊生成AI with AWS – 2025/11/24週
週刊生成AI with AWS, 今週からついにre:Invent!な2025年11月24日号。- ブログ記事では、東京海上日動システムズ様、NTTドコモ様、LIFULL様のAWS 生成 AI 活用事例紹介含む16件のブログを公開。サービスアップデートでは、Amazon BedrockでのClaude Opus 4.5サポート開始や、多くの Amazon SageMaker のアップデート含む18件を紹介。