AWS Architecture Blog
Architecting near real-time personalized recommendations with Amazon Personalize
Delivering personalized customer experiences enables organizations to improve business outcomes such as acquiring and retaining customers, increasing engagement, driving efficiencies, and improving discoverability. Developing an in-house personalization solution can take a lot of time, which increases the time it takes for your business to launch new features and user experiences.
In this post, we show you how to architect near real-time personalized recommendations using Amazon Personalize and AWS purpose-built data services. We also discuss key considerations and best practices while building near real-time personalized recommendations.
Building personalized recommendations with Amazon Personalize
Amazon Personalize makes it easy for developers to build applications capable of delivering a wide array of personalization experiences, including specific product recommendations, personalized product re-ranking, and customized direct marketing.
Amazon Personalize provisions the necessary infrastructure and manages the entire machine learning (ML) pipeline, including processing the data, identifying features, using the most appropriate algorithms, and training, optimizing, and hosting the models. You receive results through an Application Programming Interface (API) and pay only for what you use, with no minimum fees or upfront commitments.
Figure 1 illustrates the comparison of Amazon Personalize with the ML lifecycle.

Figure 1. Machine learning lifecycle vs. Amazon Personalize
First, provide the user and items data to Amazon Personalize. In general, there are three steps for building near real-time recommendations with Amazon Personalize:
- Data preparation: Preparing data is one of the prerequisites for building accurate ML models and analytics, and it is the most time-consuming part of an ML project. There are three types of data you use for modeling on Amazon Personalize:
- An Interactions data set captures the activity of your users, also known as events. Examples include items your users click on, purchase, or watch. The events you choose to send are dependent on your business domain. This data set has the strongest signal for personalization, and is the only mandatory data set.
- An Items data set includes details about your items, such as price point, category information, and other essential information from your catalog. This data set is optional, but very useful for scenarios such as recommending new items.
- A Users data set includes details about the users, such as their location, age, and other details.
- Train the model with Amazon Personalize: Amazon Personalize provides recipes, based on common use cases for training models. A recipe is an Amazon Personalize algorithm prepared for a given use case. Refer to Amazon Personalize recipes for more details. The four types of recipes are:
USER_PERSONALIZATION: Recommends items for a user from a catalog. This is often included on a landing page.RELATED_ITEM: Suggests items similar to a selected item on a detail page.PERSONALZIED_RANKING: Re-ranks a list of items for a user within a category or in within search results.USER_SEGMENTATION: Generates segments of users based on item input data. You can use this to create a targeted marketing campaign for particular products by brand.
- Get near real-time recommendations: Once your model is trained, a private personalization model is hosted for you. You can then provide recommendations for your users through a private API.
Figure 2 illustrates a high-level overview of Amazon Personalize:
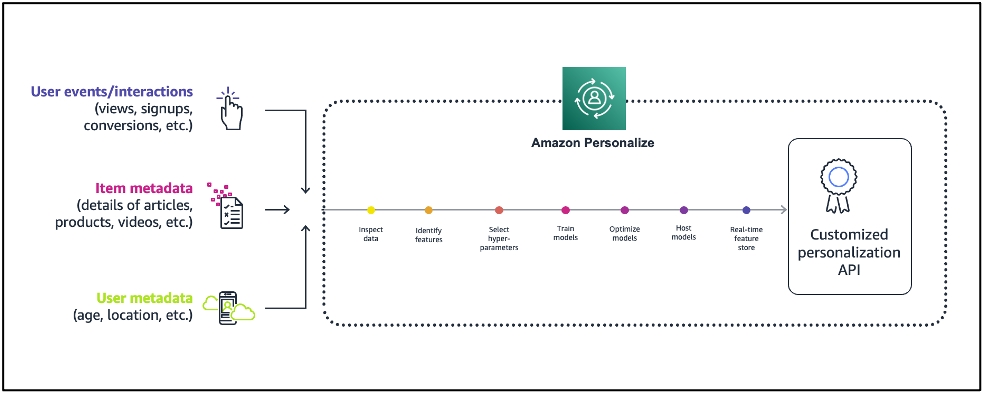
Figure 2. Building recommendations with Amazon Personalize
Near real-time personalized recommendations reference architecture
Figure 3 illustrates how to architect near real-time personalized recommendations using Amazon Personalize and AWS purpose-built data services.

Figure 3. Near real-time recommendations reference architecture
Architecture flow:
- Data preparation: Start by creating a dataset group, schemas, and datasets representing your items, interactions, and user data.
- Train the model: After importing your data, select the recipe matching your use case, and then create a solution to train a model by creating a solution version.
Once your solution version is ready, you can create a campaign for your solution version. You can create a campaign for every solution version that you want to use for near real-time recommendations.
In this example architecture, we’re just showing a single solution version and campaign. If you were building out multiple personalization use cases with different recipes, you could create multiple solution versions and campaigns from the same datasets. - Get near real-time recommendations: Once you have a campaign, you can integrate calls to the campaign in your application. This is where calls to the
GetRecommendationsorGetPersonalizedRankingAPIs are made to request near real-time recommendations from Amazon Personalize.- The approach you take to integrate recommendations into your application varies based on your architecture but it typically involves encapsulating recommendations in a microservice or AWS Lambda function that is called by your website or mobile application through a RESTful or GraphQL API interface.
- Near real-time recommendations support the ability to adapt to each user’s evolving interests. This is done by creating an event tracker in Amazon Personalize.
- An event tracker provides an endpoint that allows you to stream interactions that occur in your application back to Amazon Personalize in near real-time. You do this by using the PutEvents API.
- Again, the architectural details on how you integrate PutEvents into your application varies, but it typically involves collecting events using a JavaScript library in your website or a native library in your mobile apps, and making API calls to stream them to your backend. AWS provides the AWS Amplify framework that can be integrated into your web and mobile apps to handle this for you.
- In this example architecture, you can build an event collection pipeline using Amazon API Gateway, Amazon Kinesis Data Streams, and Lambda to receive and forward interactions to Amazon Personalize.
- The Event Tracker performs two primary functions. First, it persists all streamed interactions so they will be incorporated into future retraining of your model. This also how Amazon Personalize cold starts new users. When a new user visits your site, Amazon Personalize will recommend popular items. After you stream in an event or two, Amazon Personalize immediately starts adjusting recommendations.
Key considerations and best practices
- For all use cases, your interactions data must have a minimum 1000 interaction records from users interacting with items in your catalog. These interactions can be from bulk imports, streamed events, or both, and a minimum 25 unique user IDs with at least two interactions for each.
- Metadata fields (user or item) can be used for training, filters, or both.
- Amazon Personalize supports the encryption of your imported data. You can specify a role allowing Amazon Personalize to use an AWS Key Management Service (AWS KMS) key to decrypt your data, or use the Amazon Simple Storage Service (Amazon S3) AES-256 server-side default encryption.
- You can re-train Amazon Personalize deployments based on how much interaction data you generate on a daily basis. A good rule is to re-train your models once every week or two as needed.
- You can apply business rules for personalized recommendations using filters. Refer to Filtering recommendations and user segments for more details.
Conclusion
In this post, we showed you how to build near real-time personalized recommendations using Amazon Personalize and AWS purpose-built data services. With the information in this post, you can now build your own personalized recommendations for your applications.
Read more and get started on building personalized recommendations on AWS: