Amazon Web Services ブログ

週刊AWS – 2025/8/25週
Aurora DSQL が AWS Fault Injection Service による耐障害性テストをサポート、Amazon RDS for Oracle が Redo Transport Compression をサポート開始、AWS IAM がネットワーク境界制御のための新しい VPC エンドポイント条件キーを開始、Amazon Connect が生成 AI テキスト読み上げ音声を提供開始、Amazon EC2 C7i インスタンスが大阪リージョンで提供開始、Amazon Q Developer が MCP 管理者制御をサポート 等

Amazon EC2 Auto Scaling ターゲット追跡スケーリングの高速化
Amazon EC2 Auto Scaling は、変化するワークロードの需要に合わせて EC2 インスタンスの数を自動的にスケーリングして必要なリソース分だけをプロビジョニングして利用できます。
本ブログでは、最近リリースされたターゲット追跡スケーリングのアップデートについて説明します。また、新機能を使用するターゲット追跡スケーリングポリシーを作成する手順を説明し、新機能がもたらす利点についても説明します。

9 月 15 日まで無料で Kiro を使用
8 月 22 日の価格更新に続き、9 月 1 日を超えて 9 月 15 日まで、Kiro の無料使用を延長いたします。
9 月 15 日まで引き続き Kiro を無料で使用できることとなります。9 月分の請求については全額返金いたしますので、引き続き無料で Kiro をご利用いただけます。使用制限は、通常のサブスクリプションサイクルの一部として、9月1日にプランの完全な制限にリセットされます。

Tech U サバイガルガイド: AWS 若手社員が新卒研修で学んだこと
本ブログでは、AWS の新卒研修プログラムである Tech U について、 AWS の若手社員が実際に参加した目線でプログラムを紹介し、若手キャリアの形成に必要な経験と成功のヒントを紹介しています。AWS Tech U は現在パブリック提供されていませんが、研修を計画する教育担当の方や、新卒研修に参加する若手エンジニアの方は、ぜひ参考にしてください。

AWS Innovate: Migrate and Modernize 開催のお知らせ
こんにちは!AWS のソリューションアーキテクトの志村です。9 月 18 日 (木) に開催される「AWS I […]
Amazon Bedrock を活用した AI エージェント開発・共有基盤「KTC Agent Store」の構築と実践
本記事は KINTO テクノロジーズ (KTC) の AI ファースト Group による寄稿です。 はじめに […]

Billing and Cost Management MCP サーバーの発表
はじめに AWS Billing and Cost Management Model Context Prot […]
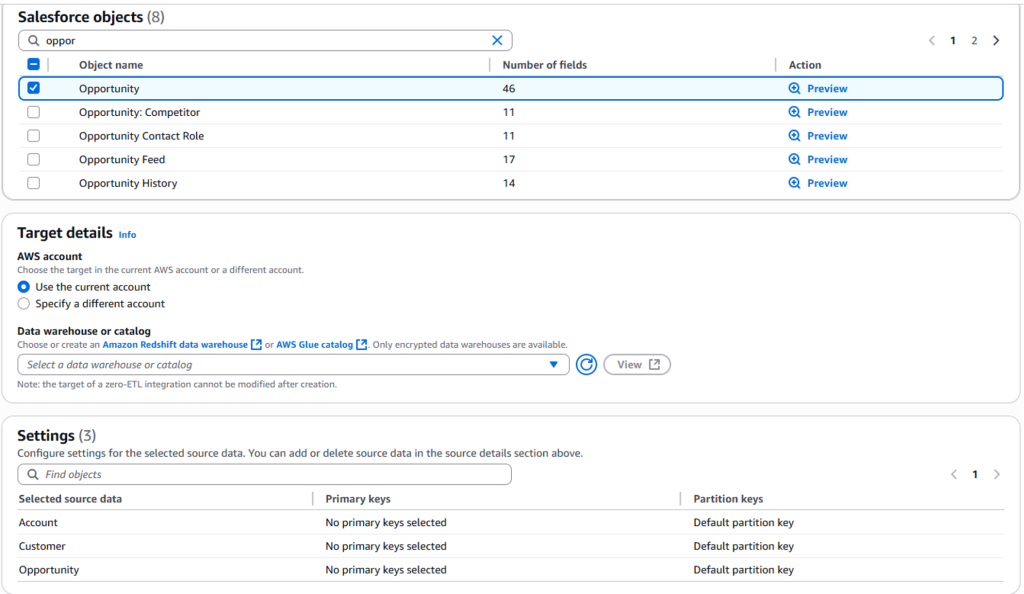
Zero-ETL: AWS によるデータ統合の課題への取り組み
このブログ記事では、Amazon Web Services (AWS) の Zero-ETL を活用することで、データ統合を簡素化すると同時に、パフォーマンスの向上やコストの最適化も実現する方法を紹介します。

Amazon Connect の導入を加速する実績ある移行パターンの紹介
エンタープライズのコンタクトセンターでは、複数の事業部門 (LOB) をサポートするのに苦労しています。特にビジネスプロセスアウトソーサー (BPO) では、独自の要件を持つ数百の顧客を管理するため、この複雑さがさらに増大します。この投稿では、中規模から大規模なコンタクトセンターの移行において堅牢な基盤を構築する、実証済みの 5 つのパターンについて説明します。これらのパターンの実装には初期投資が必要ですが、全体的な移行スケジュールを加速させるでしょう。

【期間限定無料】AWS Skill Builder の新しい Builder Labs 学習プランで AWS の学習を始めよう
実践的な Amazon Web Services (AWS) スキルをハンズオンで学習したいとお考えですか ? 本日、10 個の基礎レベルのハンズオンラボが含まれた、新しい学習プランである Introduction to AWS Cloud: Builder Labs Learning Plan (日本語版) の無料提供を発表します。AWS クラウド学習の旅を開始する準備をしましょう。
※ こちらの無料学習プランは 2025 年 11 月 2 日までの期間限定アクセスです。
クラウド専門家にとって、AWS サービスでの実践経験は成功の鍵となります。理論的な知識も大切ですが、実際の AWS 環境でのハンズオン体験に勝るものはありません。この新しい学習プランは、基本的な AWS サービスをカバーするガイド付きハンズオン体験を提供し、AWS クラウドのインフラストラクチャ基盤、セキュリティとアイデンティティ管理、モダンアプリケーション開発の知識を強化することで、このニーズに応えています。これらのコースは、業界で重要視されている基本的な AWS スキルの習得に役立ちます。