Category: Amazon RDS
Amazon RDS for SQL Server – 윈도 인증 기능 서울 리전 출시
2012년에 Amazon RDS 서비스에 대한 SQL Server 지원을 처음 시작했습니다. 그 후 SSL 지원, 주요 버전 업그레이드, 데이터 암호화 및 Multi-AZ를 포함한 많은 기능을 추가했습니다. 이러한 신규 기능은 SQL Server 기반 RDS 적용 범위를 넓히고 고객들의 추가 사용 사례를 열었습니다.
윈도우즈 워크로드를 실행하는 많은 기업에서 Active Directory를 기반한 계정 자격 증명 및 관련 사용 권한을 지정합니다. 디렉토리는이 정보에 대한 단일 소스를 제공하며 중앙 집중식 관리를 허용합니다. 지난 3월에 출시된 AWS Directory Service를 사용하여 Microsoft Active Directory의 Enterprise Edition을 실행을 오늘 부터 서울 리전에서도 사용 가능합니다.
서울 리전, 윈도 인증 지원
Microsoft Active Directory (Enterprise Edition)를 통해 AWS Directory Service에 저장된 자격 증명을 사용하여 SQL Server용 Amazon RDS에 대한 애플리케이션 인증을 허용 할 수 있습니다. 동일한 디렉토리에 모든 자격 증명을 유지함으로서 더 이상 각 복사본을 찾고 업데이트 할 필요가 없으므로 시간과 노력을 절약하면서 전체 보안 프로필이 향상 될 수도 있습니다.
SQL Server를 실행할 새 데이터베이스 인스턴스를 만들 때, 이 기능을 활성화하고 Active Directory를 선택할 수 있습니다. 또한, 기존 데이터베이스 인스턴스에 대해서도 새로 설정할 수 있습니다. 새 데이터베이스 인스턴스를 만들 때 디렉터리를 선택하는 방법은 다음과 같습니다 (새 데이터베이스 인스턴스를 만들 수도 있습니다).
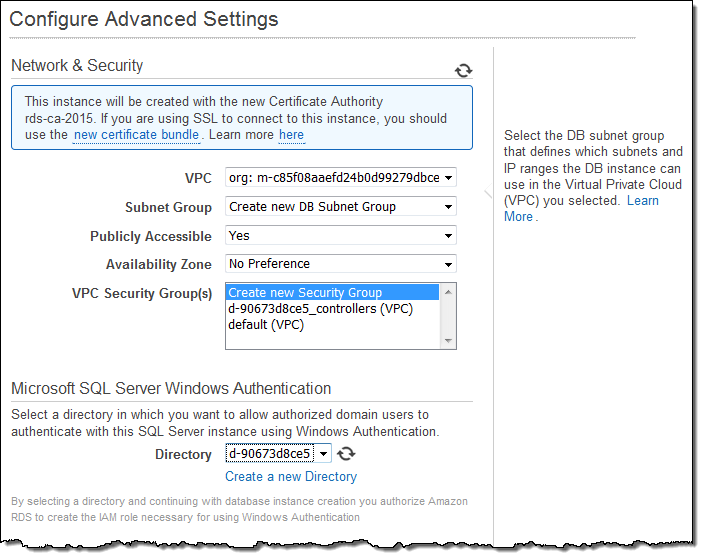
자세한 내용은 SQL Server DB 인스턴스와 함께 Microsoft SQL Server Windows 인증 사용을 참조하십시오.
서울 리전 정식 출시
본 기능은 현재 미국 동부 (버지니아 북부), 미국 서부 (오레곤), EU (아일랜드), 아시아 태평양 (시드니), 아시아 태평양 (도쿄) 및 아시아 태평양 (싱가포르)에서 사용할 수 있으며 오늘 부터 아시아 태평양(서울) 리전에서 사용을 시작할 수 있습니다 오늘. 해당 기능은 무료이지만 Active Directory 용 AWS Directory Service의 표준 요금만 지불하게 됩니다.
— Jeff;
AWS 데이터베이스 마이그레이션, 2만회 돌파!
1년 전 AWS Database Migration Service 출시를 했을 때, 이미 1,000여 고객이 데이터베이스 이전 도구로서 DMS 서비스를 활용하고 있었습니다.
즉, AWS Database Migration Service 및 Schema Conversion Tool (SCT)는 AWS 고객이 고가의 자체 데이터베이스와 데이터웨어 하우스에서 보다 비용 효율적인 Amazon Aurora, Amazon Redshift, MySQL, MariaDB PostgreSQL 같은 클라우드 기반 데이터베이스와 데이터웨어 하우스로 이동하고 있으며, 이를 통해 다운 타임을 최소화 한 상태에서 전환하게 되었습니다. 예를 들어 Amazon Aurora로 전환하면 상용 데이터베이스의 10 분의 1의 비용으로 MySQL과 PostgreSQL 호환 데이터베이스를 사용할 수 있습니다. Expedia, Thomas Publishing, Pega, Veoci 등 고객 사례는 AWS DMS 활용 사례에서 보실 수 있습니다.
20,000 데이터베이스 이전 달성
AWS 고객은 지금까지 AWS Database Migration Service 를 사용하여 20,000 건의 데이터베이스를 AWS로 이전하고 현재도 그 수는 늘어나고 있습니다. (2016 년 9 월에 10,000 건 기록).
지난해에도 DMS와 SCT 서비스에 몇 가지 새로운 기능을 추가했습니다.
- 2016년 3월 – 8개 리전 정식 출시
- 2016년 5월 – 전환 대상으로 Redshift 추가
- 2016년 7월 – 지속적인 복제를 위한 고가용서 아키텍처 제공
- 2016년 7월 – 전환 소스 및 타겟으로 SSL 엔드포인트 및 Sybase 엔진 지원
- 2016년 8월 – Asia Pacific (Mumbai) , Asia Pacific (Seoul) , South America (Brazil) 리전 확장
- 2016년 10월 – US East (Ohio) 리전 확장
- 2016년 12월 – Oracle SSL 연결 기능제
- 2016년 12월 – Canada (Central)와 Europe (London) 리전 확장
- 2017년 1월 – 이벤트와 이벤트 구독 기능 추가
- 2017년 2월 – Oracle and Teradata에서 Amazon Redshift 전환 지원
자세한 정보
데이터 베이스 마이그레이션을 위해서는 먼저 최근 온라인 세미나 및 상세한 기술 문서들을 참고하시기 바랍니다.
Migrating From Sharded to Scale-Up – 일부 고객은 스케일 아웃 전략을 통해 데이터베이스 샤딩으로 마이그레이션 효과를 극대화 하고 있습니다. 두 개 이상의 샤드를 하나의 Aurora 인스턴스에 정리 복잡성을 줄이고 신뢰성을 높이면서 비용 절감을 실현하는 방법에 대한 블로그 글, 세미나 동영상, 발표 자료를 참고 하시기 바랍니다.
Migrating From Oracle or SQL Server to Aurora – Oracle 또는 SQL Server와 같은 상용 데이터베이스에서 Aurora로 이전하고 있습니다. 관련 정보는 발표 자료나 동영상을 참고하시기 바랍니다.
그 밖에도 AWS Database Blog에 다양한 글이 있습니다.
- Reduce Resource Consumption by Consolidating Your Sharded System into Aurora
- How to Migrate Your Oracle Database to Amazon Aurora
- Cross-Engine Database Replication Using AWS Schema Conversion Tool and AWS Database Migration Service
- Database Migration—What Do You Need to Know Before You Start?
- How to Script a Database Migration –
기술 문서에도 다양한 정보를 제공하고 있습니다.
- Migrating Databases to Amazon Web Services.
- Migrating an On-Premises Oracle Database to Amazon Aurora Using AWS Database Migration Service.
- Migrating an Amazon RDS Oracle Database to Amazon Aurora Using AWS Database Migration Service.
- Migrating MySQL-Compatible Databases to AWS.
- Migrating MySQL-Compatible Databases to Amazon Aurora.
서울 Summit에서 만납시다!
오는 4월 19-20일 개최되는 AWS Summit 2017 서울 행사에서 다양한 데이터베이스 관련 세션을 마련하였습니다. 지금 등록하시고 많은 참여 바랍니다.
— Jeff;
이 글은 AWS Database Migration Service – 20,000 Migrations and Counting의 한국어 요약입니다.
Amazon RDS MySQL로 부터 Aurora 읽기 복제본 생성 기능 출시!
24시간 실행하는 웹 사이트 또는 애플리케이션인 경우, 기존 데이터베이스 엔진에서 다른 엔진으로 마이그레이션은 매우 까다로운 작업입니다. 데이터베이스를 중단하고 작업을 할 수 없다면, 일반적으로 복제를 기반으로 하는 접근 방식이 가장 좋습니다.
오늘 Amazon Aurora 읽기 복제본(Read Replica)을 통해 MySQL 용 Amazon RDS DB 인스턴스에서 Amazon Aurora로 마이그레이션 할 수 있는 새로운 기능을 출시했습니다. 마이그레이션 프로세스는 기존 DB 인스턴스의 DB 스냅 샷을 만든 다음, 이를 새로운 Aurora 읽기 복제본을 사용합니다. 복제본을 설정 한 후 복제를 사용하여 원본과 같은 최신 상태로 만들고, 복제 지체가 없어지면 복제를 완료합니다. 이 시점에서 오로라 읽기 복제본을 독립 실행 형 Aurora DB 클러스터로 만들고 클라이언트 응용 프로그램을 연결합니다.
마이그레이션은 테라 바이트 데이터 당 몇 시간이 걸리고, 최대 6 테라 바이트의 MySQL DB 인스턴스에서 작동합니다. InnoDB 테이블은 MyISAM 테이블보다 복제가 약간 더 빠르며 압축되지 않은 테이블도 가능합니다. 마이그레이션 속도가 중요한 요소라면 MyISAM 테이블을 InnoDB 테이블로 옮기고, 압축 테이블을 압축 해제하여 성능을 향상 시킬 수도 있습니다.
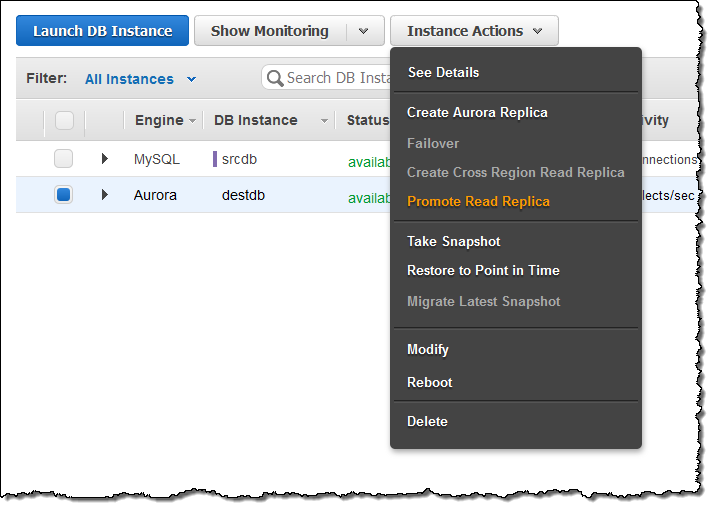
RDS DB 인스턴스를 마이그레이션하려면 AWS 관리 콘솔에서 Instance Actions를 선택하고 인스턴스 작업을 클릭 한 다음 Create Aurora Read Replica을 선택하십시오.
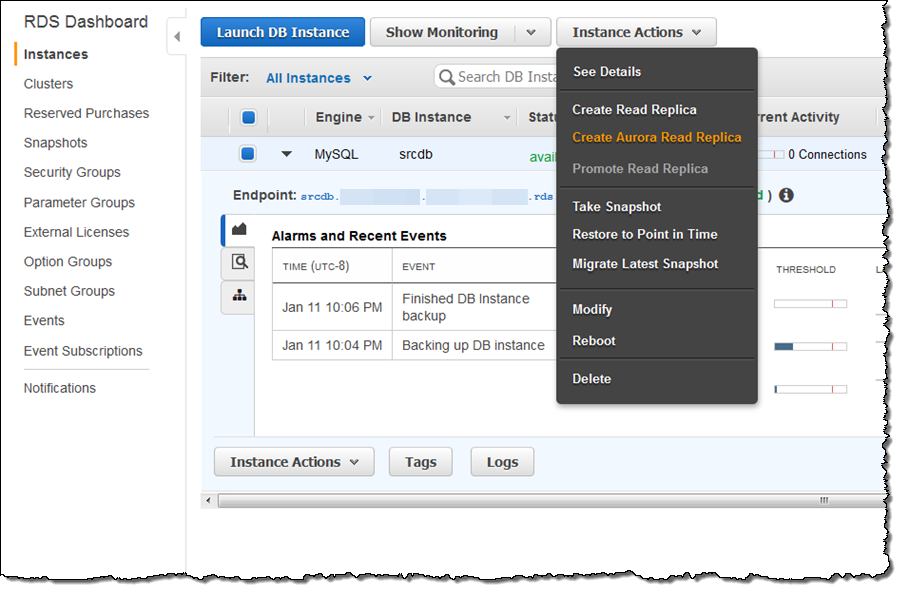
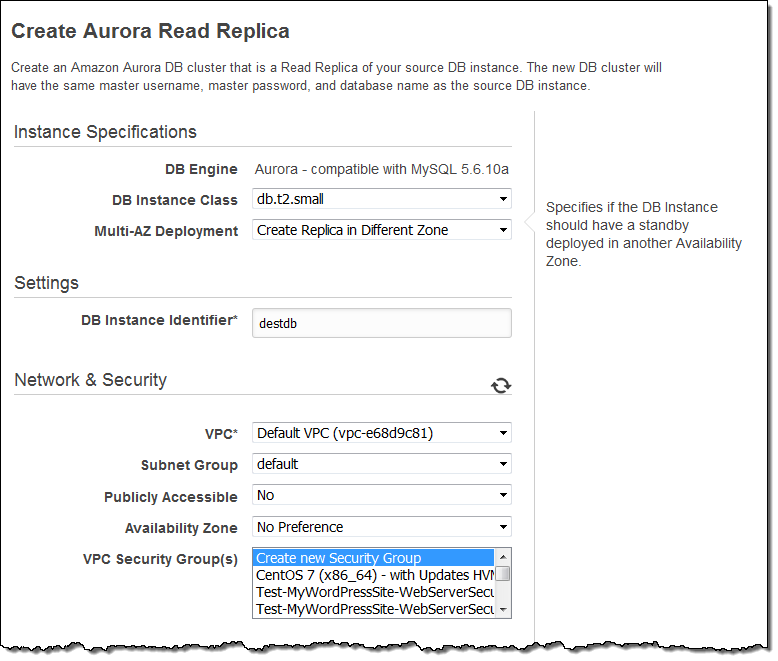
그런 다음 데이터베이스 인스턴스 식별자를 입력하고, 원하는 옵션을 설정 한 다음 Create Read Replica를 클릭합니다.
콘솔에서 마이그레이션 진행 상황을 모니터링 할 수 있습니다.
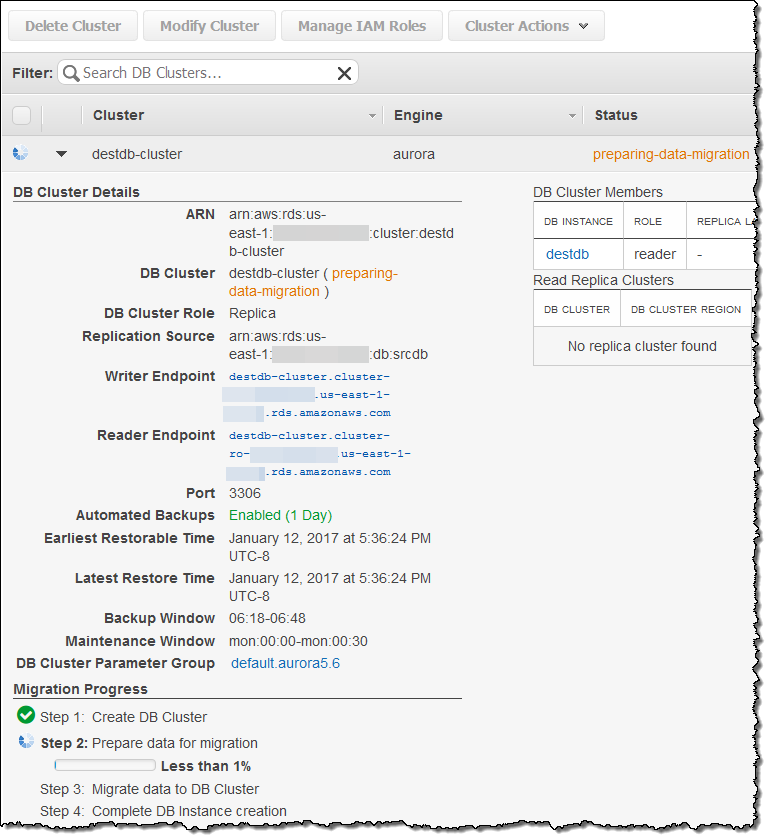
마이그레이션이 완료되면 새로운 Aurora 읽기 복제본에서 Replica Lag가 0이 될 때까지 기다렸다가 (복제본에서 SHOW SLAVE STATUS 명령을 사용하여 “Masters 뒤의 Seconds”를 확인) 복제본이 소스와 모두 동기화되면, 원본 MySQL DB 인스턴스에 대한 신규 트랜잭션을 중지하고 오로라 읽기 복제본을 DB 클러스터로 올립니다.
새 클러스터를 사용할 수 있을 때까지 기다립니다 (일반적으로 1 분 정도).
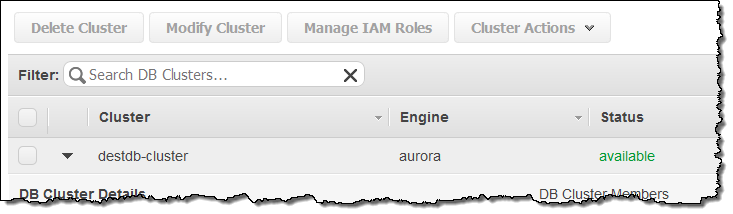
이제 응용 프로그램에 클러스터의 엔드포이트를 지정하면 됩니다!
본 기능은 오늘 부터 Amazon Aurora를 제공하는 모든 리전에서 사용 가능합니다.
— Jeff;
이 글은 New – Create an Amazon Aurora Read Replica from an RDS MySQL DB Instance의 한국어 번역입니다.
AWS 2016년 12월 31일 윤초 대응 방법
2016년말 새해를 맞이하기 전 1초를 추가하는 윤초가 시행됨을 잊지 마시기 바랍니다.
이번 윤초 (통산 27 번째)는 UTC(세계 표준시) 2016년 12월 31일 23:59:60으로 삽입됩니다 (한국 표준시로 2017년 1월 1일 8:59:60). 이는 지구 시간(협정 세계시)과 태양시(천문시)과의 차이를 줄이기 위해 진행되며, UTC 기준 올해 마지막 1분은 61가 됩니다.

이전에 윤초를 진행할 때 드린 정보(AWS에서 윤초 대응)은 계속 유효하며, 이번에도 마찬가지로 처리되지만 약간의 차이가 있습니다 :
AWS 조정 시간 (AWS Adjusted Time) – 윤초 삽입 전후의 24시간 동안 윤초의 1초를 조금씩 분산합니다(UTC에서 12월 31일 11:59:59부터 2017년 1월 1일 12:00:00까지). AWS 조정 시간과 세계 시간은 이 기간이 끝난 후 동기화합니다.
Microsoft Windows – Amazon에서 제공 된 Microsoft Windows AMI를 이용하고 있는 인스턴스는 AWS 조정 시간에 따릅니다.
Amazon RDS – 대부분 Amazon RDS 인스턴스(UTC로 설정되어있는 경우) “23:59:59″을 두 번 기록합니다. 그러나 Oracle 11.2.0.2, 11.2.0.3, 12.1.0.1는 AWS 조정 시간에 따릅니다. Oracle 11.2.0.4 및 12.1.0.2에 대한 자세한 정보가 필요한 경우 AWS 지원에 문의하십시오.
자세한 정보
윤초 삽입에 대한 질문이있는 경우AWS Support 및 EC2 Forum에 문의해 주시기 바랍니다.
— Jeff;
이 글은 Look Before You Leap – December 31, 2016 Leap Second on AWS의 한국어 번역입니다.
Amazon Aurora 기능 업데이트 – 병렬 미리 읽기, 고속 인덱싱 , NUMA 인식 등
Amazon Aurora는 현재 가장 빠르게 성장하고 있는 AWS 서비스입니다. 클라우드에 최적화된 관계형 데이터베이스 엔진으로서 Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS는 높은 성능 향상과 최대 64TB까지 원활하게 스토리지 확장 및 견고성과 가용성 향상을 실현하였습니다.
Aurora을 MySQL 호환 엔진으로 디자인함으로써 고객은 기존 애플리케이션을 마이그레이션하거나 새로운 응용 프로그램 구축할 때 더욱 간단하게 접근하실 수 있습니다.오늘 추가로 세 가지 성능을 개선하는 새로운 기능을 Aurora에 추가했습니다. 각각의 기능은 AWS를 많이 이용하는 고객의 일반적인 워크로드에서 Aurora 성능을 최대로 개선하도록 설계되었습니다.
- 병렬 미리 읽기(Parallel Read Ahead) – 구간 선택, 전체 테이블 스캔, 테이블 변경, 인덱스 생성을 최대 5배 빠르게 성능 개선
- 빠른 인덱싱(Faster Index Build) – 인덱스 생성 시간을 약 75% 단축
- NUMA 인식 스케줄링(NUMA-Aware Scheduling) – 두 개 이상의 CPU가 탑재 된 데이터베이스 인스턴스를 사용하는 경우, 쿼리 캐시에서 및 버퍼 캐시에서 읽기 성능 향상 및 전체 처리량이 최대 10 % 향상
한 가지씩 자세히 살펴보겠습니다.
병렬 미리 읽기
MySQL에서 사용되는 InnoDB 스토리지 엔진은 테이블 행이나 인덱스 키(index key)를 이용하는 스토리지(디스크 페이지)를 관리합니다. 이는 테이블의 순차 스캔 속도와 새로 생성 된 테이블에 효과적입니다. 그러나, 테이블 행이 업데이트 혹은 생성 및 삭제되면, 데이터가 파편화됨으로써 물리적으로 더 이상 순차적이지 않고, 스캔 성능이 크게 저하됩니다. InnoDB의 선형 미리 읽기(Linear Read Ahead) 기능은 페이지가 실제로 사용할 때까지 메모리에서 64 페이지까지 정리하여 데이터 파편화에 대처하고 있습니다. 그러나, 일반적으로 엔터프라이즈 규모의 워크로드에서는 이 기능이 성능 향상을 제공하지 않는다고 알려져있습니다.
이번 기능 업데이트에서는 Aurora가 많은 상황에서 현명하게 이러한 상황을 처리할 수 있는 기능을 제공합니다. Aurora의 테이블을 스캔 할 때, 논리적으로 판단하고 병렬로 페이지를 미리 추가합니다. 이러한 미리 추가(pre-fetch)기능은 Aurora의 복제 스토리지 (3개 가용 영역에 각각 2 개씩 복사)에서 우위를 발휘하여, 데이터베이스 캐시중인 페이지가 스캔 작업과 관련 있는지를 판단하는 데 도움이 됩니다.
결과적으로, 구간 검색, 전체 테이블 검색, ALTER TABLE 그리고 index 생성을 이전 버전에 비해 최대 5 배 빠르게 할 수 있습니다.
Aurora 1.7로 업그레이드하면 바로 성능 향상을 경험하실 수 있습니다.
빠른 인덱싱
특정 테이블에 기본(Primary) 및 보조(Secondary) 인덱스를 만들 때, 스토리지 엔진은 새로운 키를 포함해서 트리 구조를 만듭니다. 이 작업은 통해 많은 하향식 트리 검색 및 키의 증가에 대응하기 위해 트리 재구축을 통해 페이지 분할을 하게됩니다.
Aurora는 상향식(bottom-up) 트리 구조를 만듭니다. 리프(leaves)를 먼저 만들고 필요한 만큼 부모 페이지를 추가합니다. 이를 통해 스토리지 이동을 줄이고, 각 페이지가 일단 모두 메워지도록 하여 페이지를 분할 할 필요가 없습니다.
이를 통해 테이블 스키마에 따라 다르지만, 인덱스 추가 또는 테이블 재구성이 최대 4배 빨라집니다. 예를 들어, Aurora 팀이 다음과 같은 스키마에서 테이블을 만들고 1억 행을 추가하여 5GB의 사이즈 테이블을 제작했습니다.
create table test01 (id int not null auto_increment primary key, i int, j int, k int);
그리고 4개의 index를 추가했습니다.
alter table test01 add index (i), add index (j), add index (k), add index comp_idx(i, j, k);
db.r3.large 인스턴스에서 쿼리 실행 시간이 67분에서 25분으로 줄었고, db.r3.8xlarge에서는 29분에서 11.5분으로 단축되었습니다.
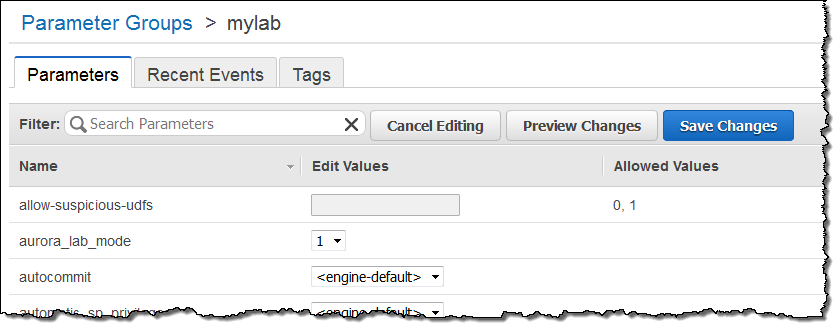
본 신규 기능은 우선 정식 서비스 환경이 아닌 테스트를 먼저 하시길 권장합니다. Aurora 1.7으로 업그레이드 하신 후, DB 인스턴스 파라미터 그룹에서 aurora_lab_mode를 1로 설정합니다. (더 자세한 사항은 DB Cluster and DB Instance Parameters 를 참고하시기 바랍니다.)
본 기능에 대한 질문 및 피드백은 Amazon RDS Forum을 통해 보내주시면 감사하겠습니다.
NUMA 기반 스케줄링
가장 큰 데이터베이스 인스턴스( db.r3.8xlarge )는 2개의 CPU를 탑재하고 있고, 불균일 기억 장치 접근(Non-Uniform Memory Access, NUMA)라는 기능을 가지고 있습니다. 본 유형의 시스템은 메인 메모리 파티션을 각 CPU에서 직접 효율적으로 사용할 수 있습니다. 나머지 메모리는 조금 비효율적 CPU 간의 접근 경로를 통해 사용합니다.
Aurora는이 고르지 못한 접근 시간을 활용하기 위해 스케줄링 스레드의 작업을 효율적으로 처리 할 수 있게 되었습니다. 스케줄링 스레드는 다른 CPU에 연결되어 있는 비효율적인 메모리 접근을 고려할 필요가 없습니다. 결과적으로, 쿼리 캐시와 버퍼 캐시를 많이 사용하는 같은 CPU 바운드 작업에서 최대 10%까지 성능을 향상하였습니다. 동일한 데이터베이스 인스턴스에 수백 또는 수천개의 동시 연결이 되어 있을 때, 현저하게 성능이 높아집니다. 예를 들어, Sysbench oltp.lua 벤치 마크에서 570,000 reads/second에서 625,000 reads/second로 향상되었습니다. 이 테스트에서는 db.r3.8xlarge DB 인스턴스에서 다음 매개 변수를 이용하여 테스트릴 진행했습니다.
oltp_table_count = 25oltp_table_size = 10000num-threads = 1500
Aurora 1.7로 업그레이드하면 바로 성능 향상을 경험하실 수 있습니다.
Aurora 1.7 업그레이드하기
DB 인스턴스를 새로 만드는 경우, Aurora 1.7로 자동으로 시작합니다. 이미 실행중인 DB 인스턴스에서 바로 업데이트하거나 다음 번에 업데이트를 선택하여 설치가 가능합니다.
아래 쿼리를 통해 Aurora 1.7이 적용되어 있는지 확인할 수 있습니다.
mysql> show global variables like "aurora_version";
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| aurora_version | 1.7 |
+----------------+-------+
— Jeff;
이 글은 Amazon Aurora Update – Parallel Read Ahead, Faster Indexing, NUMA Awareness의 한국어 번역입니다.
Amazon RDS for SQL Server – S3 네이티브 백업 및 복원 지원
Amazon Relational Database Service (RDS) 서비스는 데이터베이스 설정, 실행 및 확장성 등에서 보다 손쉽게 운영할 수 있는 완전 관리형 데이터베이스 서비스입니다. 2012년 서비스 시작 이후 SQL Server 지원, SSL 지원, 주요 버전 업그레이드 , 투명한 데이터 암호화, 확장 모니터링, Multi-AZ 등의 기능을 추가해 왔습니다.
이번에 SQL Server의 네이티브 백업 및 복원 지원을 추가합니다. SQL Server 네이티브 백업에는 테이블, 인덱스, 스토어드 프로 시저, 트리거 등 모든 데이터베이스 오브젝트가 포함되어 있습니다. 이러한 백업 데이터는 사내에서 실행 또는 클라우드에서 실행중인 SQL Server 인스턴스간에 데이터베이스를 마이그레이션하는 경우에 사용합니다. 또한, 데이터 수집, 재해 복구 등에도 사용할 수 있습니다. 네이티브 백업은 사내 SQL Server 인스턴스에서 데이터 가져오기 및 스키마의 프로세스를 단순화 할 수 있으므로, SQL Server DBA가 손쉽게 운영할 수 있습니다.
네이티브 백업 및 복구 지원
RDS 인스턴스에서 네이티브 SQL 데이터베이스를 백업, Amazon S3 버킷에 저장할 수 있게 되었습니다. SQL Server의 온프레미스에서 백업 또는 다른 RDS를 사용하는 SQL Server 인스턴스에 복원 할 수 있습니다. 또한 온프레미스 데이터베이스 백업을 S3에 복사하여, RDS SQL Server 인스턴스에 복원 할 수 있습니다. Amazon S3에서 SQL Server의 네이티브 백업 및 복원은 모든 버전에서 AWS Key Management Service (KMS) 기반 백업 암호화를 지원합니다. S3를 통해 AWS에서 백업을 보관 및 이동 할 때 다른 재해 복구 대책 옵션이 제공됩니다. SQL_SERVER_BACKUP_RESTORE 옵션을 옵션 그룹에 추가하고, 해당 그룹과 RDS SQL Server 인스턴스를 연결하면, 본 기능을 선택 할 수 있습니다. 이 옵션은 S3 버킷 정보도 설정해야합니다. 또한, 백업을 암호화하기 위해 KMS 키를 추가 할 수 있습니다. 그리고 원하는 옵션 그룹을 검색합니다.
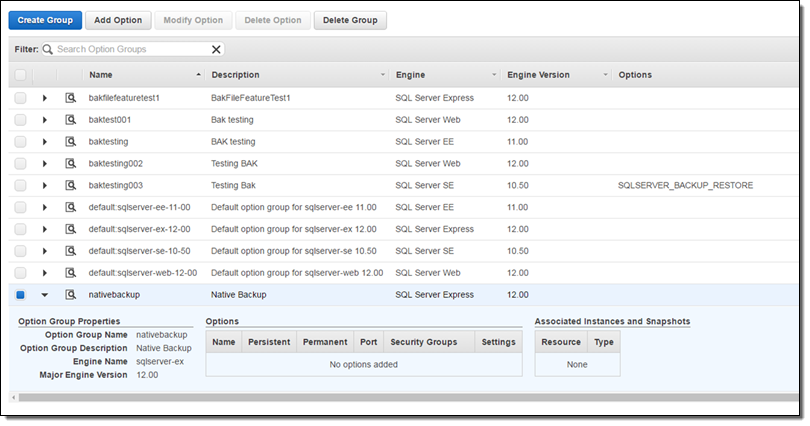
SQL_SERVER_BACKUP_RESTORE 옵션을 추가하고 IAM 역할을 지정 (또는 생성)하고 RDS가 S3에 접근할 수 있도록합니다. 버킷의 (희망하는 경우) 암호화를 확인하고 설정합니다.
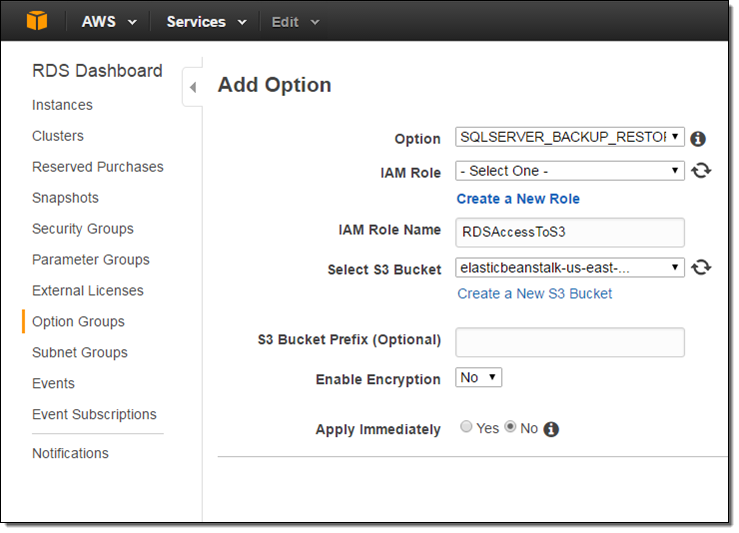
설정이 완료되면 SQL Server Management Studio를 사용하여, 데이터베이스 인스턴스에 연결하고 필요에 따라 다음의 스토어드 프로 시저(msdb 데이터베이스에서 사용 가능)를 호출합니다.
rds_backup_database– 하나의 데이터베이스를 S3 버킷에 백업rds_restore_database– S3에서 하나의 데이터베이스를 복원rds_task_status– 백업 실행을 추적하고 작업을 복원rds_cancel_task– 실행중인 백업을 취소하거나 작업을 복원
자세한 내용은 SQL Server 데이터 가져오기 및 내보내기를 참조하십시오.
이용 가능
SQL Server 네이티브 백업 및 복원 지원은 US East (Northern Virginia), US West (Oregon) Europe (Ireland), Asia Pacific (Sydney), Asia Pacific (Tokyo) Asia Pacific (Singapore), Asia Pacific (Mumbai) , South America (Brazil) 리전에서 사용할 수 있습니다. 본 기능을 Amazon RDS for SQL Server 기본 요금 이외 추가 비용이 없으며, Amazon S3 스토리지 사용량은 일반 요금으로 청구됩니다. (향후, 서울 리전에서도 지원 예정입니다.)
– Jeff;
이 글은 Amazon RDS for SQL Server – Support for Native Backup/Restore to Amazon S3의 한국어 번역입니다.
Amazon RDS 서비스 신규 기능 추가 – PostgreSQL 리전간 읽기 복제본 제공 등
지난 주에는 Amazon RDS 서비스에 대한 다양한 신규 기능이 공개되었습니다. 오늘은 한국 고객에게 유용한 몇 가지를 소개해 드리고자 합니다.
SQL Server, 다중-AZ 미러링 기능 도쿄 리전 지원!
지난 달 서울 리전에 공개된 Amazon RDS for SQL Server 서비스의 다중-AZ 지원을 도쿄 리전에서도 사용 가능합니다. 더 자세한 사항은 미러링을 통한 SQL Server 다중 AZ 작업을 참고하십시오.
PostgreSQL, 리전간 읽기 복제본 서비스 제공
디스크 암호화를 하지 않은 Amazon RDS for PostgreSQL 데이터베이스 인스턴스에서 리전간 읽기 복제본(Cross-region read replica)를 사용할 수 있게되었습니다. 이 기능을 이용하시면, 지리적으로 떨어진 글로벌 사용자에 대해 읽기 대기 시간을 줄일 수 있게 되고, 재해 복구 목적으로 데이터베이스를 백업 할 수 있습니다. 또한 쉽게 데이터베이스를 다른 AWS 지역으로 전환 할 수 있게 되었습니다.
- 재해 복구 : 데이터베이스 재해 복구 목적으로 리전간 읽기 복제본를 사용하실 수 있습니다. 만일 메인 DB이 제공되지 않는 상태가 되었을 경우, 읽기 복제본을 메인 역할으로 바꿈으로서 비즈니스 연속성을 할 수 있습니다.
- 확장성 : 리전간 읽기 복제본를 이용하여 지리적으로 분산 된 환경에서 읽기 작업 부하를 분산 할 수 있습니다. 글로벌 사용자에 가까운 데이터베이스에서 읽기를 통한 지연을 줄일 수 있습니다.
- 리전간 마이그레이션 : 만약 다른 AWS 리전에 쉽게 데이터베이스를 마이그레이션하려면 작업 단계 및 시간을 줄일 수 있습니다. 대상 리전에서 읽기 복제본을 만들고 응용 프로그램이 새 마스터 데이터베이스를 사용하도록 응용 프로그램의 설정을 변경합니다.
이 기능은 모든 RDS PostgreSQL (9.5.2, 9.4.7 이상) 데이터베이스로 이용하실 수 있습니다. 이 버전보다 이전 데이터베이스 인스턴스 여기의 기능을 이용하고 싶은 경우 데이터베이스의 버전 업그레이드를 수행해야합니다. RDS PostgreSQL의 cross-region replication 대한 자세한 내용은 RDS 문서를 참조하십시오.
Oracle Repository Creation Utility (RCU) 사용 가능
6월 19일 부터 Amazon RDS for Oracle에서 Fusion Middleware 구성 요소에 대한 스키마를 작성하기 위해 Oracle Repository Creation Utility (RCU) 12c를 이용하실 수 있게 되었습니다. 이 기능은 신규 Amazon RDS Oracle 12c 및 11g 데이터베이스 버전 “11.2.0.4.v8”, “12.1.0.1.v5″및 “12.1.0.2.v4″로 이용 가능합니다. 이 버전은 April 2016 Oracle Patch Set Updates (PSU)를 포함합니다. 버전 “11.2.0.4.v8”, “12.1.0.2.v4″는 Oracle GoldenGate위한 추천 패치가 포함되어 있습니다. 또한 “grant option”을 이용하여 SYS objects에 권한을 부여하는 기능을 추가하고 있습니다.
Oracle “11.2.0.4.v8”, “12.1.0.1.v5″와 “12.1.0.2.v4″DB 인스턴스를 만들려면, AWS Management Console의 “Launch DB Instance Wizard”를 이용하여 원하는 DB 버전을 지정하고 시작할 수 있습니다. 기존 데이터베이스 인스턴스를 업그레이드하기 위해서는, “Modify”옵션을 선택하고 원하는 데이터베이스 엔진 버전을 선택합니다. 정식 서비스 중인 데이터베이스를 업그레이드하기 전에, 데이터베이스 인스턴스의 스냅 샷에서 테스트 데이터베이스 인스턴스의 복원을 수행하여, 업그레이드 절차 및 소요 시간을 확인하고, 응용 프로그램의 새로운 데이터베이스 버전의 호환성 역시 확인 하시길 추천합니다.
Amazon RDS for Oracle에서 RCU를 이용하기위한 자세한 내용은 Amazon RDS for Oracle에서 Oracle Repository Creation Utility위한 단계별 가이드를 참조하십시오. SYS objects에 grant privileges하는 방법은 Oracle DB 인스턴스 페이지의Common DBA Tasks for Oracle DB Instances 페이지를 참조하십시오. Amazon RDS for Oracle DB 엔진 Release Notes를 방문하시면, 더욱 자세한 내용을 확인하실 수 있습니다.
Amazon Aurora, 리전간 Read Replica 추가 가능
Amazon Aurora 기존 클러스터에 읽기 복제본(Read Replica)을 추가하여 읽기 용량에 대해 확장을 하실 수 있습니다. 오늘 부터 읽기 복제본을 다른 리전에서도 만들 수 있는 기능을 제공합니다. 신규 기능을 이용하여 리전 간 재해 복구 구성을 사용할 수 있으며, 읽기 용량을 확장 할 수 있습니다. 그 외에도 다른 리전 데이터베이스를 이전하거나, 새로운 환경을 구축하는 데에도 사용할 수 있습니다.
읽기 복제본을 다른 리전에 만들면 Aurora 클러스터가 그 리전에도 생성됩니다. Aurora 클러스터에는 15대까지 리전 내에서 낮은 지연 속도(대부분의 경우 20ms 이내)에서 읽기 복제본을 만들 수 있습니다. 리전 사이의 경우, 원본 클러스터와 대상 클러스터 사이의 거리에 따라 지연 시간이 증가합니다. 이러한 구성은 현재 Aurora 클러스터를 복제하거나, 재해 복구 목적으로 읽기 복제본를 리전간에 구성하기를 원할 때 사용할 수 있습니다. 만일 리전에 오류가 발생한 경우, 지역간 읽기 복제본이 마스터 데이터베이스로 변경됨으로, 다운타임을 최소화 할 수 있습니다. 본 기능은 암호화되지 않은 Aurora 클러스터에 적용 가능합니다.
읽기 복제본을 만들기 전에 대상 리전에 VPC와 Database Subnet Groups가 존재하는지 마스터에서 바이너리 로그가 활성화되어 있는지 확인해야합니다.
VPC 설정 하기
Aurora는 VPC내에서 동작하기 때문에, 원하는 리전에 적절한 Database Subnet Groups가 존재하는지 확인합니다.
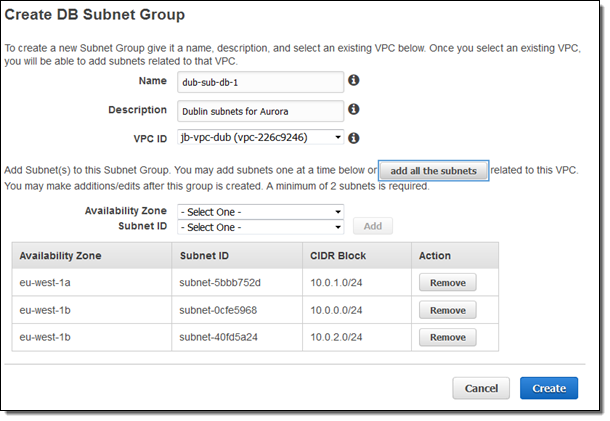
바이너리 로그 사용하기
지역 간 읽기 복제본을 설정하기 전에 바이너리 로그를 활성화 해야 합니다. 만약 default 매개 변수 그룹을 사용하는 경우, 새로운 DB Cluster Parameter Group을 생성합니다.
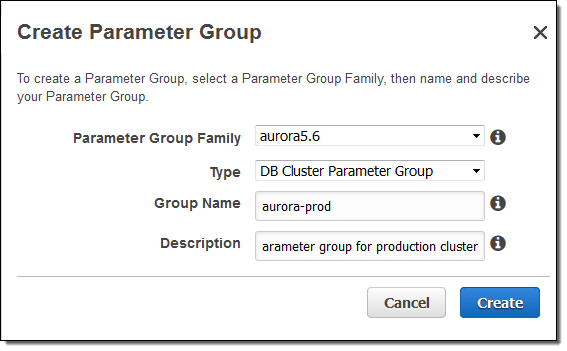
바이너리 로그를 활성화 (MIXED로 선택)하고, Save Changes를 클릭합니다.
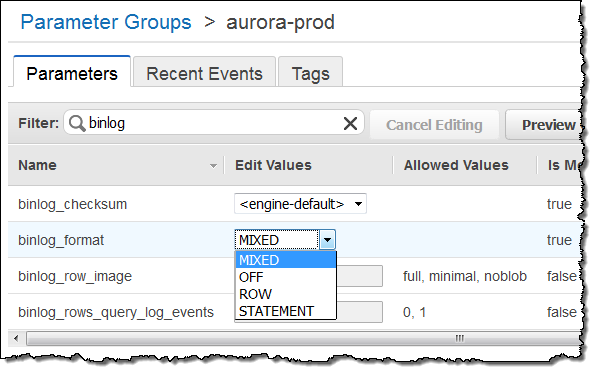
Next, Modify the DB Instance, select the new DB Cluster Parameter Group, check Apply Immediately, and click on Continue. Confirm your modifications, and then click on Modify DB Instance to proceed:
다음 단계로, 설정을 변경하고자 하는 DB 인스턴스를 선택하고 Modify를 선택합니다. 그리고 새로운 DB Cluster Parameter Group을 통해 Apply Immediately를 선택하고 Continue를 클릭합니다. 설정 변경을 확인한 후, Modify DB Instance를 누릅니다.
인스턴스를 선택하고 재시작을 실행될 때까지 기다립니다
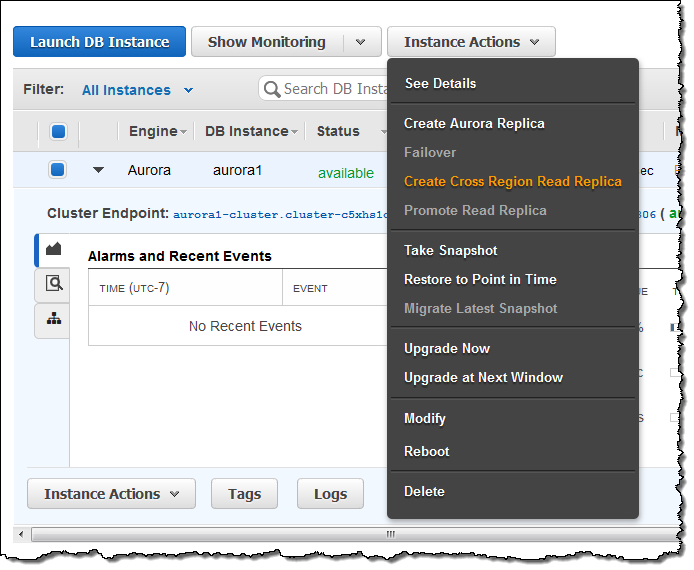
읽기 복제본 만들기
사전 준비가 완료되면 읽기 복제본을 만듭니다. 우선 AWS Management Console에서 소스 클러스터를 선택하고, Instance Actions메뉴에서 Create Cross Region Read Replica를 선택합니다 :
Name the new cluster and the new instance, and then pick the target region. Choose the DB Subnet Group and set the other options as desired, then click Create:
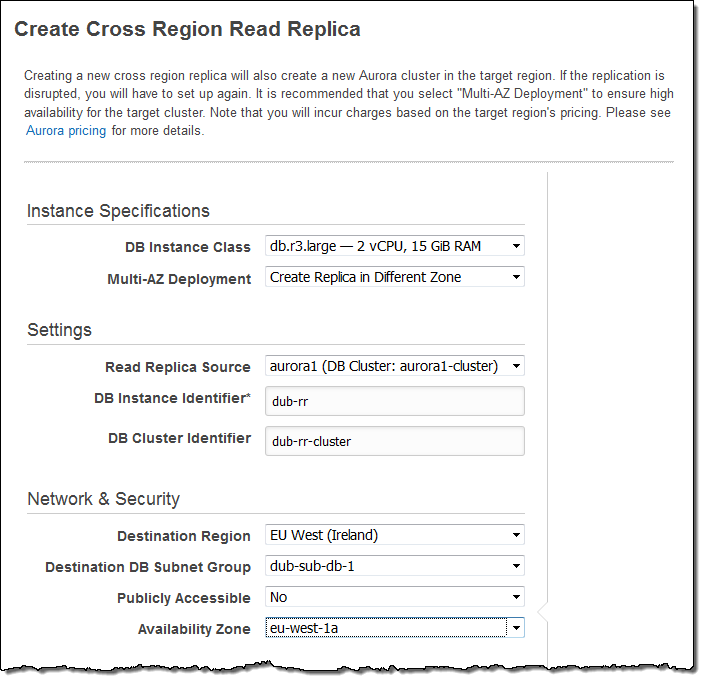
새 인스턴스나 클러스터의 이름을 설정하고 대상 리전을 선택합니다. DB Subnet Group을 선택하고 다른 옵션도 원하는 설정한 후, 마지막으로 Create를 누릅니다.
본 기능은 오늘 부터 바로 사용할 수 있습니다.
— Jeff;
이 글은 New – Cross-Region Read Replicas for Amazon Aurora의 한국어 번역입니다.
Amazon RDS for SQL Server, 다중-AZ 미러링 기능 서울 리전 지원!
오늘 부터 Amazon RDS for SQL Server 서비스의 다중-AZ 지원을 Asia Pacific (Seoul) 리전에서 사용 가능합니다.
이제 SQL 서버를 사용하는 엔터프라이즈급 서비스 환경에 요구 사항에 맞도록 추가적인 인프라 향상을 통해 미러링 기술이 적용된 고가용성 서비스를 선택할 수 있습니다. 다중 AZ 방식은 더 높은 가용성 및 데이터 내구성을 제공합니다. 두 개의 가용 영역(AZ) 사이의 데이터 베이스 리플리케이션을 자동으로 수행하기 때문입니다. 하나의 가용 영역은 서로 다른 가용 영역의 문제가 발생할 것을 대비하여 물리적으로나 지역적으로 완전히 독립된 인프라를 운용하고 있습니다.
여러분이 다중-AZ 환경에서 SQL 서버 데이터베이스 인스턴스를 생성 혹은 수정을 하시면, Amazon RDS 서비스는 자동으로 마스터 데이터베이스를 하나의 AZ에 구동한 후, 자동으로 다른 AZ에 리플리카를 스탠바이 상태로 유지하고 동기화 합니다. 데이터센터 운용에 문제가 발생되거나 마스터에 문제가 생기게 되면, Amazon RDS는 자동으로 장애 극복(Fail-over) 기능을 통해 다른 AZ의 SQL 서버를 사용할 수 있게끔 합니다. 이를 통해 데이터베이스 운영자가 수작업없이 빠르게 DB를 복구할 수 있습니다.
서울 리전에서 SQL 서버 RDS 인스턴스 생성 시, 다중-AZ 선택을 사용하실 수 있습니다.
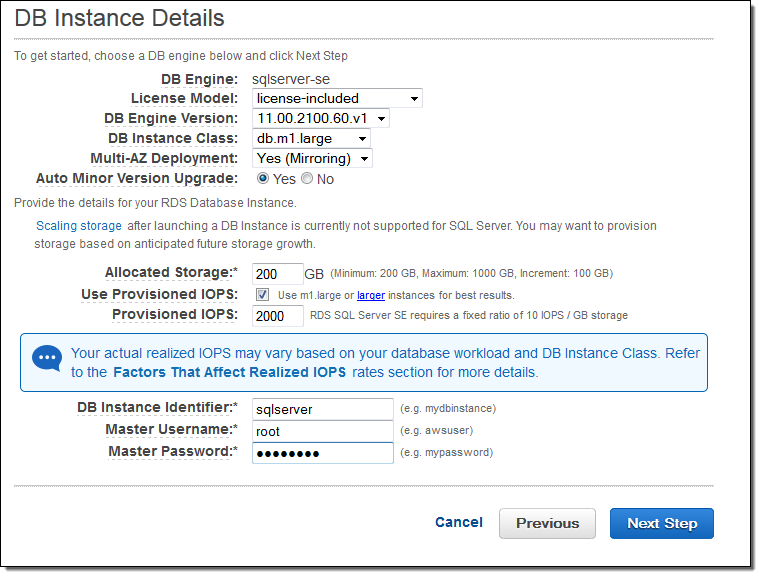
기존 RDS for SQL Server 인스턴스도 쉽게 미러링 기능을 설정할 수 있습니다.
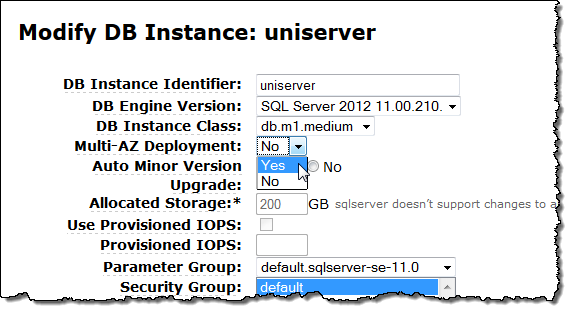
다중-AZ는 기능은 Microsoft SQL Server 2008 R2 및 2012 Standard and Enterprise 에디션에서 사용 가능합니다. 더욱 향상된 장애 극복 및 고가용성 기능을 통해 미션 크리티컬한 업무 환경에 유용합니다.
더 자세한 사항은 미러링을 통한 SQL Server 다중 AZ 작업을 참고하십시오.
– AWS코리아 마케팅팀
AWS 데이터베이스 마이그레이션 서비스(DMS) 오픈!
 여러분이 기존 환경에서 오라클, SQL서버, MySQL, MariaDB 및 PostgreSQL 데이터베이스를 운영하고 계시다면, AWS 클라우드로 이전하셔서 확장성이 높은 운영 효율적인 다양한 대용량 데이터 스토리지 옵션의 혜택을 누리실 수 있습니다.
여러분이 기존 환경에서 오라클, SQL서버, MySQL, MariaDB 및 PostgreSQL 데이터베이스를 운영하고 계시다면, AWS 클라우드로 이전하셔서 확장성이 높은 운영 효율적인 다양한 대용량 데이터 스토리지 옵션의 혜택을 누리실 수 있습니다.
그러면 어떻게 다운타임 없이 이전을 할 수 있을까요? 오늘 출시된 AWS Database Migration Service (DMS) 서비스가 바로 그 해답입니다. 작년 가을 AWS re:Invent 행사에서 미리 보기로 발표된 이후로 이미 우리 고객들의 1,000여개가 넘는 데이터베이스가 AWS로 이전하였습니다. 여러분도 바로 테라 바이트급 데이터베이스를 운영하는 도중이나 (신규 요구사항에 맞춤) 새로운 버전으로 업그레이드 하면서 라이브로 옮겨 보실 수 있습니다. 만약 클라우드로 옮기려고 하는 데이터베이스가 완전히 다른 엔진이라면 AWS Schema Conversion Tool 을 통해 스키마와 저장 프로시저를 새로운 환경으로 옮길 수 있습니다
AWS Database Migration Service는 AWS 상의 리플리케이션 인스턴스를 설정하여 동작하게 됩니다. 이 인스턴스는 기존 소스 데이터베이스에서 데이터를 업로드하고, 이전 대상 데이터베이스에 전송을 합니다. 이를 통해 최소한의 다운타임을 지원하는 리플리케이션 방식을 따라서 한번에 이전이 가능하다는 장점이 있습니다. DMS는 마이그레이션에 관련된 복잡한 문제들, 예를 들어 데이터 타입 변환, 데이터 플랫폼의 이전(오라클, Aurora 등)이 가능합니다. 또한, 리플리케이션 인스턴스 현황 및 헬스 체크 모니터링을 제공하며, 문제가 있을 때 알림을 보내고 필요하다면 자동으로 인스턴스를 대체할 수 있습니다.
DMS는 다양한 이전 시나리오 및 네트워크 옵션을 제공합니다. 엔드 포인트가 AWS일 수도 있고, 기존 온-프레미스 환경일 수도 있습니다. 또한 EC2 인스턴스에 설치된 DB 혹은 RDS 인스턴스가 될 수도 있습니다. 소스 및 최종 이전 대상은 같은 Virtual Private Cloud (VPC)에 있거나, 두 개의 나눠진 VPC에서도 가능합니다. 여러분이 온-프레미스 데이터베이스를 이전하시려면, AWS Direct Connect.를 사용하여 전용 회선으로 연결하여 VPC 설정 후 사용 가능합니다.
데이터베이스 마이그레이션 하기
관리 콘솔에서 몇 번 클릭을 하기만 하면, 이전 작업을 시작할 수 있습니다. 먼저 이전을 원하는 데이터베이스를 선택하고, 스키마 이전, 리플리케이션 설정, 마이그레이션 시작을 하면 됩니다. 소스에서 이전이 완전히 완료가 되면, 애플리케이션에서 DB의 설정만 바꾸어 주면 됩니다.
AWS Database Migration Service 콘솔에서 DMS 를 클릭한 후, Create migration을 선택합니다.
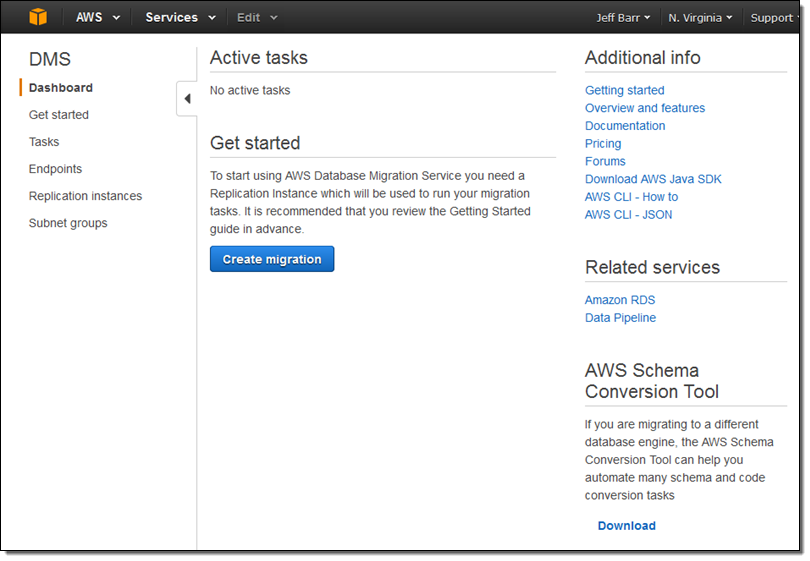
콘솔에서는 마이그레이션 절차에 대해 간단하게 소개해 드립니다.
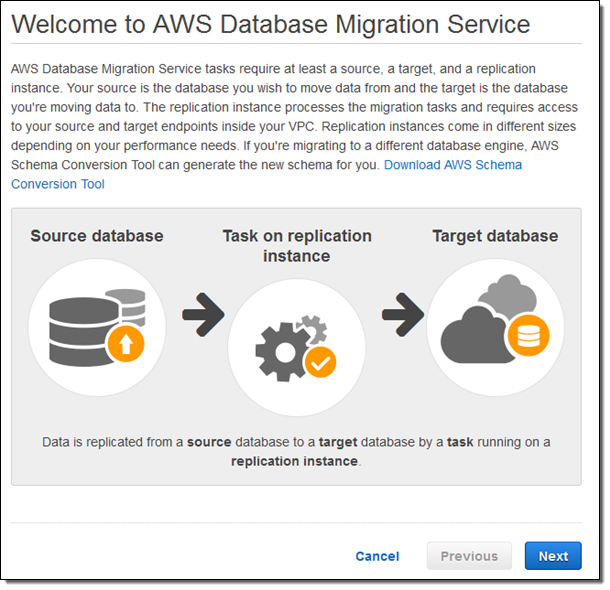
리플리케이션 인스턴스를 만들 각종 파라미터 값을 입력합니다.
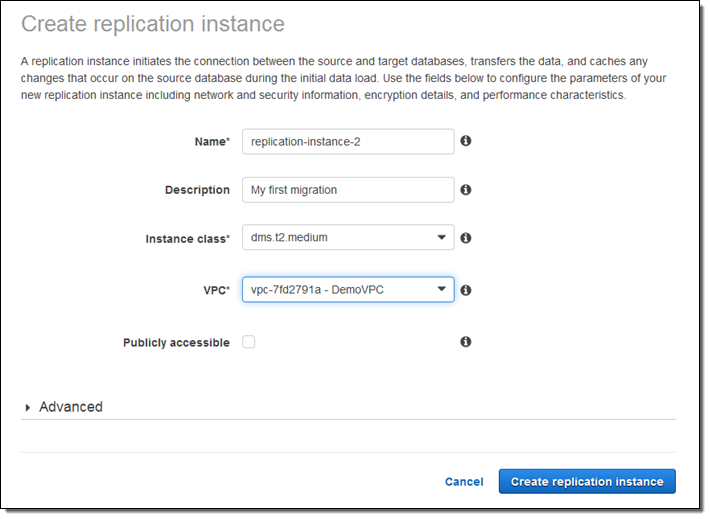
이 글에서는 기존 VPC를 선택하고, Publicly accessible를 선택하지 않았습니다. 이전 대상 데이터베이스는 EC2 인스턴스에 있기 때문입니다.
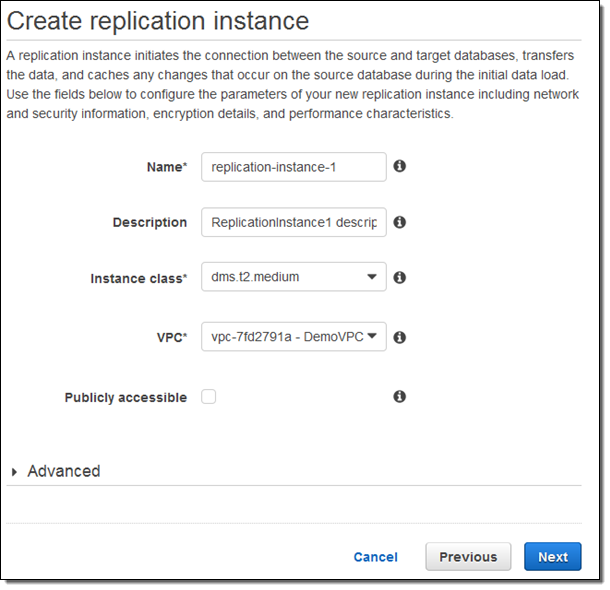
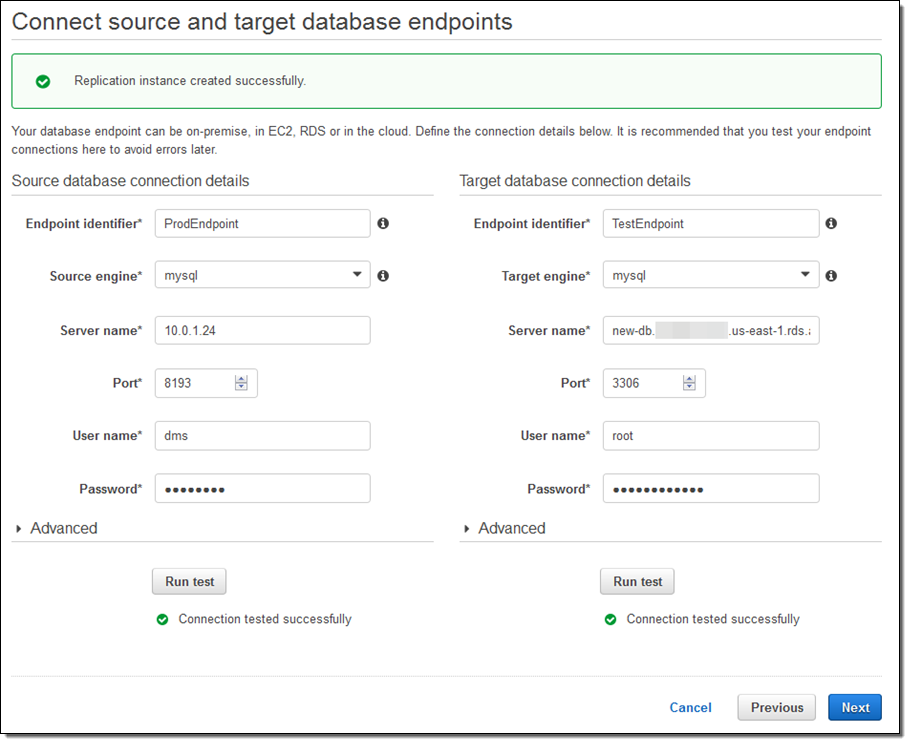
리플리케이션 인스턴스가 만들어지면, 소스 및 최종 이동 대상 데이터베이스를 선택한 후 Run test를 선택합니다. 접속이 잘되는지 네트워크 이슈가 없는 지를 테스트해 볼 수 있습니다.
이제 실제 마이그레이션 작업이 진행되기 위해, Migration type을 설정하면, 기존 데이터, 이전 후 리플리케이션, 리플리케이션 등을 선택할 수 있습니다.
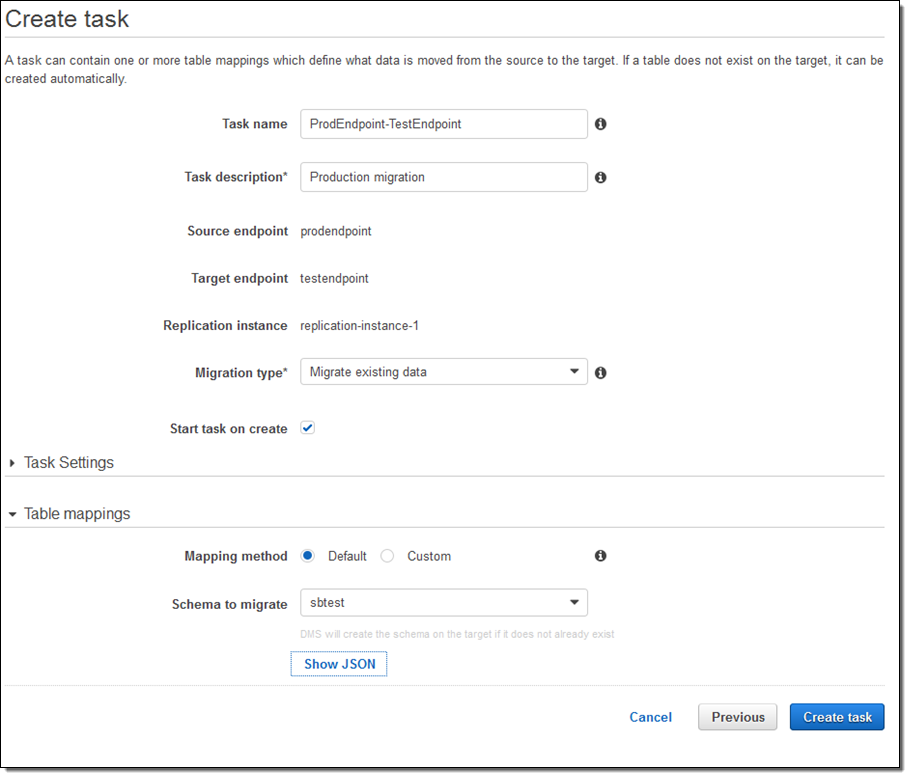
이제 Task Settings를 선택합니다. (LOBs는 Large Objects를 의미합니다).
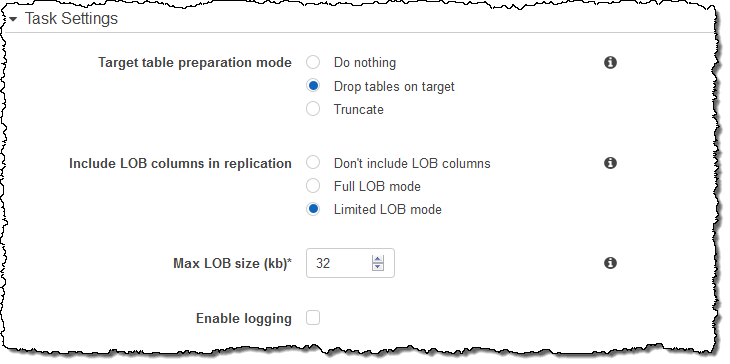
마이그레이션 작업을 위해, Start/Resume를 선택하면 됩니다.
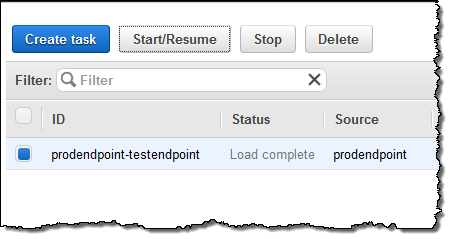
진행 사항을 보실 수 있으며, Table statistics를 통해 이전 사항을 확인할 수 있습니다. (아래 그림은 테스트 테이블입니다.)
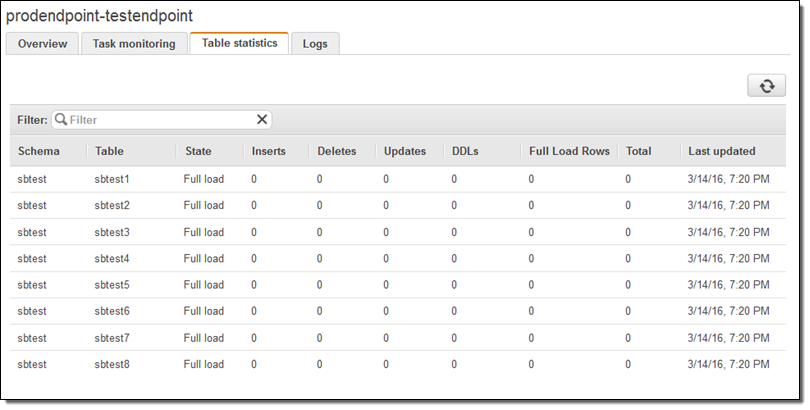
이전이 완료되면, 간단한 테스트를 거쳐 애플리케이션의 DB 엔드포인트를 변경 한 후 배포하시면 됩니다.
AWS Database Migration Service는 다양한 선택 사항을 제공합니다. 예를 들어, 특정 테이블만 옮긴다던지, 여러 개의 다른 리플리케이션 작업을 할 수도 있고, 시간에 따라 작업을 활성화 시킬 수도 있습니다. 좀 더 자세한 사항은 DMS 기술 문서 (영문)을 참고하시면 됩니다.
여러분이 다양한 데이터베이스 세트를 옮기신다면, AWS Command Line Interface (CLI)나 the Database Migration Service API를 활용하시길 권장합니다.
가격 및 출시 리전
AWS Database Migration Service는 현재 US East (Northern Virginia), US West (Oregon), US West (Northern California), Europe (Ireland), Europe (Frankfurt), Asia Pacific (Tokyo), Asia Pacific (Singapore), 및 Asia Pacific (Sydney) 리전에 우선 출시되었으며, 향후 빠른 시일 내에 (서울 리전을) 비롯한 다른 리전에 출시될 예정입니다.
— Jeff;
이 글은 AWS Database Migration Service의 한국어 번역입니다.